

As a substitute for Java Annotation Processing, Kotlin Foundation introduced the Kotlin Symbol Processing (KSP1) tool2, which works in a similar way but is faster, more modern, and is designed specifically for Kotlin. It makes it possible to define processors that analyze project code and generate files during project compilation. The key advantage of KSP is that it is native to Kotlin and works on all platforms and shared modules.
Kotlin Symbol Processing is similar in many ways to Java Annotation processing, but it offers many advantages and important improvements, including a more modern API. First of all, KSP understands Kotlin code, so we can properly implement support for Kotlin-specific features, like extensions or suspend functions, and it can also be used to process Java code. It can also freely use KotlinPoet instead of JavaPoet to generate Kotlin code. KSP references to code elements are more convenient to use, and their API is more modern and has more consistent naming. We rarely need to do dangerous down-castings; instead, we can rely on methods and properties. Finally, the KSP API is lazy3, which makes it generally faster than Annotation Processing. Compared to kapt, annotation processors that use KSP can run up to twice as fast because KSP is not slowed down by creating intermediate stub classes and Gradle javac tasks4.
The same as with Annotation Processing, we will explore KSP by implementing an example project.
To bring our discussion about KSP into the real world, let's implement the same library as in the previous chapter, but using KSP instead of Java Annotation Processing. So, we will generate an interface for a class that includes all the public methods of this class. This is the code we will use to test our solution:
@GenerateInterface("UserRepository") class MongoUserRepository<T> : UserRepository { override suspend fun findUser(userId: String): User? = TODO() override suspend fun findUsers(): List<User> = TODO() override suspend fun updateUser(user: User) { TODO() } @Throws(DuplicatedUserId::class) override suspend fun insertUser(user: User) { TODO() } } class FakeUserRepository : UserRepository { private var users = listOf<User>() override suspend fun findUser(userId: String): User? = users.find { it.id == userId } override suspend fun findUsers(): List<User> = users override suspend fun updateUser(user: User) { val oldUsers = users.filter { it.id == user.id } users = users - oldUsers + user } override suspend fun insertUser(user: User) { if (users.any { it.id == user.id }) { throw DuplicatedUserId } users = users + user } }
We want KSP to generate the following interface:
interface UserRepository { suspend fun findUser(userId: String): User? suspend fun findUsers(): List<User> suspend fun updateUser(user: User) @Throws(DuplicatedUserId::class) suspend fun insertUser(user: User) }
The complete project can be found on GitHub under the name MarcinMoskala/generateinterface-ksp.
To achieve this, in a separate module we need to define the KSP processor, which we’ll call
generateinterface-processor. We also need a module where we will define the annotation, which we’ll call generateinterface-annotations.We need to use these modules in the main module configuration5. The module with annotation should be attached like any other dependency. To use KSP in Kotlin, we should use the
ksp plugin. Assuming we use Gradle in our project, this is how we might define our main module dependency in newly created modules.// build.gradle.kts
plugins {
id("com.google.devtools.ksp")
// …
}
dependencies {
implementation(project(":annotations"))
ksp(project(":processor"))
// ...
}
If we distribute our solution as a library, we need to publish annotations and processors as separate packages.
Notice that, in the example above, KSP will not be used to test sources. For that, we also need to add the
kspTest configuration.// build.gradle.kts
plugins {
id("com.google.devtools.ksp")
}
dependencies {
implementation(project(":annotations"))
ksp(project(":processor"))
kspTest(project(":processor"))
// ...
}
In the
generateinterface-annotations module, all we need is a file with our annotation definition:package academy.kt import kotlin.annotation.AnnotationTarget.CLASS @Target(CLASS) annotation class GenerateInterface(val name: String)
In the
generateinterface-processor module below, we need to specify two classes. We need to specify the processor provider, a class that implements SymbolProcessorProvider and overrides the create function, which produces an instance of SymbolProcessor. Inside this method, we have access to the environment, which can be used to inject different tools into our processor. Both SymbolProcessorProvider and SymbolProcessor are represented as interfaces, which makes our processor simpler to unit test.class GenerateInterfaceProcessorProvider : SymbolProcessorProvider { override fun create( environment: SymbolProcessorEnvironment ): SymbolProcessor = GenerateInterfaceProcessor( codeGenerator = environment.codeGenerator, ) }
The processor provider needs to be specified in a special file called
com.google.devtools.ksp.processing.SymbolProcessorProvider, under the path src/main/resources/META-INF/services. Inside this file, you need to specify the processor provider using its fully qualified name:academy.kt.GenerateInterfaceProcessorProvider
Finally, we can implement our processor. The class representing the symbol processor must implement the
SymbolProcessor interface and override the single process function. The processor does not need to specify annotations or the language versions it supports. The process function needs to return a list of annotated elements, which I will explain later in this chapter in the Multiple round processing section. In this example, we will return an empty list.class GenerateInterfaceProcessor( private val codeGenerator: CodeGenerator, ) : SymbolProcessor { override fun process(resolver: Resolver): List<KSAnnotated> { // ... return emptyList() } }
The essential part of our processing is generating Kotlin files based on project analysis, for which we’ll use the KSP API and KotlinPoet. So, to find annotated classes and start interface generation for each of them, we first use a resolver, which is the entrypoint to the KSP API.
override fun process(resolver: Resolver): List<KSAnnotated> { resolver .getSymbolsWithAnnotation( GenerateInterface::class.qualifiedName!! ) .filterIsInstance<KSClassDeclaration>() .forEach(::generateInterface) return emptyList() } private fun generateInterface(annotatedClass: KSClassDeclaration){ // ... }
In
generateInterface, we first establish our interface name by finding the interface reference and reading its name.val interfaceName = annotatedClass .getAnnotationsByType(GenerateInterface::class) .single() .name
getAnnotationsByTypeneeds@OptIn(KspExperimental::class)annotation to work.
We use an annotated class package as our interface package.
val interfacePackage = annotatedClass .qualifiedName ?.getQualifier() .orEmpty()
In this chapter, I won’t explain how KSP models Kotlin because it is quite intuitive to those who understand programming nomenclature. It is also quite similar to how Kotlin Reflect models code elements. I could write a long section explaining all the classes, functions, and properties, but this would be useless. Who would want to remember all that? We only need knowledge about an API when we use it, and in this case it is much more convenient to read docs or to look for answers on Google. I believe that books should explain possibilities, potential traps, and ideas that are not easy to deduce.
To find public methods of a class reference, I needed to use the
getDeclaredFunctions method. The getAllFunctions method is not appropriate because we don’t want to include methods from class parents (like hashCode and equals from Any). I also needed to filter out constructors that are considered methods in Kotlinwell.val publicMethods = annotatedClass .getDeclaredFunctions() .filter { it.isPublic() && !it.isConstructor() }
Then I’ll use already defined variables to generate the interface and write it to a file using KotlinPoet. The dependencies object will be explained later in this chapter, in the Dependencies and incremental processing part.
val fileSpec = buildInterfaceFile( interfacePackage, interfaceName, publicMethods ) val dependencies = Dependencies( aggregating = false, annotatedClass.containingFile!! ) fileSpec.writeTo(codeGenerator, dependencies)
So, now let’s implement methods to build our interface. First, we define the
buildInterfaceFile method for building a file.private fun buildInterfaceFile( interfacePackage: String, interfaceName: String, publicMethods: Sequence<KSFunctionDeclaration>, ): FileSpec = FileSpec .builder(interfacePackage, interfaceName) .addType(buildInterface(interfaceName, publicMethods)) .build()
When we build an interface, we only need to specify its name and build functions. Note that the parameter representing public methods is a sequence, which is typical of KSP (most elements are lazy for efficiency), so we need to transform it to a list after we transform these methods.
private fun buildInterface( interfaceName: String, publicMethods: Sequence<KSFunctionDeclaration>, ): TypeSpec = TypeSpec .interfaceBuilder(interfaceName) .addFunctions( publicMethods .map(::buildInterfaceMethod).toList() ) .build()
The method for building methods’ definitions is a bit more complicated. To specify the function name, we need to use
getShortName. We’ll separately establish function modifiers, and we also have a separate function to map parameters. We use the same result type and the same annotations, but both need to be mapped to KotlinPoet objects.private fun buildInterfaceMethod( function: KSFunctionDeclaration, ): FunSpec = FunSpec .builder(function.simpleName.getShortName()) .addModifiers(buildFunctionModifiers(function.modifiers)) .addParameters( function.parameters.map(::buildInterfaceMethodParameter) ) .returns(function.returnType!!.toTypeName()) .addAnnotations( function.annotations .map { it.toAnnotationSpec() } .toList() ) .build()
There is no easy way to map the KSP value parameter to the KotlinPoet parameter specification, so we can specify a custom function that builds parameters with the same name, the same type, and the same annotations as the parameter reference.
private fun buildInterfaceMethodParameter( variableElement: KSValueParameter, ): ParameterSpec = ParameterSpec .builder( variableElement.name!!.getShortName(), variableElement.type.toTypeName(), ) .addAnnotations( variableElement.annotations .map { it.toAnnotationSpec() }.toList() ) .build()
Regarding modifiers, mapping them is easy but we need to add the
abstract modifier, and we should ignore the override and open parameters as the former is not allowed in interfaces, while the latter is simply redundant in interfaces.private fun buildFunctionModifiers( modifiers: Set<Modifier> ) = modifiers .filterNot { it in IGNORED_MODIFIERS } .plus(Modifier.ABSTRACT) .mapNotNull { it.toKModifier() } companion object { val IGNORED_MODIFIERS = listOf(Modifier.OPEN, Modifier.OVERRIDE) }
The files generated as a result of KSP processing can be found under the path "build/generated/ksp/main/kotlin". These files will be packed and distributed with the build result (like jar or apk). Since KSP version 1.8.10-1.0.9, generated Kotlin code is treated like a part of our project source set, so generated elements are visible in IntelliJ and can be directly used in our project code.
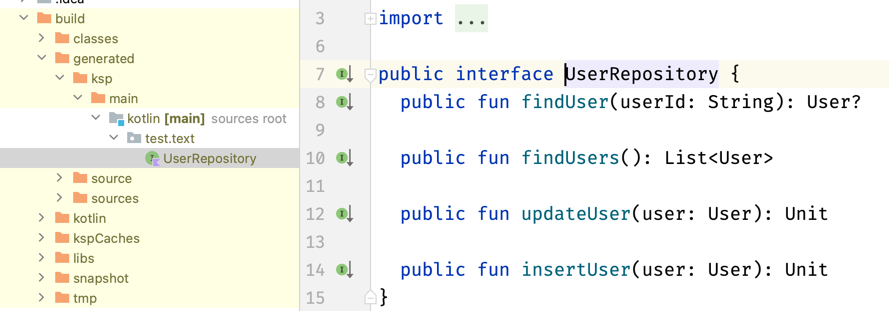
Thanks to the fact that classes like
CodeGenerator are represented with interfaces in KSP, we can easily make their fakes and implement unit tests for our processors. However, there are also ways to verify the complete compilation result, together with logged messages and generated files.Currently, the most popular library for verifying KSP compilation results is Kotlin Compile Testing, which is used by many popular libraries, like Room, Dagger or Moshi. We use this library to set up a compilation environment, compile the code, and verify the results of this process. To this compilation environment, we can attach any number of annotation processors, KSP providers, or compiler plugins.
For our example project, I will set up a compilation with our
GenerateInterfaceProcessorProvider provider and test the source code, compile it, and confirm that it is as expected. This is the function I defined for that:private fun assertGeneratedFile( sourceFileName: String, @Language("kotlin") source: String, generatedResultFileName: String, @Language("kotlin") generatedSource: String ) { val compilation = KotlinCompilation().apply { inheritClassPath = true kspWithCompilation = true sources = listOf( SourceFile.kotlin(sourceFileName, source) ) symbolProcessorProviders = listOf( GenerateInterfaceProcessorProvider() ) } val result = compilation.compile() assertEquals(OK, result.exitCode) val generated = File( compilation.kspSourcesDir, "kotlin/$generatedResultFileName" ) assertEquals( generatedSource.trimIndent(), generated.readText().trimIndent() ) }
With such a function, I can easily verify that the code I expect to be generated for a specific annotated class is correct:
class GenerateInterfaceProcessorTest { @Test fun `should generate interface for simple class`() { assertGeneratedFile( sourceFileName = "RealTestRepository.kt", source = """ import academy.kt.GenerateInterface @GenerateInterface("TestRepository") class RealTestRepository { fun a(i: Int): String = TODO() private fun b() {} } """, generatedResultFileName = "TestRepository.kt", generatedSource = """ import kotlin.Int import kotlin.String public interface TestRepository { public fun a(i: Int): String } """ ) } // ... }
Instead of reading the result file and comparing its content, we could also load the generated class and analyze it using reflection.
Kotlin’s Compile Testing library is also used to verify that code that incorrectly uses annotations fails with a specific message.
class GenerateInterfaceProcessorTest { // ... @Test fun `should fail when incorrect name`() { assertFailsWithMessage( sourceFileName = "RealTestRepository.kt", source = """ import academy.kt.GenerateInterface @GenerateInterface("") class RealTestRepository { fun a(i: Int): String = TODO() private fun b() {} } """, message = "Interface name cannot be empty" ) } // ... }
File generation takes time, so various mechanisms have been introduced to improve the efficiency of this process. A very important one is incremental processing, which is based on a simple idea. When our project is compiled for the first time, it should process elements from all files. If we compile it again, it should only process elements from files that have changed.
So, in our GenerateInterface example, consider that you have class
A in file A.kt and class B in file B.kt, both annotated with GenerateInterface.// A.kt @GenerateInterface("IA") class A { fun a() } // B.kt @GenerateInterface("IB") class B { fun b() }
Incremental processing is enabled by default, so when you compile your project for the first time,
GenerateInterfaceProcessor will generate both IA.kt and IB.kt. When you compile your project again without making any changes in A.kt or B.kt, GenerateInterfaceProcessor will not generate any files. If you make a small change in A.kt, like adding a space, and you compile your project again, only IA.kt will be generated again and will replace the previous IA.kt.Incremental processing is a very powerful mechanism that works nearly effortlessly, but we should understand it if we want to avoid mistakes that could make our libraries work incorrectly.
To know which files need to be reprocessed, KSP introduced the concept of dirtiness. A dirty file is a file that needs to be reprocessed. When a processor is started, the resolver methods
getSymbolsWithAnnotation and getAllFiles will only return files and elements from files that are considered dirty.Resolver::getAllFiles- returns only dirty file references.Resolver::getSymbolsWithAnnotation- returns only symbols from dirty files.
Most other resolver methods, like
getDeclarationsFromPackage or getClassDeclarationByName, will still return all files; however, when we determine which symbols to process, we typically base them on getAllFiles and getSymbolsWithAnnotation.So now, how does a file become dirty, and how does it become clean? The situation is simple in our project: for each input file, we generate one output file. So, when the input file is changed, it becomes dirty. When the corresponding output file is generated for it, the input file becomes clean. However, things can get much more complex. We can generate multiple output files from one input file, or multiple input files might be used to generate one output file, or one output file might depend on other output files.
Consider a situation where a generated file is based not only on the annotated element but also on its parent. So, if this parent changes, the file should be reprocessed.
// A.kt @GenerateInterface open class A { // ... } // B.kt class B : A() { // ... }
To determine which sources need to be reprocessed, KSP needs help from processors to identify which input sources correspond to which generated outputs. More concretely, whenever a new file is created, we must specify dependencies. For this, we use the
Dependencies class, which lets us specify the aggregating parameter and then any number of file dependencies. In our example processor, we specified that the generated file depends only on the file containing the annotated class used to generate this file.val dependencies = Dependencies( aggregating = false, annotatedClass.containingFile!! ) val file = codeGenerator.createNewFile( dependencies, packageName, fileName )
If we want to make this file depend on other files as well, such as the files containing the parents of the annotated class, we would need to define them explicitly. The
Dependencies class allows vararg arguments of type KSFile.fun classWithParents( classDeclaration: KSClassDeclaration ): List<KSClassDeclaration> = classDeclaration .superTypes .map { it.resolve().declaration } .filterIsInstance<KSClassDeclaration>() .flatMap { classWithParents(it) } .toList() .plus(classDeclaration) val dependencies = Dependencies( aggregating = ann.dependsOn.isNotEmpty(), *classWithParents(annotatedClass) .mapNotNull { it.containingFile } .toTypedArray() )
File dependencies are used to:
- Determine that a file not associated with any existing file should be removed.
- Determine which files should be considered dirty.
By rule, if any input file of an output file becomes dirty, all the other dependencies of this output file become dirty too. This relationship is transitive. Consider the following scenario:
If the output file
OA.kt depends on A.kt and B.kt, then:- A change in
A.ktmakesA.ktandB.ktdirty. - A change in
B.ktmakesB.ktandA.ktdirty.
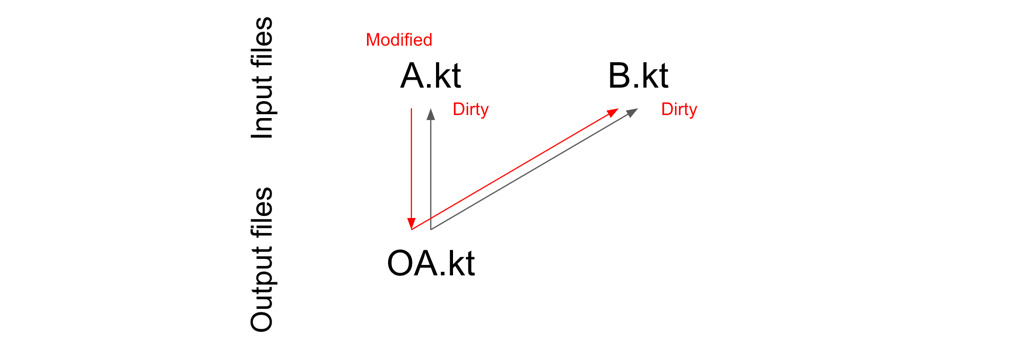
If we change
A.kt , then both A.kt and B.kt become dirty.If
OA.kt depends on A.kt and B.kt, and OB.kt depends on B.kt and C.kt, and OD.kt depends on D.kt and E.kt, then:- A change in
A.ktmakesA.kt,B.kt, andC.ktdirty. - A change in
B.ktmakesA.kt,B.kt, andC.ktdirty. - A change in
C.ktmakesA.kt,B.kt, andC.ktdirty. - A change in
D.ktmakesD.ktandE.ktdirty. - A change in
E.ktmakesD.ktandE.ktdirty.
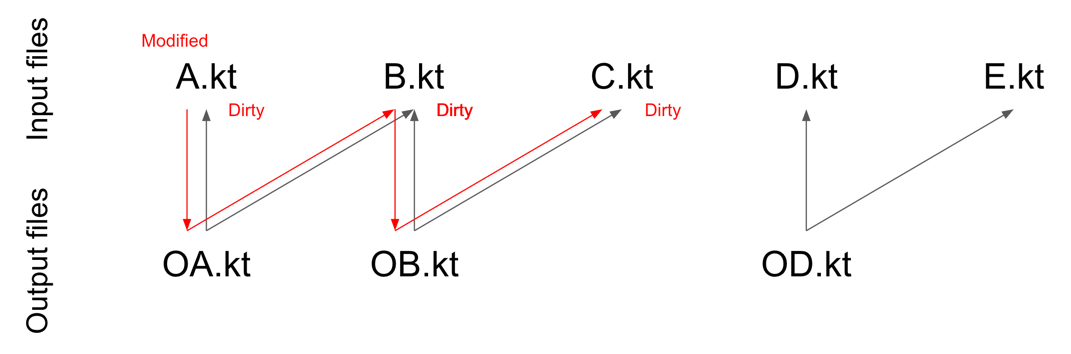
A change in
A.kt makes A.kt, B.kt, and C.kt dirty.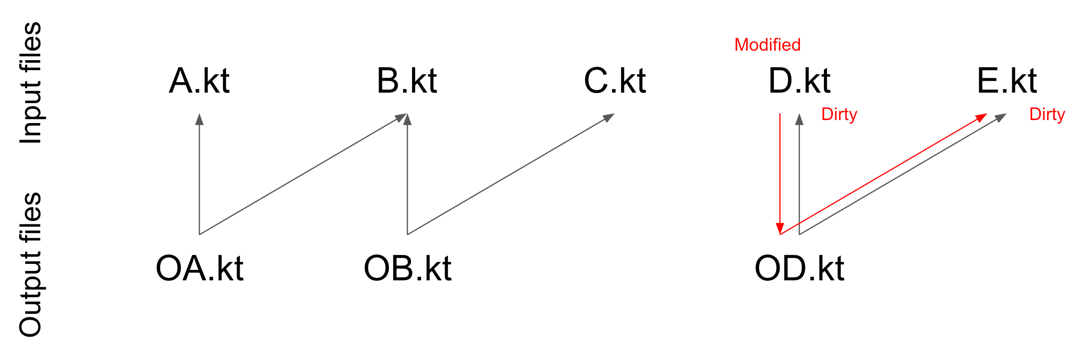
A change in
D.kt makes D.kt and E.kt dirty.As you can see, making dependencies leads to more files being considered dirty; as a result, more files are reprocessed. However, consider files that use all other processing results or collect all annotated elements. Such files are called aggregating and set the
aggregating flag to true in their dependency. An aggregating output can potentially be affected by any input changes. All input files that are associated with aggregating outputs will be reprocessed. Consider the following scenario:If
OA.kt depends on A.kt, and OB.kt depends on B.kt, and OC.kt is aggregating and depends on C.kt and D.kt, then:- A change in
A.ktmakesA.kt,C.kt, andD.ktdirty. - A change in
B.ktmakesB.kt,C.kt, andD.ktdirty. - A change in
C.ktmakesC.ktandD.ktdirty. - A change in
D.ktmakesC.ktandD.ktdirty.
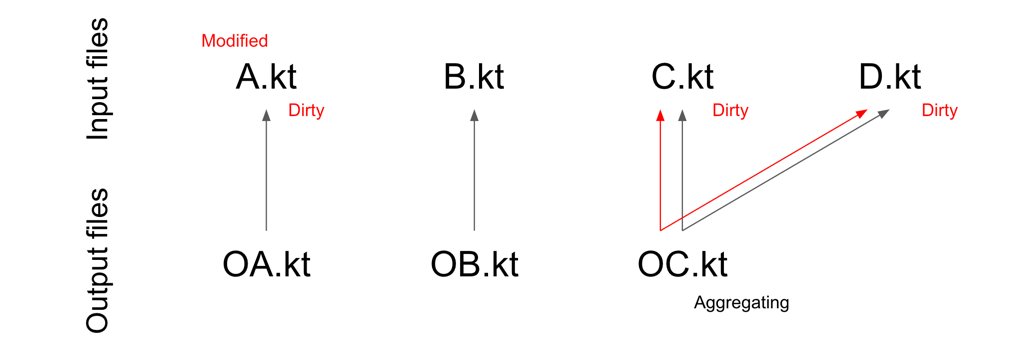
A change in
A.kt makes A.kt, C.kt and D.kt dirty.It might seem complicated, but using incremental processing is quite simple. In most cases, we set
aggregating to false (so we set this file as isolating), and we depend on the file used to generate this output file, which is typically the file that includes this annotated element.val dependencies = Dependencies( aggregating = false, annotatedClass.containingFile!! ) val file = codeGenerator.createNewFile( dependencies, packageName, fileName )
If we base our file generation on other files, we should also list them as dependencies. Files that depend on multiple other files should be set as aggregating, but remember that dependencies of aggregating files become dirty when any file changes.
KSP supports multiple rounds processing mode, which means that the same
process function can be called multiple times if needed. For instance, let's say that you implement a simple Dependency Injection Framework and you use KSP to generate classes that create objects. Consider that you have the following classes:@Single class UserRepository { // ... } @Provide class UserService( val userRepository: UserRepository ) { // ... }
You want your KSP processor to generate the following providers:
class UserRepositoryProvider : SingleProvider<UserRepository>() { private val instance = UserRepository() override fun single(): UserRepository = instance } class UserServiceProvider : Provider<UserService>() { private val userRepositoryProvider = UserRepositoryProvider() override fun provide(): UserService = UserService(userRepositoryProvider.single()) }
The problem is that
UserServiceProvider depends on UserRepositoryProvider, which is also created using our processor. To generate UserServiceProvider, we need to reference the class generated for UserRepositoryProvider; for that, we need to generate UserRepositoryProvider in the first round, and UserServiceProvider in the second round. How do we achieve that? From process, we need to return a list of annotated elements that could not be generated but that we want to try to generate in the next round. In the next round, getSymbolsWithAnnotation from Resolver will only return elements that were not generated in the previous round. This way, we can have multiple rounds of processing to resolve deferred symbols.class ProviderGenerator( private val codeGenerator: CodeGenerator, ) : SymbolProcessor { override fun process(resolver: Resolver): List<KSAnnotated> { val provideSymbols = resolver.getSymbolsWithAnnotation( Provide::class.qualifiedName!! ) val singleSymbols = resolver.getSymbolsWithAnnotation( Single::class.qualifiedName!! ) val symbols = (singleSymbols + provideSymbols) .filterIsInstance<KSClassDeclaration>() val notProcessed = symbols .filterNot(::generateProvider) return notProcessed.toList() } // ... }
In our example, we cannot generate both classes during the first round because
UserRepositoryProvider is not available then. Instead, we should first generate UserServiceProvider and then UserRepositoryProvider in the second round. Multiple rounds of processing are useful when processor execution depends on elements that might be generated by this or another processor.A simplified example of this use-case is presented on my GitHub repository MarcinMoskala/DependencyInjection-KSP.
We can use KSP on multiplatform projects, but the build configuration is different. Instead of using
ksp in the dependencies block for a specific compilation target, we define a special dependencies block at the top-level. Inside it, we specify which targets we should use a specific processor for.plugins {
kotlin("multiplatform")
id("com.google.devtools.ksp")
}
kotlin {
jvm {
withJava()
}
linuxX64() {
binaries {
executable()
}
}
sourceSets {
val commonMain by getting
val linuxX64Main by getting
val linuxX64Test by getting
}
}
dependencies {
add("kspCommonMainMetadata", project(":test-processor"))
add("kspJvm", project(":test-processor"))
add("kspJvmTest", project(":test-processor"))
// Doing nothing, because there's no such test source set
add("kspLinuxX64Test", project(":test-processor"))
// kspLinuxX64 source set will not be processed
}
KSP is a powerful tool that programming libraries can use to generate code based on annotations or our own definitions. This capability is already used by many libraries that make our life easier, like Room or Dagger. KSP is faster than Java Annotation Processing, it understands Kotlin better, and it can be used on multiplatform projects. You will find this knowledge useful to implement some amazing libraries, or it will help you better understand and work with the libraries you use.
The biggest limitation of KSP is that it can only generate files and cannot change how existing code behaves, but in the next chapter, you will learn about Kotlin’s Compiler Plugin, which can change how your code behaves.
- Not to be confused with Kerbal Space Program. ↩
- KSP has been developed since 2021 by Google, which is a Kotlin Foundation member. ↩
- For KSP, lazy means the API is designed to initially provide references instead of concrete types. These references are resolved to a code element when actually needed. ↩
- According to KSP documentation. ↩
- By "main module", I mean the module that will use KSP processing. ↩



