

To jest rozdział z książki Kotlin Essentials.
W Kotlinie mówimy, że wszystkie klasy dziedziczą po nadrzędnej klasie
Any, która znajduje się na szczycie hierarchii klas1. Metody zdefiniowane w Any mogą być wywoływane na wszystkich obiektach. Są to metody:equals- używana przy porównywaniu dwóch obiektów za pomocą==,hashCode- używana przez kolekcje, które korzystają z algorytmu hash table,toString- używana do reprezentacji obiektu jako stringa, np. w szablonie stringa lub funkcjiprint.
Dzięki tym metodom możemy reprezentować dowolny obiekt jako string lub sprawdzić równość dowolnych dwóch obiektów.
// Formalna definicja Any open class Any { open operator fun equals(other: Any?): Boolean open fun hashCode(): Int open fun toString(): String } class A // Dziedziczenie po Any jest domyślne fun main() { val a = A() a.equals(a) a == a a.hashCode() a.toString() println(a) }
Prawdę mówiąc,Anyjest reprezentowane jako klasa, ale powinno być raczej traktowane jako typ. Chociażby dlatego, żeAnyjest także nadrzędnym typem wszystkich interfejsów, mimo że interfejsy nie mogą dziedziczyć po klasach.
Domyślne implementacje
equals, hashCode i toString są mocno oparte na adresie obiektu w pamięci. Metoda equals zwraca true tylko wtedy, gdy adres obu obiektów jest taki sam, co oznacza, że po obu stronach jest ten sam obiekt. Metoda hashCode zamienia ten adres na liczbę. toString generuje string, który zaczyna się od nazwy klasy, a następnie znaku małpy "@", a potem skrótu adresu obiektu w notacji szesnastkowej.class A fun main() { val a1 = A() val a2 = A() println(a1.equals(a1)) // true println(a1.equals(a2)) // false // lub println(a1 == a1) // true println(a1 == a2) // false println(a1.hashCode()) // Przykład: 149928006 println(a2.hashCode()) // Przykład: 713338599 println(a1.toString()) // Przykład: A@8efb846 println(a2.toString()) // Przykład: A@2a84aee7 // lub println(a1) // Przykład: A@8efb846 println(a2) // Przykład: A@2a84aee7 }
Poprzez nadpisywanie tych metod możemy zdecydować, jak klasa powinna się zachowywać. Rozważ poniższą klasę
A, która jest równa innym instancjom tej samej klasy i zwraca stały hash oraz reprezentację stringa.class A { override fun equals(other: Any?): Boolean = other is A override fun hashCode(): Int = 123 override fun toString(): String = "A()" } fun main() { val a1 = A() val a2 = A() println(a1.equals(a1)) // true println(a1.equals(a2)) // true // lub println(a1 == a1) // true println(a1 == a2) // true println(a1.hashCode()) // 123 println(a2.hashCode()) // 123 println(a1.toString()) // A() println(a2.toString()) // A() // lub println(a1) // A() println(a2) // A() }
W książce Efektywny Kotlin poświęciłem oddzielne tematy na implementację własnych metod
equals i hashCode2, ale w praktyce rzadko musimy to robić. Okazuje się, że we współczesnych projektach prawie wyłącznie operujemy tylko na dwóch rodzajach obiektów:- Aktywne obiekty, takie jak usługi (services), kontrolery, repozytoria itp. Takie klasy nie muszą nadpisywać żadnych metod z
Any, ponieważ domyślne zachowanie jest dla nich odpowiednie. - Obiekty reprezentujące nasz model danych, takie jak
User,Paymentitp. Dla takich obiektów używamy modyfikatoradata, który nadpisuje metodytoString,equalsihashCodew sposób odpowiedni dla klas modelu danych. Modyfikatordataimplementuje również metodycopyorazcomponentN(component1,component2itp.), które nie są dziedziczone i nie mogą być modyfikowane.
data class Player( val id: Int, val name: String, val points: Int ) val player = Player(0, "Gecko", 9999)
Przeanalizujmy wspomniane wcześniej domyślne metody data klasy oraz różnice między zachowaniem zwykłej klasy a zachowaniem data klasy.
Domyślne przekształcenie
toString generuje string zaczynającego się od nazwy klasy, a następnie zawierającego znak małpy "@" oraz hash adresu w reprezentacji szesnastkowej. Celem tego jest wyświetlenie nazwy klasy oraz określenie, czy dwa stringi reprezentują ten sam obiekt, czy nie.class FakeUserRepository fun main() { val repository1 = FakeUserRepository() val repository2 = FakeUserRepository() val repository1ref = repository1 println(repository1) // np. FakeUserRepository@8efb846 println(repository2) // np. FakeUserRepository@2a84aee7 println(repository1ref) // np. FakeUserRepository@8efb846 }
Dzięki modyfikatorowi
data, kompilator generuje toString, który wyświetla nazwę klasy, a następnie pary z nazwą i wartością dla każdej właściwości konstruktora głównego. Zakładamy, że klasy modelu danych są reprezentowane przez ich właściwości konstruktora głównego, więc wszystkie te właściwości wraz z ich wartościami są wyświetlane podczas przekształcania na string. Jest to przydatne przy loggowaniu i do debugowania.data class Player( val id: Int, val name: String, val points: Int ) fun main() { val player = Player(0, "Gecko", 9999) println(player) // Player(id=0, name=Gecko, points=9999) println("Player: $player") // Player: Player(id=0, name=Gecko, points=9999) }
W Kotlinie sprawdzamy równość dwóch obiektów za pomocą
==, które używa metody equals z Any. Ta metoda decyduje więc, czy dwa obiekty powinny być uznane za równe, czy nie. Domyślnie dwie różne instancje nigdy nie są równe. Jest to doskonałe zachowanie dla aktywnych obiektów, czyli obiektów, dla których każda instancja jest unikatowa i chroni swój stan.class FakeUserRepository fun main() { val repository1 = FakeUserRepository() val repository2 = FakeUserRepository() println(repository1 == repository1) // true println(repository1 == repository2) // false }
Klasy z modyfikatorem
data reprezentują zbiór danych; dwa obiekty tej klasy uważa się za równe jeśli:- są dokładnie tej samej klasy,
- ich wartości właściwości głównego konstruktora są równe.
data class Player( val id: Int, val name: String, val points: Int ) fun main() { val player = Player(0, "Gecko", 9999) println(player == Player(0, "Gecko", 9999)) // true println(player == Player(0, "Ross", 9999)) // false }
Tak wygląda uproszczona implementacja metody
equals generowanej przez modyfikator data dla klasy Player:override fun equals(other: Any?): Boolean = other is Player && other.id == this.id && other.name == this.name && other.points == this.points
Implementacja własnej metodyequalsopisana jest w Efektywny Kotlin, Temat 42: Szanuj kontrakt metody equals.
Kolejną metodą z klasy
Any jest hashCode, która służy do przekształcenia obiektu na wartość Int. Dzięki metodzie hashCode instancję obiektu można przechowywać w implementacjach struktury danych hash table (co się tłumaczy także jako "tablica mieszająca"), będących częścią wielu popularnych klas, takich jak HashSet i HashMap. Najważniejsza zasada implementacji hashCode mówi, że powinna ona:- być zgodna z
equals, więc powinna zwracać tą samą wartośćIntdla równych obiektów, a także zawsze zwracać ten sam kod hashujący dla tego samego obiektu. - rozkładać obiekty jak najbardziej równomiernie w zakresie wszystkich możliwych wartości
Int.
Domyślny
hashCode opiera się na adresie obiektu w pamięci. Kod hashujący generowany przez modyfikator data opiera się na kodach hashujących właściwości głównego konstruktora tego obiektu. Gdy dwa obiekty są równe, ich kody hashujące również muszą być równe.data class Player( val id: Int, val name: String, val points: Int ) fun main() { println(Player(0, "Gecko", 9999).hashCode()) // 2129010918 println(Player(0, "Gecko", 9999).hashCode()) // 2129010918 println(Player(0, "Ross", 9999).hashCode()) // 79159602 }
Aby dowiedzieć się więcej o algorytmie tablicy mieszającej oraz implementacji własnej metody
hashCode, zobacz Efektywny Kotlin, Temat 41: Szanuj kontrakt metody hashCode.Kolejną metodą generowaną przez modyfikator
data jest copy, który służy do tworzenia nowej instancji klasy, ale z konkretną modyfikacją. Idea jest bardzo prosta: jest to funkcja z parametrami dla każdej właściwości głównego konstruktora, ale każdy z tych parametrów ma wartość domyślną, tj. bieżącą wartość powiązanej właściwości.// Oto jak "pod maską" wygląda metoda copy generowana // przez modyfikator data dla klasy Person fun copy( id: Int = this.id, name: String = this.name, points: Int = this.points ) = Player(id, name, points)
To oznacza, że możemy wywołać
copy bez parametrów, aby stworzyć kopię naszego obiektu bez modyfikacji, ale możemy również określić nowe wartości dla właściwości, które chcemy zmienić.data class Player( val id: Int, val name: String, val points: Int ) fun main() { val p = Player(0, "Gecko", 9999) println(p.copy()) // Player(id=0, name=Gecko, points=9999) println(p.copy(id = 1, name = "Nowa nazwa")) // Player(id=1, name=Nowa nazwa, points=9999) println(p.copy(points = p.points + 1)) // Player(id=0, name=Gecko, points=10000) }
Zauważ, że
copy tworzy płytką kopię obiektu; jeśli więc nasz obiekt przechowuje zmienny stan, wszystkie kopie będą się odnosiły do tego samego zmiennego obiektu.data class StudentGrades( val studentId: String, // Źle: Nie używaj obiektów mutowalnych w klasach data val grades: MutableList<Int> ) fun main() { val grades1 = StudentGrades("1", mutableListOf()) val grades2 = grades1.copy(studentId = "2") println(grades1) // Grades(studentId=1, grades=[]) println(grades2) // Grades(studentId=2, grades=[]) grades1.grades.add(5) println(grades1) // Grades(studentId=1, grades=[5]) println(grades2) // Grades(studentId=2, grades=[5]) grades2.grades.add(1) println(grades1) // Grades(studentId=1, grades=[5, 1]) println(grades2) // Grades(studentId=2, grades=[5, 1]) }
Nie mamy tego problemu, gdy używamy
copy dla klas niemutowalnych, tj. klas mających tylko właściwości val, które przechowują niemutowalne wartości. copy został wprowadzony jako specjalne wsparcie dla niemutowalności (szczegóły można znaleźć w Efektywny Kotlin, Temat 1: Ogranicz mutowalność).data class StudentGrades( val studentId: String, val grades: List<Int> ) fun main() { var grades1 = StudentGrades("1", listOf()) var grades2 = grades1.copy(studentId = "2") println(grades1) // Grades(studentId=1, grades=[]) println(grades2) // Grades(studentId=2, grades=[]) grades1 = grades1.copy(grades = grades1.grades + 5) println(grades1) // Grades(studentId=1, grades=[5]) println(grades2) // Grades(studentId=2, grades=[]) grades2 = grades2.copy(grades = grades2.grades + 1) println(grades1) // Grades(studentId=1, grades=[5]) println(grades2) // Grades(studentId=2, grades=[1]) }
Zauważ, że data klasy nie nadają się dla obiektów, które muszą utrzymywać pewne wymogi dla mutowalnych właściwości. Na przykład, w przypadku poniższego przykładu
User, klasa nie byłaby w stanie zagwarantować, że wartości name i surname nie są puste, gdyby te zmienne były mutowalne (czyli zdefiniowane za pomocą var). Data klasy doskonale nadają się dla niemutowalnych właściwości, których ograniczenia można sprawdzić podczas tworzenia tych obiektów. W poniższym przykładzie możemy być pewni, że wartości name i surname nie są puste w instancji User.data class User( val name: String, val surname: String, ) { init { require(name.isNotBlank()) // rzuca wyjątek, jeśli name jest puste require(surname.isNotBlank()) // rzuca wyjątek, jeśli surname jest puste } }
Kotlin ma wsparcie dla destrukturyzacji opartej na pozycji. Polega to na tym, że na podstawie wartości pojedynczego obiektu definiujemy wartości wielu zmiennych. Aby dokonać destrukturyzcaji, musimy użyć słowa kluczowego
val lub var przed nawiasami okrągłymi, w których określamy zmienne, które chcemy zdefiniować.data class Player( val id: Int, val name: String, val points: Int ) fun main() { val player = Player(0, "Gecko", 9999) val (id, name, pts) = player println(id) // 0 println(name) // Gecko println(pts) // 9999 }
Ten mechanizm opiera się na pozycji i kolejności definiowania właściwości, a nie ich nazwach. Obiekt po prawej stronie znaku równości musi dostarczać funkcji
component1, component2, itp., a zmienne są przypisywane do wyników tych metod.val (id, name, pts) = player // kompiluje się do val id: Int = player.component1() val name: String = player.component2() val pts: Int = player.component3()
Ten kod działa, ponieważ modyfikator
data generuje funkcje componentN dla każdej właściwości konstruktora głównego, zgodnie z ich kolejnością w konstruktorze.To są obecnie wszystkie funkcjonalności, które dostarcza modyfikator
data. Nie używaj go, jeśli nie potrzebujesz toString, equals, hashCode, copy lub destrukturyzacji. Jeśli potrzebujesz niektórych z tych funkcjonalności dla klasy reprezentującej pakiet danych, użyj modyfikatora data zamiast implementować metody samodzielnie.Destrukturyzacja oparta na pozycji ma swoje zalety i wady. Największą zaletą jest to, że możemy nadawać zmiennym dowolne nazwy, więc możemy użyć nazw takich jak
country i city w poniższym przykładzie. Możemy też dekonstruować wszystko, co dostarcza funkcji componentN. Obejmuje to List i Map.Entry, które mają zdefiniowane funkcje componentN jako rozszerzenia:fun main() { val visited = listOf("Hiszpania", "Maroko", "Indie") val (first, second, third) = visited println("$first $second $third") // Hiszpania Maroko Indie val trip = mapOf( "Hiszpanii" to "Gran Canaria", "Maroko" to "Taghazout", "Indiach" to "Rishikesh" ) for ((country, city) in trip) { println("Odwiedziliśmy $city w $country") // Odwiedziliśmy Gran Canaria w Hiszpanii // Odwiedziliśmy Taghazout w Maroko // Odwiedziliśmy Rishikesh w Indiach } }
Z drugiej strony, destrukturyzacja oparta na pozycji jest niebezpieczna. Gdy kolejność lub liczba elementów w klasie danych ulegnie zmianie, musimy dostosować wszystkie destrukturyzacje tych obiektów. Korzystając z tej funkcjonalności, łatwo jest wprowadzić błędy do naszego kodu, gdy ulega zmianie kolejność właściwości głównego konstruktora.
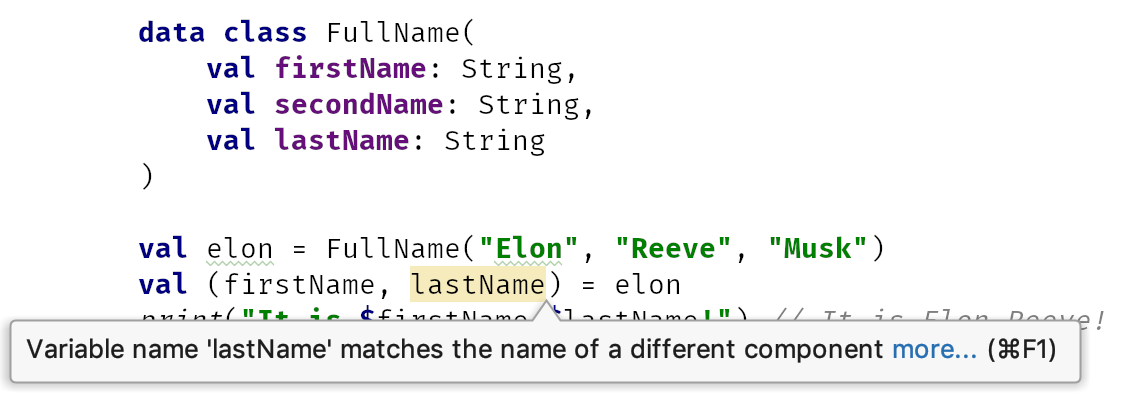
data class FullName( val firstName: String, val secondName: String, val lastName: String ) val elon = FullName("Elon", "Reeve", "Musk") val (name, surname) = elon print("To jest $name $surname!") // To jest Elon Reeve!
Musimy być ostrożni z destrukturyzacją. Przydatne jest stosowanie tych samych nazw co właściwości głównego konstruktora data klasy. W przypadku nieprawidłowej kolejności zostanie wyświetlone ostrzeżenie IntelliJ/Android Studio. Może być nawet przydatne uaktualnienie tego ostrzeżenia do błędu.
Destrukturyzacja pojedynczej wartości jest bardzo myląca. Zwłaszcza w wyrażeniach lambda3, gdzie nawiasy wokół argumentów w niektórych językach programowania są opcjonalne lub wymagane.
data class User( val name: String, val surname: String, ) fun main() { val users = listOf( User("Nicola", "Corti") ) users.forEach { u -> println(u) } // User(name=Nicola, surname=Corti) users.forEach { (u) -> println(u) } // Nicola }
Ideą stojącą za data klasami jest to, że reprezentują one zestaw danych; ich konstruktory pozwalają nam określić wszystkie te dane, a my możemy uzyskać do nich dostęp poprzez destrukturyzację lub kopiując je do innego obiektu za pomocą metody
copy. Dlatego tylko właściwości głównego konstruktora są brane pod uwagę przez te metody.data class Dog( val name: String, ) { // Zła praktyka, unikaj // zmiennych właściwości w klasach danych var trained = false } fun main() { val d1 = Dog("Cookie") d1.trained = true println(d1) // Dog(name=Cookie) // więc nic o właściwości trained val d2 = d1.copy() println(d1.trained) // true println(d2.trained) // false // więc wartość trained nie została skopiowana }
Data klasy powinny przechowywać wszystkie istotne właściwości w swoim głównym konstruktorze. W ciele klasy powinniśmy trzymać tylko nadmiarowe właściwości, czyli właściwości, których wartość jest obliczana na podstawie właściwości głównego konstruktora, takie jak
fullName, czyli właściwość obliczana na podstawie name i surname. Takie wartości są również ignorowane przez metody data klasy, ale ich wartość zawsze będzie poprawna, ponieważ będzie obliczana podczas tworzenia nowego obiektu.data class FullName( val name: String, val surname: String, ) { val fullName = "$name $surname" } fun main() { val d1 = FullName("Cookie", "Moskała") println(d1.fullName) // Cookie Moskała println(d1) // FullName(name=Cookie, surname=Moskała) val d2 = d1.copy() println(d2.fullName) // Cookie Moskała println(d2) // FullName(name=Cookie, surname=Moskała) }
Powinieneś również pamiętać, że data klasy muszą być finalne i dlatego nie mogą być używane jako nadrzędny typ w dziedziczeniu.
Data klasy oferują więcej niż to, co w innych językach dostarczają tuple (krotki). Historycznie Kotlin również wspierał tuple, ale zostały one usunięte z języka, ponieważ używanie data klas zostało uznane za lepszą praktykę4. Jedynymi pozostałymi tuplami są
Pair i Triple, które są po prostu zdefiniowanymi w bibliotece standardowej data klasami.data class Pair<out A, out B>( val first: A, val second: B ) : Serializable { override fun toString(): String = "($first, $second)" } data class Triple<out A, out B, out C>( val first: A, val second: B, val third: C ) : Serializable { override fun toString(): String = "($first, $second, $third)" }
Najłatwiejszym sposobem na utworzenie
Pair jest użycie funkcji to. Jest to infiksowa funkcja rozszerzająca dowolny typ, zdefiniowana w następujący sposób (omówimy zarówno typy generyczne, jak i rozszerzenia w późniejszych rozdziałach).infix fun <A, B> A.to(that: B): Pair<A, B> = Pair(this, that)
Dzięki modyfikatorowi infiks, metoda może być używana poprzez umieszczenie jej nazwy między argumentami, jak sugeruje nazwa infiks. Wynikowy
Pair jest typowany, więc wynikowym typem wyrażenia "ABC" to 123 jest Pair<String, Int>.fun main() { val p1: Pair<String, Int> = "ABC" to 123 println(p1) // (ABC, 123) val p2 = 'A' to 3.14 // typ p2 to Pair<Char, Double> println(p2) // (A, 123) val p3 = true to false // typ p3 to Pair<Boolean, Boolean> println(p3) // (true, false) }
Te krotki pozostały, ponieważ są bardzo użyteczne w lokalnych zastosowaniach, takich jak:
- Natychmiastowe nadawanie wartościom nazwy:
val (description, color) = when { degrees < 5 -> "zimno" to Color.BLUE degrees < 23 -> "umiarkowane" to Color.YELLOW else -> "gorąco" to Color.RED }
- Reprezentowanie agregatu, który nie jest znany z góry, co jest powszechnym przypadkiem w funkcjach biblioteki standardowej:
val (odd, even) = numbers.partition { it % 2 == 1 } val map = mapOf(1 to "San Francisco", 2 to "Amsterdam")
W innych przypadkach preferujemy użycie data klasy. Na przykład załóżmy, że potrzebujemy funkcji, która przetwarza pełne imię i nazwisko na imię i nazwisko. Ktoś może reprezentować to imię i nazwisko jako
Pair<String, String>:fun String.parseName(): Pair<String, String>? { val indexOfLastSpace = this.trim().lastIndexOf(' ') if (indexOfLastSpace < 0) return null val firstName = this.take(indexOfLastSpace) val lastName = this.drop(indexOfLastSpace) return Pair(firstName, lastName) } // Użycie fun main() { val fullName = "Marcin Moskała" val (firstName, lastName) = fullName.parseName() ?: return }
Problem polega na tym, że gdy ktoś czyta ten kod, nie jest jasne, że
Pair<String, String> reprezentuje pełne imię i nazwisko. Co więcej, nie jest jasne, jaka jest kolejność wartości, dlatego ktoś może myśleć, że najpierw jest nazwisko:val fullName = "Marcin Moskała" val (lastName, firstName) = fullName.parseName() ?: return print("Jego imię to $firstName") // Jego imię to Moskała
Aby uczynić użycie bezpieczniejszym i funkcję łatwiejszą do odczytania, powinniśmy użyć data klasy:
data class FullName( val firstName: String, val lastName: String ) fun String.parseName(): FullName? { val indexOfLastSpace = this.trim().lastIndexOf(' ') if (indexOfLastSpace < 0) return null val firstName = this.take(indexOfLastSpace) val lastName = this.drop(indexOfLastSpace) return FullName(firstName, lastName) } // Użycie fun main() { val fullName = "Marcin Moskała" val (firstName, lastName) = fullName.parseName() ?: return print("Jego imię to $firstName $lastName") // Jego imię to Marcin Moskała }
To prawie nic nie kosztuje i znacznie poprawia czytelność i czystość kodu:
- Typ zwracany tej funkcji jest łatwiejszy do zinterpretowania.
- Typ zwracany jest krótszy i łatwiejszy do przekazania dalej.
- Jeśli użytkownik destrukturyzuje zmienne o poprawnych nazwach, ale w niewłaściwych pozycjach, ostrzeżenie zostanie wyświetlone w IntelliJ.
Jeśli nie chcesz, aby ta klasa miała szerszy zakres, możesz ograniczyć jej widoczność. Może być nawet prywatna, jeśli potrzebujesz jej tylko do lokalnego przetwarzania w pojedynczym pliku lub klasie. Warto używać klas danych zamiast
Pair i Triple. Klasy w Kotlinie są tanie, więc nie bój się ich używać w swoich projektach.W tym rozdziale poznaliśmy
Any, które jest nadklasą wszystkich klas. Dowiedzieliśmy się także o metodach zdefiniowanych przez Any: equals, hashCode i toString. Poznaliśmy również dwa główne typy obiektów. Zwykłe obiekty są uważane za unikalne i nie ujawniają swoich szczegółów. Obiekty data klasy, które tworzyliśmy przy pomocy modyfikatora data, reprezentują zbiory danych. Są równe, gdy przechowują te same dane. Po przekształceniu na string wyświetlają wszystkie swoje dane. Dodatkowo obsługują destrukturyzację i tworzenie kopii za pomocą metody copy. Dwie generyczne data klasy w Kotlinie to Pair i Triple, ale (z wyjątkiem pewnych przypadków) wolimy używać lepiej nazwanych data klas zamiast nich. Ponadto, ze względów bezpieczeństwa, gdy destrukturyzujemy data klasę, wolimy dopasować nazwy zmiennych do nazw parametrów.Teraz przejdźmy do rozdziału poświęconego specjalnej składni Kotlina, która pozwala nam tworzyć obiekty bez definiowania klasy.
-
Więc
Anyjest analogiczne doObjectw Javie, JavaScripcie lub C#. W C++ nie ma bezpośredniego odpowiednika. ↩ - Są to Temat 42: Szanuj kontrakt equals oraz Temat 43: Szanuj kontrakt hashCode. ↩
- O wyrażeniach lambda więcej w książce Funkcyjny Kotlin. ↩
-
Kotlin miał wsparcie dla tupli, gdy był jeszcze w wersji beta. Mogliśmy zdefiniować krotkę za pomocą nawiasów i zestawu typów, takich jak
(Int, String, String, Long). To, co osiągnęliśmy, zachowywało się podobnie jak data klasy, ale było znacznie mniej czytelne. Korzystanie z tupli jest kuszące, ale korzystanie z data klas jest prawie zawsze lepsze. Dlatego tuple zostały usunięte, a pozostały tylkoPairiTriple. ↩
