

Persistent memory is non-volatile1 storage that fits in a standard DIMM2 slot. Persistent memory provides higher throughput than SSD and NVMe3 but is slower than DRAM4. With persistent memory, memory contents remain even when system power goes down in the event of an unexpected power loss, user-initiated shutdown, or system crash.
I find persistent memory very interesting because it creates a huge opportunity to make any in-memory data structure persistent with minimal changes.
As a part of this article we would like to answer a couple of questions:
- What are some design choices with persistent memory? Is the entire data structure supposed to be on persistent memory or can some part of the data structure stay in RAM, while the rest stay in persistent memory?
- What are some use-cases of persistent memory?
There are two ways to design a data structure for storing the data with persistent memory.
Full persistence
The idea behind full persistence is to have the entire data structure on persistent memory. Our persistent dictionary uses the full persistence approach for its trie data structure. All the trie nodes are in persistent memory, and any access to the trie nodes accesses persistent memory.
Selective persistence
The idea behind selective persistence is to have some part of the data structure in RAM and the rest in persistent memory. This design choice gives the best of RAM and persistent memory as we might be able to perform READ operations from RAM and writes will happen both in RAM and persistent memory, thus making our writes non-volatile.
Let's consider a Node class with an integer value and a public constructor.
class Node { private: int value; public: Node(int value) }
We can create a new instance of
Node and assign some value by invoking the following code:Node* node = new Node(10);
This will allocate the required memory in RAM for the
Node object and assign value 10 to it. This is a simple way to write an object in RAM.Let's consider that we wish to write an instance of the
Node class to HDD. The following pseudocode demonstrates the steps that are needed to write a Node instance to the disk.void writeToDisk(Node node) { ofstream file; file.open("disk.log"); //serialize node to char* and write the serialized data to the file outfile << data << endl; }
Let's take a look at selective persistence with an example.
Let's assume that we are building a key/value storage engine for persistent memory and skiplist is the chosen data structure.
A skiplist is a layered data structure where the lowest layer is an ordinary ordered linked list. Each higher layer acts as an "express lane" for the lists below. Searching proceeds downwards from the top until consecutive elements bracketing the search element are found.
SkipList can be represented with the following structure:
class SkipList { private: Node* header; int level; } class Node { private: int key; int value; std::vector<Node*> right; }
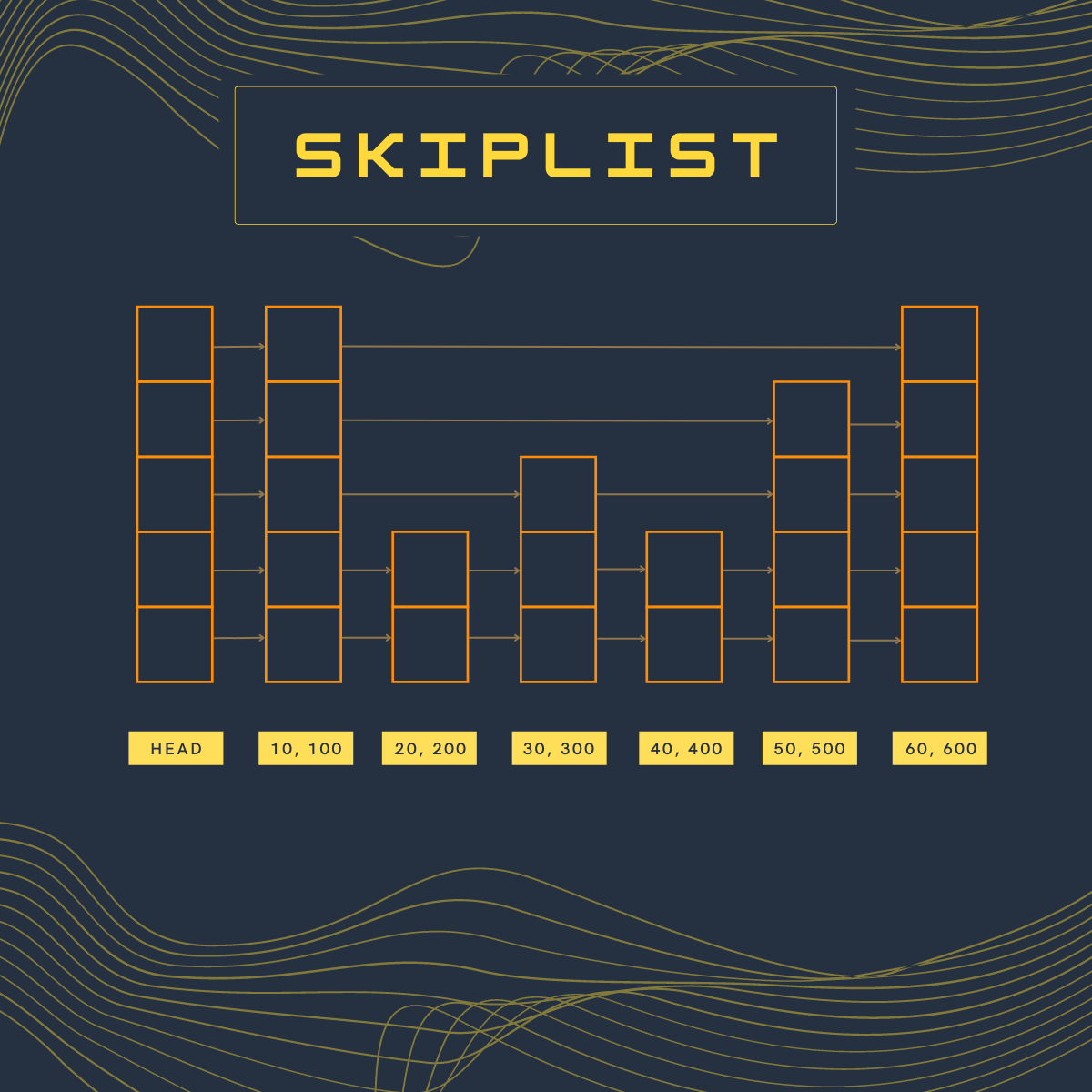
SkipList class contains a reference to a header node and each skiplist node contains a key/value pair along with a vector of right pointers. The header node is the starting node for all the read/write operations and all the key/value pairs will be added to its right.
One of the ways to ensure that all the key/value pairs are added to the right is to create a header node with some sentinel key/value pair when skiplist is instantiated. If we are creating a skiplist to store positive keys, then the sentinel value for the key in the header node can be -1. Similarly, if we are creating a skiplist to store string keys, then the sentinel value for the key in the header node can be blank.
Skiplist
The above image is the representation of our skiplist class.
Let's say we want to search key 25. The following would be the approach:
- Start with the header node and keep moving towards the right until the right key is greater than the search key
- Right of the header node, at the highest level is 10 which is less than 25, so move right
- Right of the node containing key 10 is 60 (at the highest level), which is greater than 25. So move to the lower level on the same node. Keep moving down until the right node contains a key that is less than or equal to the search key
- Finally, we will get down to level 1 (index starting from 0) on the node containing key 10. Right of this level contains 20, so move right
- Right of the node containing key 20 is 30 which is greater than the search key. So move to the lower level on the same node.
- Right of level 0 on the node containing key 20 is still 30. There are no more levels to go down to. So, key 25 is not present in the list
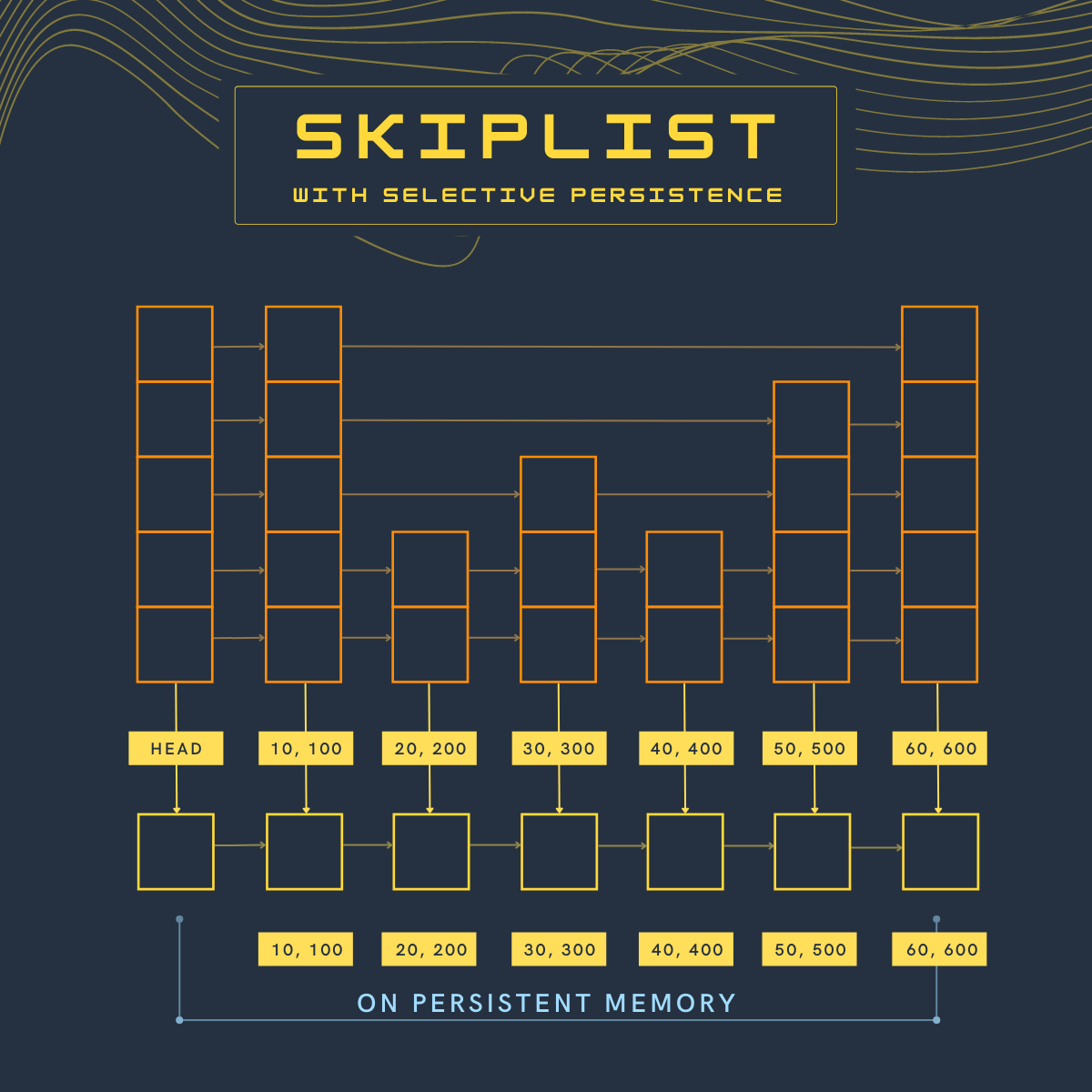
This structure can be modified to have selective persistence and one of the ways to implement selective persistence with skiplist is to have an extension of the lowest level.
Skiplist
The above image represents selective persistence with the skiplist data structure. Yellow-colored nodes are stored on persistent memory. Let's call these nodes leaf nodes.
With this design, the leaf nodes are stored on persistent memory and the internal nodes are stored in RAM. These internal nodes maintain a down pointer to the nodes in persistent memory.
With this design, the leaf nodes are stored on persistent memory and the internal nodes are stored in RAM. These internal nodes maintain a down pointer to the nodes in persistent memory.
Read operations like
get and contains can be done from RAM while the write operations like put, delete, and update will require changes in RAM and persistent memory. Thus, selective persistence leverages the best of RAM and persistent memory.We need to take care of a few things with selective persistence. Let's take a look at them.
Atomicity
Let's assume that we need to put a key/value pair in the skiplist that implements selective persistence. It becomes essential to ensure that the key/value pair is placed in RAM and persistent memory atomically. If there is any failure in performing the write operation either in RAM or in persistent memory, the entire operation should be rolled back.
Recovery
With selective persistence, some part of the data structure stays in RAM, while the rest stays in persistent memory.
This effectively means that we will need to rebuild the part of the data structure residing in RAM in case the machine hosting the data structure goes down or there is a power failure.
Recovery can be summarised as -
void startup() { // during the application (database/storage engine) start up recover(); } void recover() { // build the in-memory nodes from the data stored in persistent memory }
Data in RAM
With selective persistence, some part of the data structure stays in RAM, while the rest stays in persistent memory. In our skiplist example, RAM-based internal nodes contain a key, value, vector of right pointers and a down pointer.
Assuming 10 levels for each node, 4-bytes pointer, 100 bytes for each key and 1024 bytes for each value.
(Practically, not all the nodes in a skiplist will have 10 levels.)
(Practically, not all the nodes in a skiplist will have 10 levels.)
With this, we would have 10*4 bytes for right pointers + 4 bytes for down pointer = 44 bytes + 100 bytes for key + 1024 bytes for value for each node (excluding any padding and assuming none of the right pointers are null).
If the value size is too high, selective persistence could end up using too much RAM.
The selective persistence model described earlier with skiplist can result in too much data in RAM especially if the value size is too high.
This design can be tweaked to store only the keys in the internal nodes and key/value pairs in the leaf nodes. This modified design means that the internal nodes are used for navigation and the leaf nodes are used for getting the value corresponding to a key. To get the value for a given key, the modified algorithm would follow the internal nodes and get to the leaf node which is expected to contain the value. Once the right leaf node is reached, the value will be loaded from persistent memory.
Let's now dive into some use-cases of persistent memory.
Database write-ahead logs (WAL)
Write-ahead logs provide a durability guarantee without the storage data structures to be flushed to disk, by persisting every state change as a command to the append-only log.
The idea behind WAL is to store each state change as a command in a file on a disk.
A single log is maintained for each server process which is sequentially appended. A single log that is appended sequentially simplifies the handling of logs at the restart and for subsequent online operations (when the log is appended with new commands).
Consider a mock implementation of WAL on a block storage device like HDD:
public WriteAheadLog(File file) { try { this.randomAccessFile = new RandomAccessFile(file, "rw"); this.fileChannel = randomAccessFile.getChannel(); } catch (FileNotFoundException e) { throw new RuntimeException(e); } } public Long writeEntry(WriteAheadLogEntry entry) { var buffer = entry.serialize(); return writeToChannel(buffer); } private Long writeToChannel(ByteBuffer buffer){ try { buffer.flip(); while (buffer.hasRemaining()) { fileChannel.write(buffer); } fileChannel.force(false); return fileChannel.position(); } catch (IOException e) { throw new RuntimeException(e); } }
A file is opened in "rw" mode and before a key/value is written to the storage engine, a
WriteAheadLogEntry is created which is serialized to a byte array and written to the file.Assume that we are trying to write a
WriteAheadLogEntry of size 100 bytes. The write from the application to the underlying block storage involves writing an entire block or a page. Typical block sizes are 512, 1024, 2048 and 4096 bytes. This essentially means that even if the data that is being written to a WAL is smaller in size, an entire block would be transferred between the application and the block device.With byte-addressability of persistent memory reads/writes do not involve block transfer. This means write-ahead logs/undo logs/redo logs of a database can be placed on persistent memory to take the advantage of byte addressability and avoid block transfers while doing read or write operations.
Database indexes
Database indexes speed up the read operations against a table or a document. A database index is implemented using a read efficient data structure and one of the common data structures is a B+Tree.
Since a database index is meant to speed up a read operation, it is therefore expected to offer the minimum read latency possible. Since persistent memory offers latency lesser than that of SDDs or HDDs, we can implement a database index (say, using a B+Tree) on persistent memory to get the reduced read latency.
In-memory databases
In-memory databases are purpose-built databases that rely primarily on memory for data storage, in contrast to databases that store data on disk or SSDs. In-memory data stores are designed to enable minimal response times by eliminating the need to access disks. Because all the data is stored and managed exclusively in main memory, in-memory databases risk losing data upon a process or server failure. In-memory databases can persist data on disks by storing each operation in a log or by taking snapshots.
The idea behind in-memory databases can be summarised as:
- Entire dataset is kept in memory
- Each write operation is written to RAM and an append-only log
- In-memory dataset is recovered from append-only log (or transaction log) on machine restart or power failure
There are a couple of ways in which in-memory databases can utilize persistent memory:
- By moving append-only logs to persistent memory as discussed in Database write-ahead logs (WAL)
- By keeping the entire dataset in persistent memory instead of RAM, but this approach would mean a higher latency than that of RAM
With this, we come to the end of our article series on Persistent memory. Persistent memory is
byte-addressable, and this property came in handy when we converted our in-memory dictionary to a persistent dictionary. We used PMDK for making our dictionary persistent, and we used the full persistence approach. As a part of this conversion, we also came across various PMDK concepts like persistent_ptr, p, make_persistent and transaction.Persistent memory is interesting because it provides a new entry in the memory-storage hierarchy that fills the performance/capacity gap and we managed to look at some of the use-cases of persistent memory.
- Non-volatile storage is a type of storage that can retain the stored information even after power is off. ↩
- DIMM (dual in-line memory module) is a module that can be found on the motherboard. The module has slots that contain one or more RAM chips found on a smaller part of the entire motherboard of your computer. The DIMM slots serve as your computer’s main memory storage unit as it houses the RAM chips. ↩
- NVMe (nonvolatile memory express) is a storage access and transport protocol for flash and solid-state drives (SSDs). To help deliver a high-bandwidth and low-latency user experience, the NVMe protocol accesses flash storage via a PCI Express (PCIe) bus, which supports tens of thousands of parallel command queues and thus is much faster than hard disks and traditional all-flash architectures, which are limited to a single command queue. ↩
- DRAM (dynamic random access memory) is volatile memory that stores bits of data in transistors. This memory is located closer to the processor, too, so the computer can easily and quickly access it for all the processes. ↩

