

In modern projects, we almost solely operate on only two kinds of objects:
- Active objects, like services, controllers, repositories, etc. Such classes don’t need to override any methods from
Anybecause the default behavior is perfect for them. Each such object is considered unique because even if two accidentally have the same state, this state changes independently, so we don’t need to overrideequalsandhashCode. We don’t want to expose such objects’ inner state in an uncontrolled way, so they don’t need to overridetoString. - Data model class objects, which represent bundles of data. For such objects, we use the
datamodifier, which overrides thetoString,equals, andhashCodemethods. It makes two objects with the same data (the same primary constructor properties) equal. It also makes thetoStringmethod display the name of the class and the values and names of all primary constructor properties. It also makes thehashCodemethod coherent withequals. Thedatamodifier also implements thecopyandcomponentN(component1,component2, etc.) methods for convenience of modifying and destructuring such objects.
Let's start from a short overview of the methods that the
data modifier overrides.When we add the
data modifier, it generates the following methods:toStringequalsandhashCodecopycomponentN(component1,component2, etc.)
Let’s discuss them in turn.
toString displays the name of the class and the values and names of all primary constructor properties. It is useful for logging and debugging.print(player) // Player(id=0, name=Gecko, points=9999)
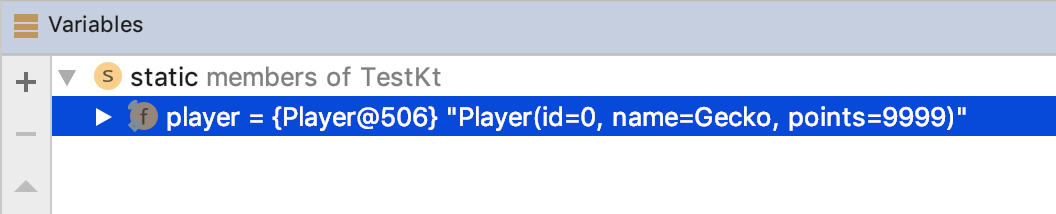
equals checks if all primary constructor properties are equal. hashCode is coherent with it (see 41: Respect the contract of hashCode).player == Player(0, "Gecko", 9999) // true player == Player(0, "Ross", 9999) // false
copy is especially useful for immutable data classes. It creates a new object where each primary constructor’s properties have the same value by default, but each of them can be changed using named arguments.val newObj = player.copy(name = "Thor") print(newObj) // Player(id=0, name=Thor, points=9999)
This is what
copy would look like for the class Person if we wrote it ourselves:// This is how `copy` generated by `data` modifier // for `Person` class looks like under the hood fun copy( id: Int = this.id, name: String = this.name, points: Int = this.points ) = Player(id, name, points)
Notice that the
copy method makes a shallow copy of an object, but this is not a problem when the object is immutable as we do not need deep copies for such objects.componentN functions (component1, component2, etc.) allow position-based destructuring, as in the example below:val (id, name, pts) = player
Destructuring in Kotlin translates directly into variable definitions using the
componentN functions, so this is what the code above will be compiled to under the hood:// After compilation val id: Int = player.component1() val name: String = player.component2() val pts: Int = player.component3()
These are currently all the functionalities that the
data modifier provides. Don't use it if you don't need toString, equals, hashCode, copy or destructuring. If you need some of these functionalities for a class representing a bundle of data, use the data modifier instead of implementing the methods yourself.Kotlin currently provides only position-based property destructuring, that has pros and cons. The biggest advantage is that we can name variables however we want. We can also destructure everything we want as long as it provides
componentN functions. This includes List and Map.Entry, both of which have componentN functions defined as extensions:val visited = listOf("China", "Russia", "India") val (first, second, third) = visited println("$first $second $third") // China Russia India val trip = mapOf( "China" to "Tianjin", "Russia" to "Petersburg", "India" to "Rishikesh" ) for ((country, city) in trip) { println("We loved $city in $country") // We loved Tianjin in China // We loved Petersburg in Russia // We loved Rishikesh in India }
On the other hand, position-based destructuring is dangerous. We need to adjust every destructuring when the order or number of elements in a data class changes. When we use this feature, it is very easy to introduce errors into our code by changing the order of the primary constructor’s properties.
data class FullName( val firstName: String, val secondName: String, val lastName: String ) val elon = FullName("Elon", "Reeve", "Musk") val (name, surname) = elon print("It is $name $surname!") // It is Elon Reeve!
We need to be careful with destructuring. It is useful to use the same names as data class primary constructor properties. In the case of an incorrect order, an IntelliJ/Android Studio warning will be shown. It might be even useful to upgrade this warning to an error.
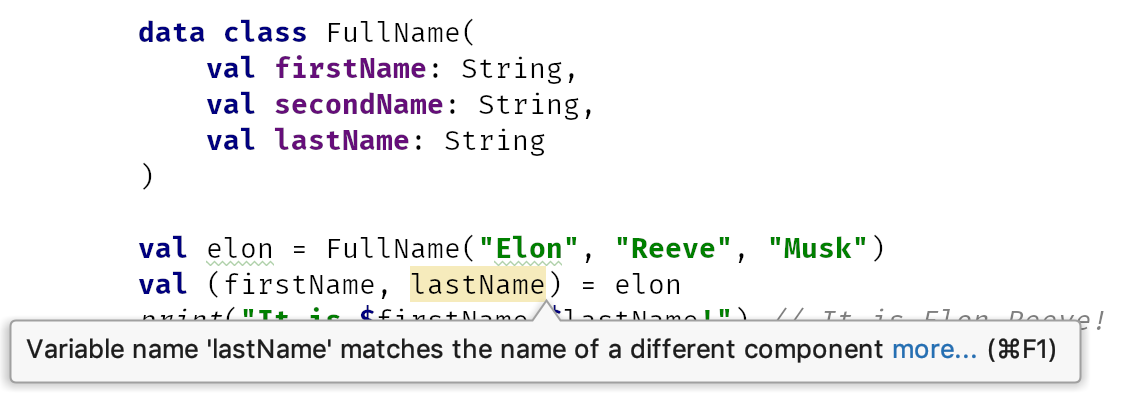
Do not destructure to get just the first value as this might be really confusing and misleading for anyone who will read your code in the future, especially when you destructure in lambda expressions.
data class User(val name: String) fun main() { val user = User("John") // Don't do that val (name) = user print(name) // John user.let { a -> print(a) } // User(name=John) // Don't do that user.let { (a) -> print(a) } // John }
Destructuring a single value in lambda is very confusing, especially since parentheses around arguments in lambda expressions are either optional or required in some languages.
Data classes offer more than what is generally provided by tuples. Historically, they replaced tuples in Kotlin since they are considered better practice1. The only tuples that are left are
Pair and Triple, but they are data classes under the hood:public data class Pair<out A, out B>( public val first: A, public val second: B ) : Serializable { public override fun toString(): String = "($first, $second)" } public data class Triple<out A, out B, out C>( public val first: A, public val second: B, public val third: C ) : Serializable { public override fun toString(): String = "($first, $second, $third)" }
These tuples remained because they are very useful for local purposes, like:
- When we immediately name values:
val (description, color) = when { degrees < 5 -> "cold" to Color.BLUE degrees < 23 -> "mild" to Color.YELLOW else -> "hot" to Color.RED }
- To represent an aggregate not known in advance, as is commonly found in standard library functions:
val (odd, even) = numbers.partition { it % 2 == 1 } val map = mapOf(1 to "San Francisco", 2 to "Amsterdam")
In other cases, we prefer data classes. Take a look at an example: let’s say that we need a function that parses a full name into a name and a surname. One might represent this name and surname as a
Pair<String, String>:fun String.parseName(): Pair<String, String>? { val indexOfLastSpace = this.trim().lastIndexOf(' ') if (indexOfLastSpace < 0) return null val firstName = this.take(indexOfLastSpace) val lastName = this.drop(indexOfLastSpace) return Pair(firstName, lastName) } // Usage val fullName = "Marcin Moskała" val (firstName, lastName) = fullName.parseName() ?: return
The problem is that when someone reads this code, it is not clear that
Pair<String, String> represents a full name. What is more, it is not clear what the order of the values is, therefore someone could think that the surname goes first:val fullName = "Marcin Moskała" val (lastName, firstName) = fullName.parseName() ?: return print("His name is $firstName") // His name is Moskała
To make usage safer and the function easier to read, we should use a data class instead:
data class FullName( val firstName: String, val lastName: String ) fun String.parseName(): FullName? { val indexOfLastSpace = this.trim().lastIndexOf(' ') if (indexOfLastSpace < 0) return null val firstName = this.take(indexOfLastSpace) val lastName = this.drop(indexOfLastSpace) return FullName(firstName, lastName) } // Usage val fullName = "Marcin Moskała" val (firstName, lastName) = fullName.parseName() ?: return
It costs nearly nothing and improves the function significantly:
- The return type of this function is more clear.
- The return type is shorter and easier to pass forward.
- If a user destructures to variables with correct names but in incorrect positions, a warning will be displayed.
If you don’t want this class in a wider scope, you can restrict its visibility. It can even be private if you need to use it for some local processing only in a single file or class. It is worth using data classes instead of tuples. Classes are cheap in Kotlin, so don’t be afraid to use them in your projects.
- Use
datamodifier for classes that are used to represent a bundle of data. - Be careful with destructuring, and when you do that, prefer matching the variable name with the property name.
- Prefer data classes instead of tuples. Defining a data class costs little, and it makes the code more readable and less error-prone.
-
Kotlin had support for tuples when it was still in the beta version. We were able to define a tuple by brackets and a set of types, like
(Int, String, String, Long). What we achieved behaved the same as data classes in the end, but it was far less readable. Can you guess what type this set of types represents? It can be anything. Using tuples is tempting, but using data classes is nearly always better. This is why tuples were removed and onlyPairandTripleare left. ↩



