

Persistent memory is non-volatile1 storage that fits in a standard DIMM2 slot. Persistent memory provides higher throughput than SSD and NVMe3 but is slower than DRAM4. With persistent memory, memory contents remain even when system power goes down in the event of an unexpected power loss, user-initiated shutdown, or system crash.

Intel Optane (Persistent memory)
Compared to DRAM, persistent memory modules come in much larger capacities and are less expensive per GiB5, however they are still more expensive than NVMe.
Persistent Memory (PMEM), also referred to as Non-Volatile Memory (NVM), or Storage Class Memory (SCM), provides a new entry in the memory-storage hierarchy that fills the performance/capacity gap.
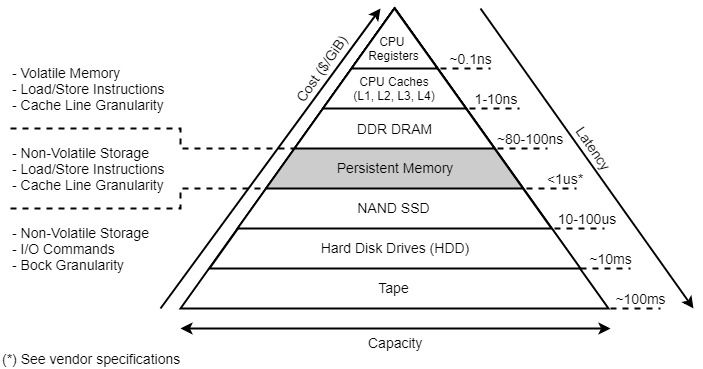
Storage hierarchy
The above image highlights the following:
- Latency offered by persistent memory is higher than that of DRAM but lower than that of NAND SDDs or HDDs
- Cost per GiB of persistent memory is lower than that of DRAM but higher than that of NAND SDDs or HDDs
With persistent memory, applications have a new tier available for data placement. Applications can access persistent memory as they do with traditional memory, eliminating the need to page blocks of data back and forth between memory and storage.
- Persistent memory is durable, unlike DRAM. Its endurance is higher and should exceed the lifetime of the server without wearing out.
- Latency of persistent memory is much better than NAND but potentially slower than DRAM.
- Persistent memory is byte-addressable like memory. Applications can update only the data needed without any read-modify-write overhead which is incurred while doing block IO.
- Data written to persistent memory is not lost when power is removed.
- After permission checks are completed, data located on persistent memory is directly accessible from userspace.
Let's assume a key/value storage engine on a block device like HDD.
When an application wants to fetch a value from the key/value storage engine, it must do the following:
- read the entire block or page containing the value from the disk,
- allocate a buffer to hold the result.
Even while making a small update say, 128 bytes, the application needs to do the following:
- read the entire block containing those 128 bytes into a memory buffer,
- update 128 bytes in the buffer,
- write the entire block to the disk.
Block IO involves transferring an entire block of data, typically 4K bytes at a time. So the task to update 128 bytes requires reading 4K bytes of block and then writing back 4K bytes.
Let's consider the same key/value store on persistent memory.
With the persistent memory key/value storage engine, values are accessed by the application directly. There is no need to allocate buffers in memory. Contrary to block storage applications, an application on persistent memory would only read the amount of data necessary.
Even the writes are not required to be aligned at the block boundaries. Applications can read or write as much or as little as possible. This improves performance and reduces memory footprint overheads.
Memory mapping allows accessing a file as if it was entirely loaded in memory.
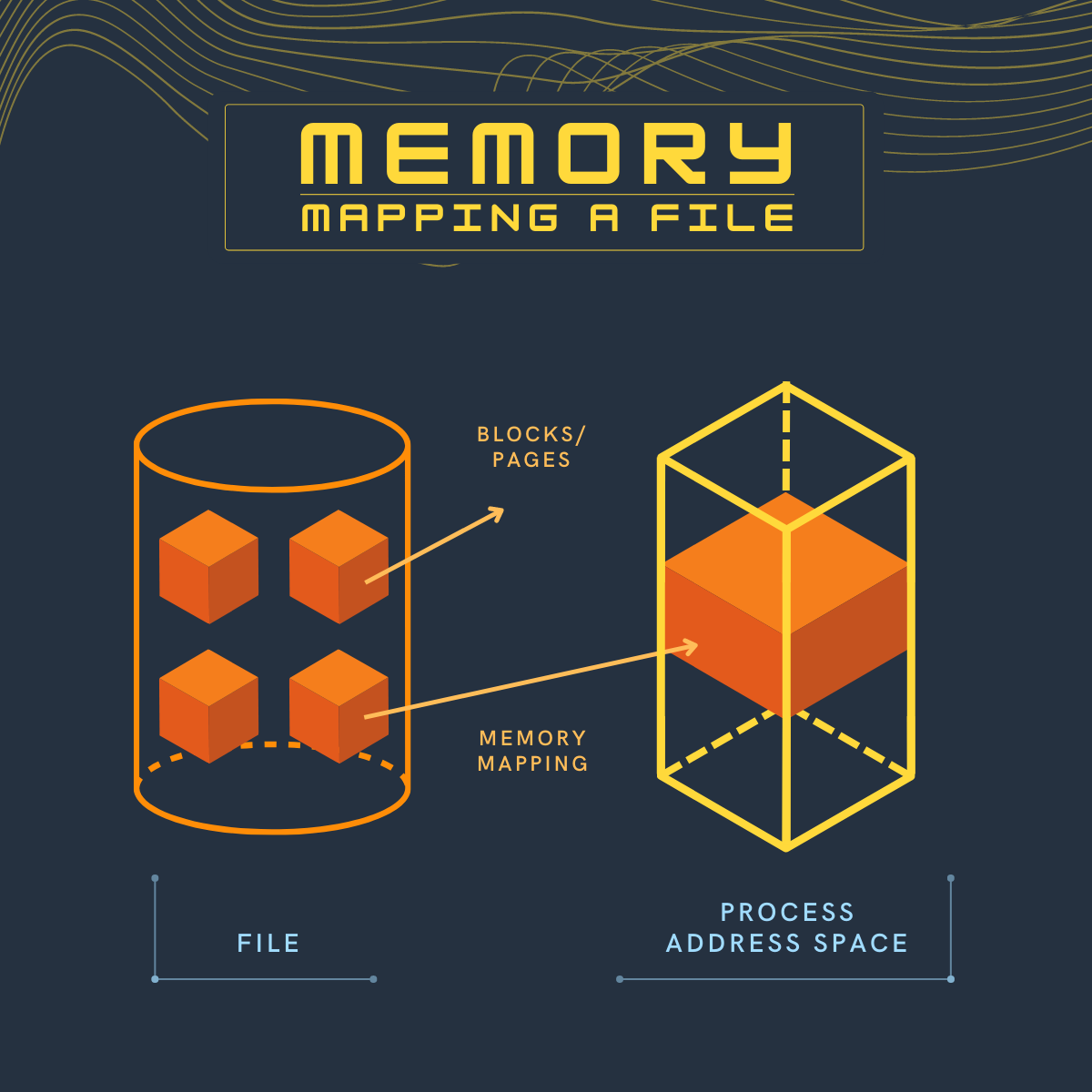
Memory mapping
With memory mapping, the operating system adds a range to the application’s virtual address space which corresponds to a range of the file, paging file data into physical memory as required. This allows an application to access and modify file data as byte-addressable in-memory data structures.
With memory mapping, file contents are not loaded eagerly, unless specified. During the first read/write operation, a page fault is issued which triggers the kernel to load the requested page into the main memory.
When the application reads from a file at a specific file offset, the kernel gets involved and if the page corresponding to that file offset is not already loaded, a page fault is triggered. Page fault results in loading the corresponding page from the disk and mapping it to the application address space.
When the application writes back to a page, it will be up to the kernel when to write the pages back to disk or the application can invoke
msync call.The operating system needs a couple of extensions when dealing with persistent memory.
The first operating system extension for persistent memory is the ability to detect the existence of persistent memory modules and load a device driver into the operating system’s I/O subsystem. The NVDIMM driver presents persistent memory to the applications and operating system modules as a fast block storage device. This means applications, file systems, volume managers, and other storage middleware layers can use persistent memory the same way they use storage today, without modifications.
Some storage devices, especially NVM Express SSDs, provide a guarantee that when a power failure or server failure occurs while a block write is in-flight, either all or none of the block will be written. The BTT driver provides the same guarantee when using persistent memory as a block storage device.
The next extension to the operating system is to make the file system aware of and be optimized for persistent memory. File systems that have been extended for persistent memory include Linux ext4 and XFS, and Microsoft Windows NTFS. These file systems can either use the block driver in the I/O subsystem or bypass the I/O subsystem to directly use persistent memory as byte-addressable load/store memory as the fastest and shortest path to data stored in persistent memory. In addition to eliminating the I/O operation, this path enables small data writes to be executed faster than traditional block storage devices that require the file system to read the device’s native block size, modify the block, and then write the full block back to the device.
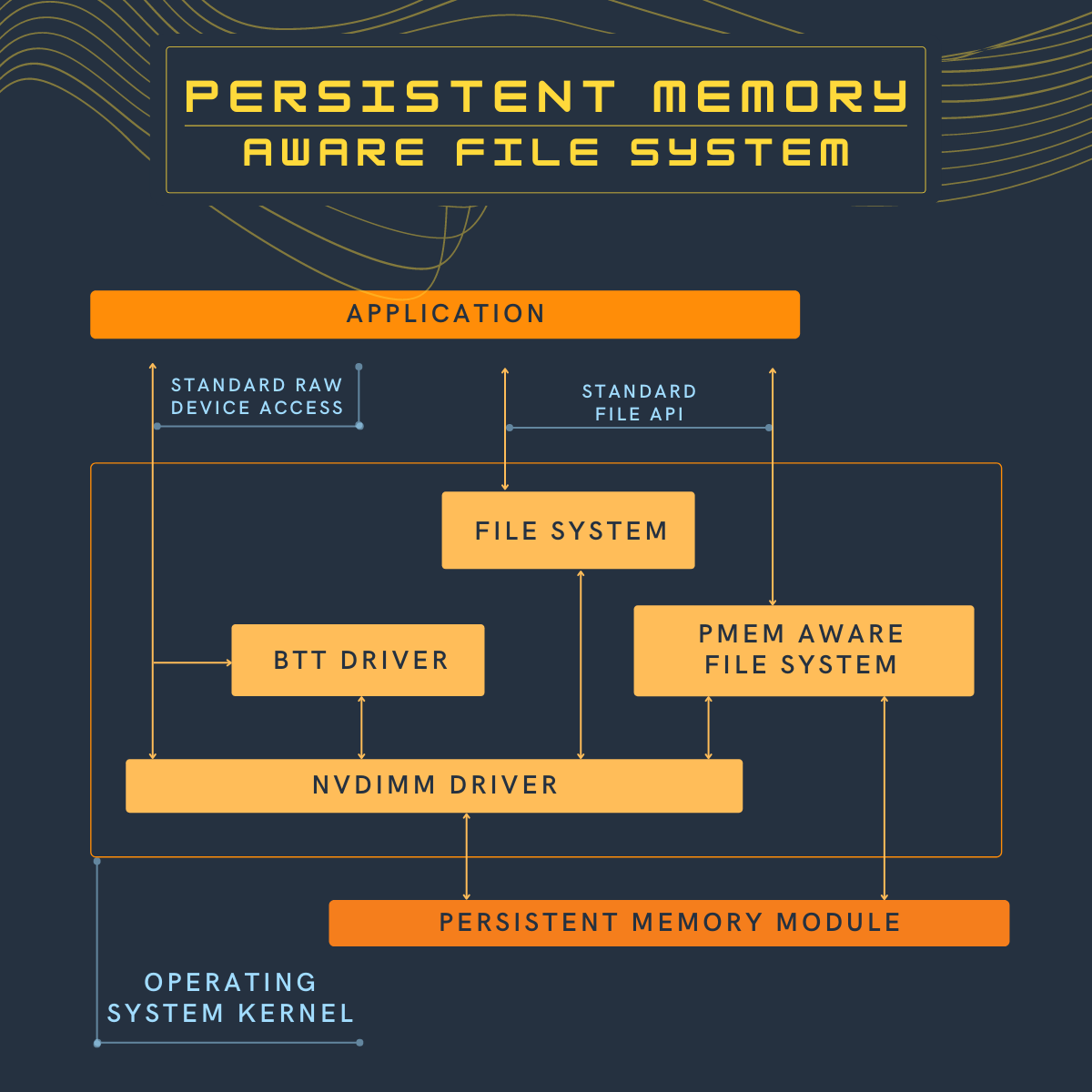
Pmem aware file system
The persistent memory direct access feature in operating systems, referred to as DAX in Linux and Windows, uses the memory-mapped file interfaces but takes the advantage of persistent memory’s native ability to both store data and be used as memory.
Persistent memory can be natively mapped as application memory, eliminating the need for the operating system to cache files in volatile main memory.
A persistent memory-aware file system recognizes that the file is on persistent memory and programs the memory management unit (MMU) in the CPU to map the persistent memory directly into the application’s address space. Neither a copy in kernel memory nor synchronizing to storage through I/O operations is required. The application can use the pointer returned by
mmap() to operate on its data in place directly in the persistent memory. Since no kernel I/O operations are required, and because the full file is mapped into the application’s memory, it can manipulate large collections of data objects with higher and more consistent performance as compared to files on I/O-accessed storage.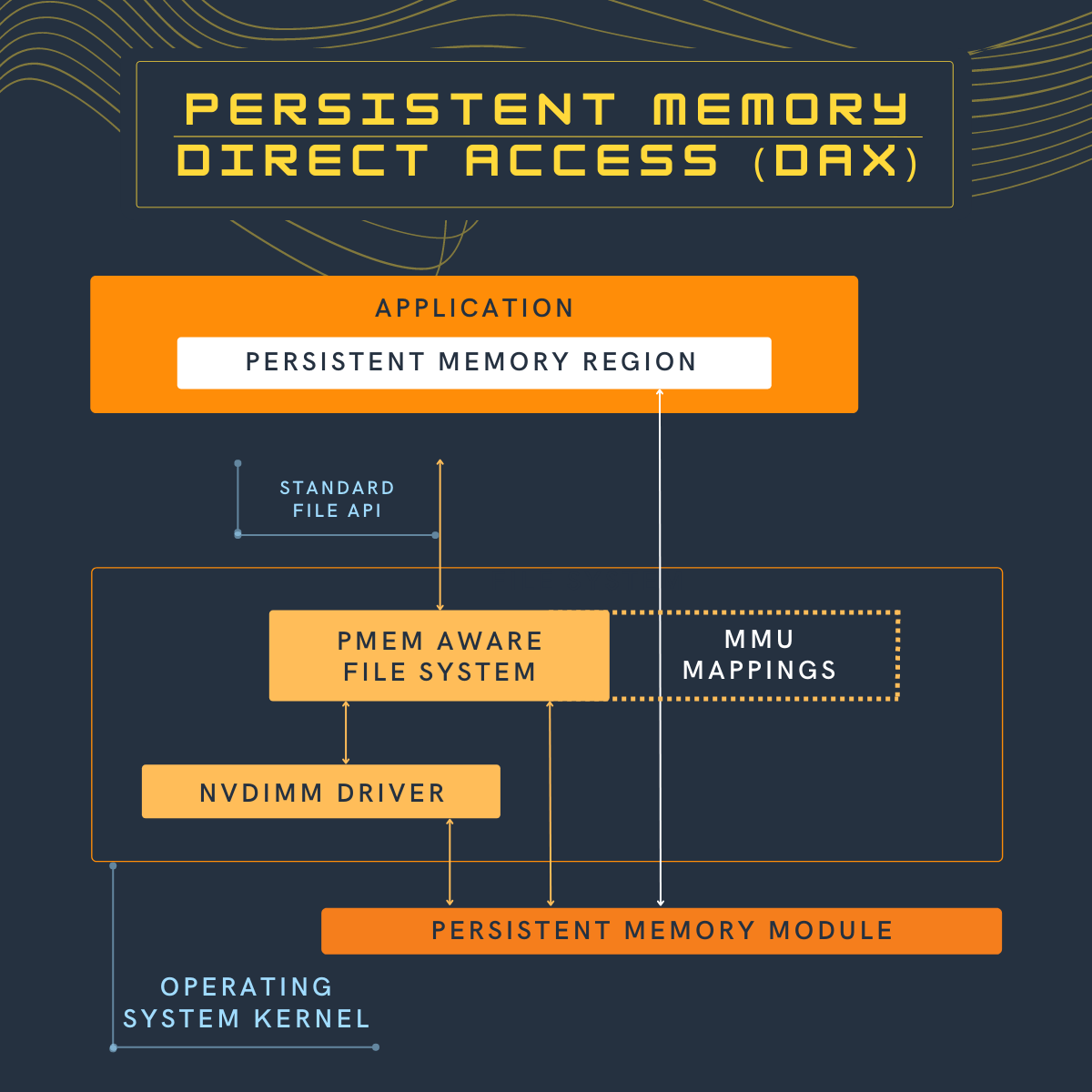
Direct Access
Word addressable
A memory word represents the number of bytes that a bidirectional data bus can carry at a time.
Let's consider a 32-bit machine where the size of the data bus is 32 bits. This means that the CPU on such machines can read or write 32 bits (4 bytes) of data at a time from the main memory. A reference to address 0 will read/write the first 4 bytes of main memory that is bytes 0 to bytes 3. Similarly, address 1 will fetch bytes 4 to 7 and so on. Such memory is called word addressable.
Byte Addressable
Memory is said to be byte-addressable when the CPU fetches 1 byte at a time from the main memory irrespective of the size of the data bus.
Block IO involves transferring an entire block of data, typically 4K bytes at a time for reading or writing. Let's say an application wants to read 64 bytes of data. With block IO, an entire block (or page of size 4K bytes) containing those 64 bytes needs to be read.
With byte addressability of persistent memory, applications can read and write at a byte level. Reads/writes need not be aligned at block boundaries. This effectively means that applications can read or write as much or as little as required. This improves performance and reduces memory footprint overheads.
Byte addressability also means that any in-memory data structure (Stack/Queue/Trie/Binary search tree etc.) can be designed to work with persistent memory.
Is persistent memory separate hardware?
Yes, persistent memory is separate hardware installed on the memory bus. Take a look at Intel Optane Persistent Memory
Any in-memory data structure can be designed to work with persistent memory. Why is this idea useful?
Being able to use an in-memory data structure to work with persistent memory has a lot of positives. Let's assume that we are designing a key/value storage engine for persistent memory and we choose Skiplist as the data structure for storing our data. We can approach this problem statement by breaking it into 2 steps -
- Design the in-memory data structure with selected behaviors like put and get.
- Make changes to the in-memory data structure to work with persistent memory.
If we are designing a storage engine for the first time, this approach takes away the anxiety. Step-1 does not focus on storage at all, it only focuses on the design of the data structure. Once step-1 is over, we start to make changes in the data structure to put it on persistent memory. This step focuses only on storage.
Another example could be WAL. Let's assume that we are designing a key/value storage engine for persistent memory and as a part of it we would like to implement a write-ahead log. A write-ahead log is an append-only log that stores all the commands. One of the simplest data structures for implementing a write-ahead log on persistent memory could be a linked list. Let's take a look at the pseudo implementation:
void KvStore::put(std::string key, std::string value) { /** 1. Create a WriteAheadLogEntry 2. Write the entry in WAL 3. Write the key/value pair in the storage data structure **/ } void WAL::write(WriteAheadLogEntry entry) { /** 1. Create a new linked list node 2. Write an entry into the new node 3. Add the new node to the tail of the linked list (tail -> next = newNode) 4. Flush the change **/ }
This example assumes that the linked list is stored on persistent memory.
Storage hierarchy shows that the "latency offered by persistent memory is higher than that of DRAM". Is there a way to leverage RAM and persistent memory at the same time?
Yes. There are two ways to design a data structure for storing the data with persistent memory - Full persistence and Selective persistence. The idea behind selective persistence is to have some part of the data structure in RAM and the rest in persistent memory. This design choice gives the best of RAM and persistent memory as we might be able to perform READ operations from RAM and writes will happen both in RAM and persistent memory, thus making our writes non-volatile.
Which operating systems are compatible with Intel Optane persistent memory
Here is a list of compatible operating systems for Intel Optane persistent memory.
What are some of the potential use-cases of persistent memory
Persistent memory has a lot of use-cases and some of these are mentioned in the article Persistent memory design choices and use-cases. Persistent memory offers higher throughput and lower latency than SSDs. This effectively means that in the design of a database, persistent memory can be used to store database indexes.
Database indexes speed up the read operations against a table or a document. A database index is implemented using a read efficient data structure and one of the common data structures is a B+Tree.
Since a database index is meant to speed up a read operation, it is therefore expected to offer the minimum read latency possible. Since persistent memory offers latency lesser than that of SDDs or HDDs, we can implement a database index (say, using a B+Tree) on persistent memory to get the reduced read latency.
If a database index is placed on a block device, every read/write operation would transfer an entire block of data between the application and the underlying block storage device. Typical block sizes are 512, 1024, 2048 and 4096 bytes.
With byte-addressability of persistent memory, reads/writes do not involve block transfer. Database indexes (or B+Trees) can be stored on persistent memory and each B+Tree node can be read or written to without aligning to the block boundaries.
- Persistent Memory
- Storage hierarchy
- Word addressable Vs Byte addressable
- Memory mapping
- Memory mapping
- Memory mapping
- Byte level access of persistent memory
-
Programming Persistent Memory
- What makes persistent memory different from block storage devices (Chapter 1)
- Characteristics of persistent memory (Chapter 2)
- How persistent memory works (Chapter 3)
- Non-volatile storage is a type of storage that can retain the stored information even after power is off. ↩
- DIMM (dual in-line memory module) is a module that can be found on the motherboard. The module has slots that contain one or more RAM chips found on a smaller part of the entire motherboard of your computer. Basically, the DIMM slots serve as your computer’s main memory storage unit as it houses the RAM chips. ↩
- NVMe (nonvolatile memory express) is a storage access and transport protocol for flash and solid-state drives (SSDs). To help deliver a high-bandwidth and low-latency user experience, the NVMe protocol accesses flash storage via a PCI Express (PCIe) bus, which supports tens of thousands of parallel command queues and thus is much faster than hard disks and traditional all-flash architectures, which are limited to a single command queue. ↩
- DRAM (dynamic random access memory) is volatile memory that stores bits of data in transistors. This memory is located closer to the processor, too, so the computer can easily and quickly access it for all the processes. ↩
- GiB stands for Gibibyte and 1 GiB is defined as 1024*1024*1024 bytes. ↩

