

Whenever more than one thread has access to mutable state, and at least one thread modifies this state, there is a risk of unexpected behavior because the threads can interfere with each other. Let's start with a simple example in which 10,000 coroutines running on more than one thread try to increment a number. If no conflicts occur, the result should be 10,000, but the actual result will be smaller, such as 8562.
import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch suspend fun main() { var num = 0 coroutineScope { repeat(10_000) { launch { // uses Dispatchers.Default delay(10) num++ } } } print(num) } // The result very unlikely to be 10000, should be much smaller
The problem is that the
num++ operation is not atomic. It consists of three operations: read the current value, increment it, and write the new value. If two threads read the value at the same time, they will both increment it and write the same value back. These two processes can happen at the same time because our processors are multicore and the coroutines run on different threads. It is also possible that the second read happens between the read and write on the first thread if the OS decides to switch threads1. In both cases, we lose some data.
Under the hood, the
num++ operation is composed of three operations: read, increment, and write. If two threads read the value at the same time, or the second read happens before the first write, the result will be lost.The same problem applies if we update a list or a map. If we have a read-only list, appending it requires making a copy that has an additional element. Making such a copy is a heavy operation, which commonly causes conflicts because there is more time between the read and the write, thus increasing the likelihood that another read will happen between these operations).
import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch data class User(val name: String) suspend fun main() { var users = listOf<User>() coroutineScope { repeat(10_000) { i -> launch { delay(10) users += User("User$i") } } } print(users.size) } // The result very unlikely to be 10000, likely around 3000
If we use a mutable list, there should be fewer conflicts because adding an element to a mutable list is faster, but there is still a risk of an exception due to an inconsistency in this object's state. Mutable collections execute a lot of operations when adding elements, therefore predicting all the possible consequences is very hard. For a regular list, the most typical exception that might be caused by a concurrent addition is
ArrayIndexOutOfBoundsException, which is the result of an inconsistency between an internal array reference and its expected size.import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch data class User(val name: String) suspend fun main() { val users = mutableListOf<User>() coroutineScope { for (i in 1..10000) { launch { delay(10) users += User("User$i") } } } println(users.size) } // number around 9500 // or // ArrayIndexOutOfBoundsException
How can we deal with these problems? Popular solutions involve:
- Using atomic values
- Using concurrent collections
- Using a synchronized block
- Using a dispatcher limited to a single thread
- Using Mutex
- Communicating between coroutines using
Channel
Each of these solutions has pros and cons. None of them is a universal solution, but using the appropriate technique is essential to balance efficiency, convenience, and safety. So, let's discuss them one by one (only
Channel will be explained in a later chapter).On Android, all coroutines run on the main thread by default, so there is no risk of conflicts. However, if we useDispatchers.DefaultorDispatchers.IO, we need to be aware of the risk of conflicts.
One of the oldest and most efficient ways to secure a state is by using atomic values, which can be read and written atomically, therefore they are safe to use in parallel. They can be very helpful and efficient, but only in specific cases.
There are different kinds of atomic values we can use in Kotlin. A popular one is
AtomicInteger2 from Java stdlib, which is used to store an integer value. It has methods like incrementAndGet that are atomic, which means they are implemented such that it is impossible for them to have conflicts.import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch import java.util.concurrent.atomic.AtomicInteger suspend fun main() { var num = AtomicInteger(0) coroutineScope { repeat(10_000) { launch { delay(10) num.incrementAndGet() } } } print(num) // 10000 }
Another popular atomic is
AtomicReference from Java stdlib, which can store any value3; its most important methods are get, updateAndGet, and compareAndSet.import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch import java.util.concurrent.atomic.AtomicReference suspend fun main() { var str = AtomicReference("") coroutineScope { repeat(10_000) { launch { delay(10) str.updateAndGet { it + "A" } } } } print(str.get().length) // 10000 }
Updates should not be heavy or time-consuming operations.
updateAndGet works by getting the current value before and after calculating an update, and it sets the update only if the value hasn’t changed in the meantime. This means an update might be calculated multiple times, and if many threads try to do heavy updates at the same time, they might constantly conflict with each other. This is why updates should be lightweight.Atomic values are perfect when you only need to protect one value or one reference. They are also used as part of more complex algorithms. They can be very efficient but must be used with great care. They are, for instance, used in the internal implementation of
Channel (AtomicFu atomics are used there).
The essence of
AtomicReference lies in compound functions like updateAndGet or compareAndSet. If you only need to get and set a value, you don’t need any special reference: you can just use a regular variable or property. However, if you use no other synchronization mechanism and you use a regular property from multiple threads, such a property needs the @Volatile annotation to prevent unexpected behavior that might be caused by lower-level optimizations (like caching on JVM threads).The example below was inspired by Brian Goetz's book Java Concurrency in Practice. The
Volatile annotation is required here because number and ready can be used from more than one thread, and no synchronization mechanism is used. Otherwise, it is even possible for this code to print 0 or to wait for a long time. These effects are very hard to observe but technically possible due to low-level JVM optimizations.import kotlin.concurrent.thread @Volatile var number: Int = 0 @Volatile var ready: Boolean = false fun main() { thread { while (!ready) { Thread.yield() } println(number) } number = 42 ready = true }
Beware that the
Volatile annotation only ensures visibility of changes across threads but does not provide atomicity! It is used for properties that need to be used from multiple threads but do not need to be synchronized. The snippets below need the num update to be synchronized, but the Volatile annotation does not help with that.import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch @Volatile var num = 0 suspend fun main() { coroutineScope { repeat(10_000) { launch { delay(10) num++ } } } print(num) // around 9800, not 10000 }
If you only need to synchronize a single collection, the simplest approach is to just use a concurrent collection, which is a collection whose member functions are synchronized by design. The most popular one is
ConcurrentHashMap from Java stdlib, which is a map that guarantees that all its operations are synchronized. It also allows a replacement to be made for a Set using ConcurrentHashMap.newKeySet(). You can treat all concurrent collections’ member functions as if they were all wrapped with a synchronized block, and iteration over these collections is safe as it does not reflect changes that occur during iteration.import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch import java.util.concurrent.ConcurrentHashMap data class User(val name: String) suspend fun main() { val users = ConcurrentHashMap.newKeySet<User>() coroutineScope { for (i in 1..10000) { launch { delay(10) users += User("User$i") } } } println(users.size) // 10000 }
Consider
ProductRepository, which is used to fetch products by id but also caches values already fetched so as to not return them from memory next time. Using a regular map to store values would mean that if getProduct were used from multiple threads, we might have conflicts when setting values, which might result in some values not being stored or the occasional ArrayIndexOutOfBoundsException. It is enough to use ConcurrentHashMap to avoid such problems.class ProductRepository( val client: ProductClient, ) { private val cache = ConcurrentHashMap<Int, Product>() suspend fun getProduct(id: Int): Product? { val product = cache[id] if (product != null) { return product } else { val fetchedProduct = client.fetchProduct(id) if (fetchedProduct != null) { cache[id] = fetchedProduct } return fetchedProduct } } // ... }
The biggest problem of concurrent collections is that they do not allow more than one operation to be synchronized. Consider a function that needs to increment a counter for a key. If it uses one operation for reading and another for writing, there might be conflicts due to another thread doing something between these operations.
import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.launch import java.util.concurrent.ConcurrentHashMap var counter = ConcurrentHashMap<String, Int>() // Incorrect implementation fun increment(key: String) { val value = counter[key] ?: 0 counter[key] = value + 1 } suspend fun main() { coroutineScope { repeat(10_000) { launch { // uses Dispatchers.Default increment("A") } } } print(counter) // {A=7162} }
This problem can be mitigated with operations that are more compound, like
compute, but there are cases where using a mutable collection is just not enough, so we need to use other synchronization mechanisms.import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.launch import java.util.concurrent.ConcurrentHashMap var counter = ConcurrentHashMap<String, Int>() // Correct implementation fun increment(key: String) { counter.compute(key) { _, v -> (v ?: 0) + 1 } } suspend fun main() { coroutineScope { repeat(10_000) { launch { // uses Dispatchers.Default increment("A") } } } print(counter) // {A=10000} }
The snippet below shows a common mistake when using concurrent collections. A new element might be added to the collection during the iteration in
sendBundle, and this element would be removed by clear without being sent. The simplest solution is using a different synchronization mechanism, like synchronized block, instead of a concurrent collection.class EventSender { private val waiting = ConcurrentHashMap.newKeySet<Event>() fun schedule(event: Event) { waiting.add(event) } fun sendBundle() { // Incorrect implementation! // Some elements might be removed without being sent sentEvents(waiting.toList()) waiting.clear() } }
Java stdlib also offers
ConcurrentLinkedQueue and ConcurrentLinkedDeque. Currently, Kotlin stdlib does not provide any concurrent collections, and I don’t know any multiplatform libraries to recommend, so this solution is constrained to Kotlin/JVM.Concurrent collections are useful and popular, but they don’t solve all problems. Each of their operations is synchronized, but we cannot synchronize multiple operations. We use them where we need to synchronize just one collection in a class or a function.
Before we start covering coroutine-specific tools, let’s cover one more JVM-specific tool that we inherited from Java. A synchronized block ensures that code within blocks with the same locks execute sequentially, not concurrently, therefore there is no risk of conflicts.
class EventSender { private val waiting = mutableSetOf<Event>() private val lock = Any() fun schedule(event: Event) = synchronized(lock) { waiting.add(event) } fun sendBundle() { val eventsToSend = synchronized(lock) { val copy = waiting.toList() waiting.clear() copy } sentEvents(eventsToSend) } }
How does it work? When a thread enters a block, it reserves the lock (passed as an argument) and can execute the code inside the block. If another thread tries to enter a block with the same lock, it is blocked until the first thread leaves its block. This way, all threads are synchronized, which means that only one thread can execute blocks using the same lock at the same time, thus avoiding conflicts.
import kotlinx.coroutines.* suspend fun main() { var num = 0 val lock = Any() coroutineScope { repeat(10_000) { launch { delay(10) synchronized(lock) { num++ } } } } print(num) // 10000 }
A synchronized block is a very powerful tool as it can be used to secure any number of operations. The lock can be any object, but it is good practice to use a dedicated object for this. We typically use a class reference (
this) or a dedicated object created with Any() because it is the simplest object that can be used for this purpose.synchronized(this) { ... } // or val lock = Any() synchronized(lock) { ... }
Synchronized blocks are perfect for securing simple non-suspending functions that contain no blocking or CPU-intensive operations.
We should avoid using synchronized blocks on suspending functions because they are blocking, and we should avoid blocking coroutines whenever possible. It is also impossible to call suspending functions from inside a synchronized block.
It is possible to make blocking calls from inside a synchronized block, but it is generally not recommended because it means that other threads need to wait for the one that is blocked. Consider the following code, assuming that
fetchProduct is a blocking function:class ProductRepository( val client: ProductClient, ) { private val cache = mutableMapOf<Int, Product>() private val lock = Any() suspend fun getProduct(id: Int): Product? = synchronized(lock) { val product = cache[id] if (product != null) { return product } else { val fetchedProduct = client.fetchProduct(id) if (fetchedProduct != null) { cache[id] = fetchedProduct } return fetchedProduct } } // ... }
The problem with this solution is that if 10 threads try to get 10 different products, and fetching each one takes 1 second, it will take 10 seconds because the fetching will happen sequentially, which is far from perfect. This can be improved if instead of wrapping whole functions in a synchronized block (an approach known as coarse-grained synchronization), we wrap only the smallest possible part of the code (an approach known as fine-grained synchronization).
class ProductRepository( val client: ProductClient, ) { private val cache = mutableMapOf<Int, Product>() private val lock = Any() suspend fun getProduct(id: Int): Product? { val product = synchronized(lock) { cache[id] } if (product != null) { return product } else { val fetchedProduct = client.fetchProduct(id) if (fetchedProduct != null) { synchronized(lock) { cache[id] = fetchedProduct } } return fetchedProduct } } // ... }
In general, a synchronized block (and
Mutex) should not be used coarse-grained for functions that include suspending or blocking calls because then another thread/coroutine would wait for that suspending/blocking call to finish, which is often not desired.In this case, though, using coarse-grained synchronization has one benefit: if multiple threads try to get the same product at the same time, sequential coarse-grained implementation will fetch this product only once, while fine-grained implementation will start multiple requests. This is a benefit, but the price is high. The best solution to this problem is a third-party cache, like Caffeine or Aedile cache.

By fine-grained synchronization, we mean a solution that wraps only the smallest possible part of the code. By coarse-grained, we mean wrapping whole functions.
When we use
synchronized blocks inside each other, and each of these blocks has multiple locks, it is possible to reach a state in which these blocks wait for one another. This situation is known as deadlock as it will never be resolved: these blocks will simply wait until one of the threads is killed. This is another argument to use fine-grained synchronization in order to precisely wrap only what needs to be synchronized.import kotlin.concurrent.thread val lock1 = Any() val lock2 = Any() fun f1() = synchronized(lock1) { Thread.sleep(1000L) synchronized(lock2) { println("f1") } } fun f2() = synchronized(lock2) { Thread.sleep(1000L) synchronized(lock1) { println("f2") } } fun main() { thread { f1() } thread { f2() } }
There is also the
Synchronized annotation on JVM, which works just like a synchronized block using a private class-specific lock. Since it is coarse-grained by design, it often leads to incorrect usage. I avoid using it.We use a
synchronized block in non-suspending functions, where simpler tools like concurrent collections or atomic values are not enough for our needs.The most popular way to synchronize access to mutable states in projects that use coroutines is to use a dispatcher limited to a single thread. We don’t need any other synchronization mechanisms where such a dispatcher is used because there is no risk of conflicts if only one thread is used.
import kotlinx.coroutines.* suspend fun main() { var num = 0 val dispatcher = Dispatchers.IO.limitedParallelism(1) coroutineScope { repeat(10_000) { launch(dispatcher) { delay(10) num++ } } } print(num) // 10000 }
In practice, we typically set such a dispatcher using
withContext in suspending functions that we want to protect.class ProductRepository( val client: ProductClient, ) { private val cache = mutableMapOf<Int, Product>() private val dispatcher = Dispatchers.IO.limitedParallelism(1) suspend fun getProduct(id: Int): Product? = withContext(dispatcher) { val product = cache[id] if (product != null) { product } else { val fetchedProduct = client.fetchProduct(id) if (fetchedProduct != null) { cache[id] = fetchedProduct } fetchedProduct } } // ... }
A dispatcher limited to a single thread, unlike a
synchronized block or Mutex, can be safely used for coarse-grained synchronization of functions that include suspending calls. This is because if a coroutine is suspended, the thread is freed, and another coroutine can be executed. This is a huge convenience, which is why it is the most popular way to synchronize in coroutines.import kotlinx.coroutines.* import kotlin.system.measureTimeMillis class MessagesRepository { private val messages = mutableListOf<String>() private val dispatcher = Dispatchers.IO.limitedParallelism(1) suspend fun add(message: String) = withContext(dispatcher) { delay(1000) // we simulate network call messages.add(message) } } suspend fun main() { val repo = MessagesRepository() val timeMillis = measureTimeMillis { coroutineScope { repeat(5) { launch { repo.add("Message$it") } } } } println(timeMillis) // 1058 }
One problem with using a dispatcher limited to a single thread is that such a dispatcher replaces the test dispatcher in tests, which might mess with our tests. That is why we need to replace this dispatcher in tests with either a test dispatcher or an empty context. This will be explained in the next chapter.
class ProductRepository( val client: ProductClient, dispatcher: CoroutineDispatcher ) { private val cache = mutableMapOf<Int, Product>() private val dispatcher = dispatcher.limitedParallelism(1) suspend fun getProduct(id: Int): Product? = withContext(dispatcher) { val product = cache[id] if (product != null) { product } else { val fetchedProduct = client.fetchProduct(id) if (fetchedProduct != null) { cache[id] = fetchedProduct } fetchedProduct } } // ... }
This approach is efficient in most cases as it suspends instead of blocking; so in most cases, coroutines just run on the same thread that started them because coroutine dispatchers share the same pool of threads4. This approach is also multiplatform, so it can be used in common modules. The only problem is that it requires suspension, so it is only suitable for functions that are already suspended. We don’t like to make simple functions suspending just for synchronization, therefore for most non-suspending functions, we prefer other approaches, like the
synchronized block.The last option is
Mutex, which is used a lot like a synchronized block, but for coroutines. Beware that it needs to be used with more care as it can more easily reach a deadlock. Mutex is efficient and allows us to implement patterns that are hard or impossible to implement using other tools. It is popular for libraries but less popular for business logic.You can imagine
Mutex as a room for which there is only one key, which must be passed from one person to the next if they want to enter the room – like a toilet in a cafe. Its most important function is lock. When the first coroutine calls it, this coroutine takes the key and passes through the lock without suspension. If another coroutine then calls lock, it will be suspended until the first coroutine calls unlock (like a person waiting for the key to the toilet5). If another coroutine reaches the lock function, it is suspended and put in a queue just after the second coroutine. When the first coroutine finally calls the unlock function, it gives back the key, so the second coroutine (the first one in the queue) is now resumed and can finally pass through the lock function. This way, only one coroutine is allowed between lock and unlock calls.import kotlinx.coroutines.coroutineScope import kotlinx.coroutines.delay import kotlinx.coroutines.launch import kotlinx.coroutines.sync.Mutex suspend fun main(): Unit = coroutineScope { repeat(5) { launch { delayAndPrint() } } } val mutex = Mutex() suspend fun delayAndPrint() { mutex.lock() delay(1000) println("Done") mutex.unlock() } // (1 sec) // Done // (1 sec) // Done // (1 sec) // Done // (1 sec) // Done // (1 sec) // Done
Using
lock and unlock directly is risky because any exception (or premature return) in between would lead to the key never being given back (unlock would never be called); as a result, no other coroutines would be able to pass through the lock, so we have a deadlock (imagine a toilet that cannot be used because someone was in a hurry and forgot to give back the key). So, instead of using lock and unlock directly, we can use the withLock function, which starts with lock but calls unlock on the finally block so that any exceptions thrown inside the block will successfully release the lock. In use, it is similar to a synchronized block.import kotlinx.coroutines.* import kotlinx.coroutines.sync.* suspend fun main() { val mutex = Mutex() var num = 0 coroutineScope { repeat(10_000) { launch { mutex.withLock { num++ } } } } print(num) // 10000 }
Mutex is often used similarly to a
synchronized block, but it is suspending instead of blocking. Mutex is considered lightweight and often provides better performance than a dispatcher limited to a single thread or a synchronized block when we use coroutines. On the other hand, it is harder to use properly and it has one important danger: a coroutine cannot get past the lock twice (if the key is still in the door, another door requiring the same key is impossible to open). The execution of the code below will result in a program state called deadlock - it will be blocked forever. Such a situation is common when developers use Mutex coarse-grained, i.e., they wrap whole functions with it.import kotlinx.coroutines.sync.Mutex import kotlinx.coroutines.sync.withLock suspend fun main() { val mutex = Mutex() println("Started") mutex.withLock { mutex.withLock { println("Will never be printed") } } } // Started // (runs forever)
Mutex is not unlocked when a coroutine is suspended. This is the same problem as with asynchronized block. The code below takes over 5 seconds to run because the mutex is still locked during delay. Mutex makes the section of code between lock and unlock synchronous, so it is not a good idea to use it with suspending functions unless our goal is to synchronize the execution of coroutines.import kotlinx.coroutines.* import kotlinx.coroutines.sync.Mutex import kotlinx.coroutines.sync.withLock import kotlin.system.measureTimeMillis class MessagesRepository { private val messages = mutableListOf<String>() private val mutex = Mutex() suspend fun add(message: String) = mutex.withLock { delay(1000) // we simulate network call messages.add(message) } } suspend fun main() { val repo = MessagesRepository() val timeMillis = measureTimeMillis { coroutineScope { repeat(5) { launch { repo.add("Message$it") } } } } println(timeMillis) // ~5120 }
This is why we avoid using Mutex to wrap whole functions (the coarse-grained approach). If we decide to use it, we need to do so with great care to avoid locking twice, as can happen if in one function using a mutex we call another one using the same mutex.
class MongoUserRepository( //... ) : UserRepository { private val mutex = Mutex() override suspend fun updateUser( userId: String, userUpdate: UserUpdate ): Unit = mutex.withLock { val currentUser = getUser(userId) // Deadlock! deleteUser(userId) // Deadlock! addUser(currentUser.updated(userUpdate)) // Deadlock! } override suspend fun getUser( userId: String ): User = mutex.withLock { // ... } override suspend fun deleteUser( userId: String ): Unit = mutex.withLock { // ... } override suspend fun addUser( user: User ): User = mutex.withLock { // ... } }
This example was just to show the problem with Mutex. Of course, in real-life applications we prefer to make compound transformations on the database level using one request (not three).
Fine-grained thread confinement (wrapping only the place where we modify the shared state) would help, but in the example above I would prefer to use a dispatcher that is limited to a single thread.
When we use
withLock, we can specify an owner; this helps with debugging and protects us from deadlock by throwing an exception if a mutex is already locked with the same token.import kotlinx.coroutines.sync.Mutex import kotlinx.coroutines.sync.withLock suspend fun main() { val mutex = Mutex() println("Started") mutex.withLock("main()") { mutex.withLock("main()") { println("Will never be printed") } } } // Started // IllegalStateException: This mutex is already // locked by the specified owner: main()
Mutex is also used to enforce the sequential execution of coroutines. Some libraries use this technique to implement tools like caches or lazy instantiation.
Mutex is an efficient tool that can be very powerful in skilled hands, but less-experienced developers often prefer to use simpler tools, therefore it is mainly used in libraries and less often in business logic.
We have mentioned
Mutex, we should also mention Semaphore, which works in a similar way but can have more than one permit. Regarding Mutex, we speak of a single lock, so it has the functions lock, unlock, and withLock. Regarding Semaphore, we speak of permits, so it has the functions acquire, release, and withPermit.import kotlinx.coroutines.* import kotlinx.coroutines.sync.* suspend fun main(): Unit = coroutineScope { val semaphore = Semaphore(2) repeat(5) { launch { semaphore.withPermit { delay(1000) print(it) } } } } // 01 // (1 sec) // 23 // (1 sec) // 4
Semaphore with more than one permit does not help us with the problem of shared states, but it can be used to limit the number of concurrent requests, so to implement rate limiting or throttling. For example, we can limit the number of concurrent requests to a network service to avoid overloading it.
class LimitedNetworkUserRepository( private val api: UserApi ) { // We limit to 10 concurrent requests private val semaphore = Semaphore(10) suspend fun requestUser(userId: String) = semaphore.withPermit { api.requestUser(userId) } }
When we have more than one thread that has access to mutable state, and at least one of them modifies this state, there is a risk of unexpected behavior. We deal with such a situation when we use coroutines on dispatchers that use multiple threads.
There are many ways in which coroutines can be orchestrated to avoid conflicts when modifying a shared state. Here is a summary of the most popular ones:
- Atomic values are used when we need to protect one value or one reference. They are efficient and can be used in multiplatform projects.
- Concurrent collections are used when we only need to synchronize one collection. They are efficient and easy to use, but they do not allow more than one operation to be synchronized. They are currently specific to JVM.
- A synchronized block is a universal and popular JVM tool for synchronizing a shared state in a blocking manner. It is used in non-suspending functions, where simpler tools like concurrent collections or atomic values are not enough for our needs.
- A dispatcher limited to a single thread is used in suspending functions and is the simplest way to synchronize access to mutable state in coroutines. It is efficient, multiplatform.
- Mutex is a more advanced tool for synchronizing suspending functions. It allows us to synchronize access to mutable state in coroutines, as well as to enforce the sequential execution of some processes. It is efficient but harder to use properly than a dispatcher limited to a single thread.
Here is my simplified decision tree for choosing the right synchronization tool:
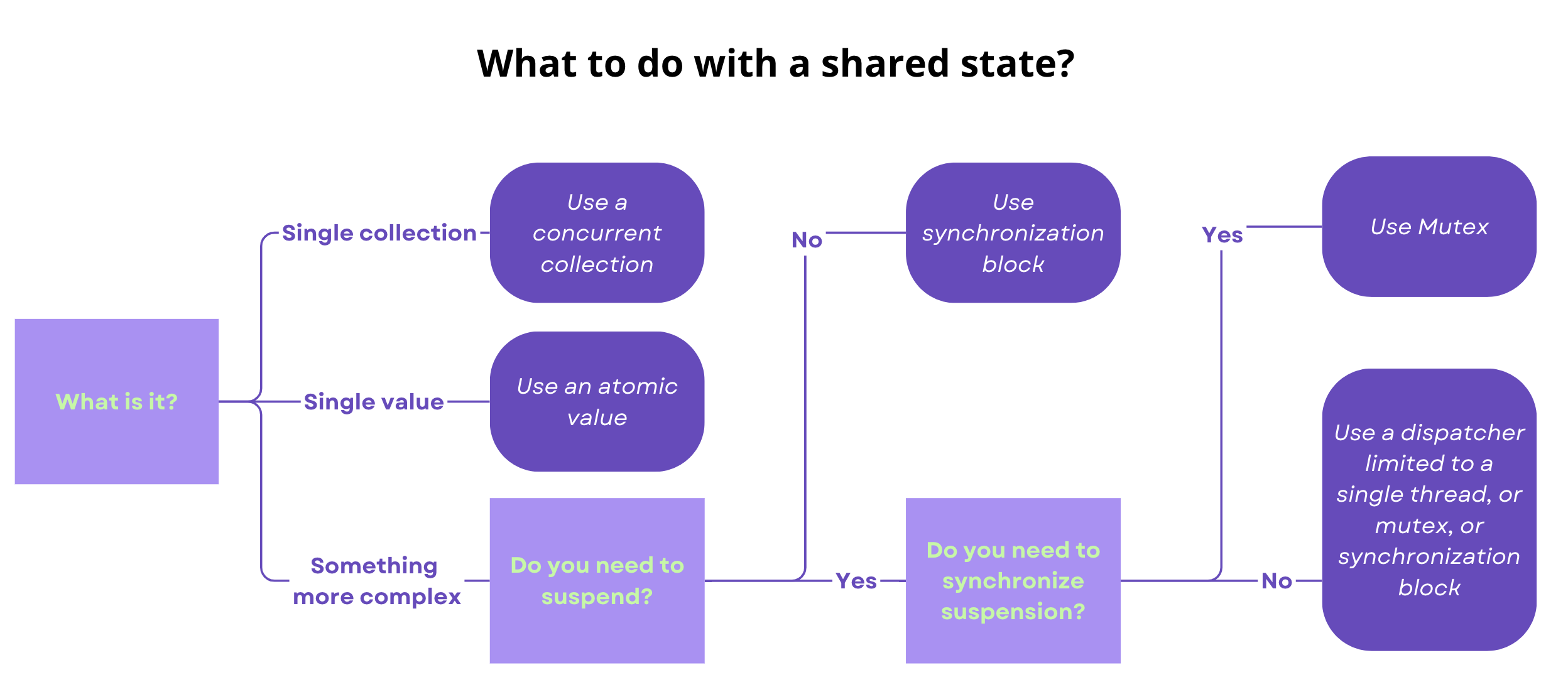
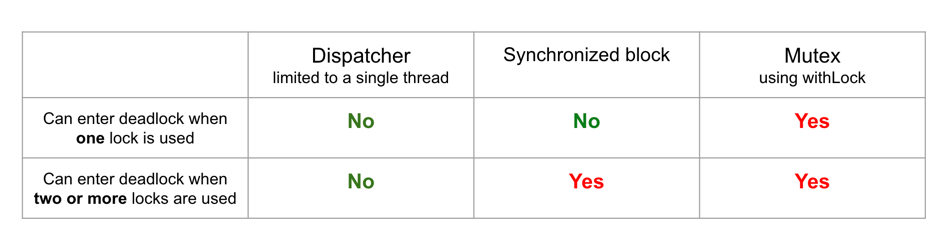
A dispatcher limited to a single thread is the simplest to use because it has no risk of deadlock. A synchronized block can end up in deadlock when two locks are used, and a mutex gets deadlocked even if one mutex is used.
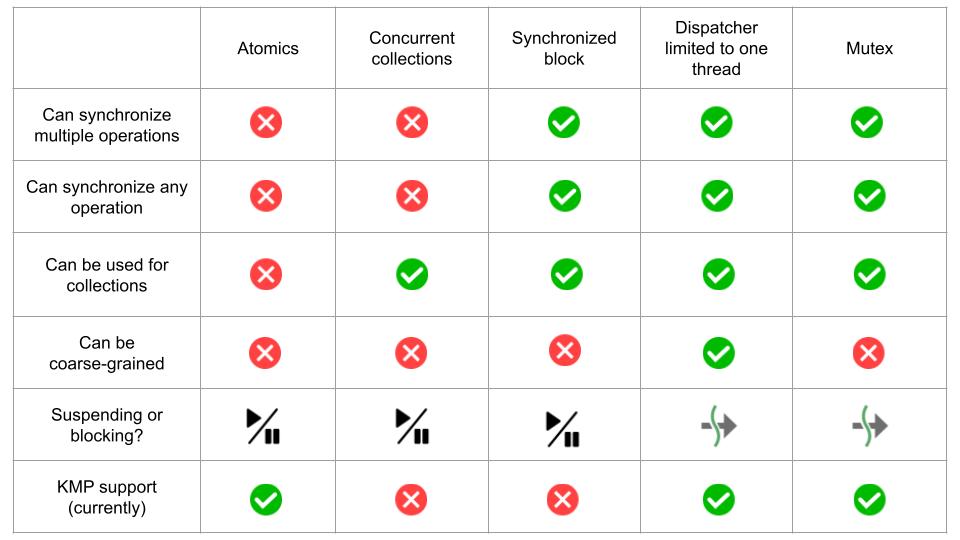
Here is a table presenting the key differences between these tools:
There is also
Semaphore, which works in a similar way to Mutex but can have more than one permit. It can be used to limit the number of concurrent requests, so to implement rate limiting or throttling.- This can also happen on computers with a single core. ↩
- For common modules or Kotlin/JVM, you can use the AtomicFU library. For Kotlin/Native, there are atomic values in Kotlin stdlib. ↩
-
They should be used to store references to immutable objects; if they are not, then methods mutating mutable objects are still unsafe. We should also avoid using
AtomicReferencefor primitives – we have dedicated objects for that. ↩ -
I mean here
Dispatchers.Default,Dispatchers.IO, and all the dispatchers created from them usinglimitedParallelism. ↩ - To avoid giving a false impression of my home country, asking for the key to a toilet is something I mainly experience outside of Poland. For instance, in Poland, practically every petrol station has a toilet available for everyone, no key required (and they are generally clean and tidy). However, in many other European countries, especially in Switzerland, toilets are better protected from people who might try to use them without buying anything. ↩


