

In Kotlin, we design programs as modules, each of which comprises various elements, such as classes, objects, functions, type aliases, and top-level properties. Some of these elements can hold a state, for instance, by having a read-write var property or by composing a mutable object:
var a = 10 val list: MutableList<Int> = mutableListOf()
When an element holds a state, the way it behaves depends not only on how you use it but also on its history. A typical example of a class with a state is a bank account (class) that has some money balance (state):
class BankAccount { var balance = 0.0 private set fun deposit(depositAmount: Double) { balance += depositAmount } @Throws(InsufficientFunds::class) fun withdraw(withdrawAmount: Double) { if (balance < withdrawAmount) { throw InsufficientFunds() } balance -= withdrawAmount } } class InsufficientFunds : Exception() val account = BankAccount() println(account.balance) // 0.0 account.deposit(100.0) println(account.balance) // 100.0 account.withdraw(50.0) println(account.balance) // 50.0
Here
BankAccount has a state that represents how much money is in this account. Keeping a state is a double-edged sword. On the one hand, it is very useful because it makes it possible to represent elements that change over time. On the other hand, state management is hard because:- It is harder to understand and debug a program with many mutating points. The relationship between these mutations needs to be understood, and it becomes harder to track their changes as more occur. A class with many mutually dependent mutating points is often really hard to understand and modify. This is especially problematic in unexpected situations or errors.
- Mutability makes it harder to reason about code. The state of an immutable element is clear, but a mutable state is much harder to comprehend. It is harder to reason about what its value is as it might change at any point; therefore, even though we might have checked a moment ago, it might have already changed.
class NeuralNetwork { var syn0: INDArray? = null var syn1: INDArray? = null var syn2: INDArray? = null var history: INDArray? = null var resultl1: INDArray? = null var resultl2: INDArray? = null var resultl3: INDArray? = null var resultl0: INDArray? = null // ... }
- A mutable state requires proper synchronization in multithreaded programs. Every mutation is a potential conflict. We will discuss this in more detail later in the next item. For now, let’s just say that it is hard to manage a shared state.
class UserRepository { private val storedUsers: MutableMap<Int, String> = mutableMapOf() private val lock = Any() fun loadAll(): Map<Int, String> = synchronized(lock){ storedUsers.toMap() } fun add(id: Int, name: String) = synchronized(lock){ storedUsers[id] = name } //... }
- Mutability can generate unintended side effects. When we operate on mutable objects, it is common for one part of our system to mutate an object, causing unintended side effects in a completely different part of the system that operates on those objects.
class UserRepository { private val storedUsers: MutableMap<Int, String> = mutableMapOf() fun loadAll(): Map<Int, String> = storedUsers fun add(id: Int, name: String) { storedUsers[id] = name } //... } val userRepository = UserRepository() val users: Map<Int, String> = userRepository.loadAll() print(users) // {} userRepository.add(123, "ABC") print(users) // {123=ABC}
- Mutable elements are harder to test. We need to test every possible state; the more mutability there is, the more states there are to check. Moreover, the number of states we need to test generally grows exponentially with the number of mutation points in the same object or file, as we need to consider all combinations of possible states.
- When a state mutates, other classes often need to be notified about this change. For instance, when we add a mutable element to a sorted list, if this element changes, we need to sort this list again. We will see more examples of this class of problems later in this item.
data class UserId(var number: Int) : Comparable<UserId> { override fun compareTo(other: UserId): Int = compareValuesBy(this, other) { it.number } } fun main() { val set = TreeSet<UserId>() val userId = UserId(0) set.add(userId) set.add(UserId(1)) set.add(UserId(2)) userId.number = 3 println(set.contains(userId)) // false }
The drawbacks of mutability are so numerous that there are languages that do not allow state mutation at all. These are purely functional languages, a well-known example of which is Haskell. However, such languages are rarely used for mainstream development since it's very hard to do programming with such limited mutability. A mutating state is a very useful way to represent the state of real-world systems. I recommend using mutability, but only where it gives us some real value. When possible, it is better to limit it. The good news is that Kotlin has good support for limiting mutability.
Kotlin is designed to support limiting mutability: it is easy to make immutable objects or to keep properties immutable. This is a result of many features and characteristics of this language, the most important of which are:
-
Read-only properties
val, - Separation between mutable and read-only collections,
-
copyin data classes.
Let’s discuss these one by one.
In Kotlin, we can make each property a read-only
val (like "value") or a read-write var (like "variable"). Read-only (val) properties cannot be set to a new value:val a = 10 a = 20 // ERROR
Notice that read-only properties are not necessarily immutable or final. A read-only property can hold a mutable object:
val list = mutableListOf(1, 2, 3) list.add(4) print(list) // [1, 2, 3, 4]
A read-only property can also be defined using a custom getter that might depend on another property:
var name: String = "Marcin" var surname: String = "Moskała" val fullName get() = "$name $surname" fun main() { println(fullName) // Marcin Moskała name = "Maja" println(fullName) // Maja Moskała }
In the above example, the value returned by the
val changes because when we define a custom getter, it will be called every time we ask for the value.fun calculate(): Int { print("Calculating... ") return 42 } val fizz = calculate() // Calculating... val buzz get() = calculate() fun main() { print(fizz) // 42 print(fizz) // 42 print(buzz) // Calculating... 42 print(buzz) // Calculating... 42 }
This trait, namely that properties in Kotlin are encapsulated by default and can have custom accessors (getters and setters), is very important in Kotlin because it gives us flexibility when we change or define an API. This will be described in detail in Item 15: Properties should represent state, not behavior. The core idea though is that
val does not provide mutation points because, under the hood, it is only a getter. var is both a getter and a setter. That’s why we can override val with var:interface StateFlow<out T> : SharedFlow<T> { val value: T } interface MutableStateFlow<T> : StateFlow<T>, MutableSharedFlow<T> { override var value: T fun compareAndSet(expect: T, update: T): Boolean }
Values of read-only
val properties can change, but such properties do not offer a mutation point, and this is the main source of problems when we need to synchronize or reason about a program. This is why we generally prefer val over var.Remember that
val doesn't mean immutable. It can be defined by a getter or a delegate. This fact gives us more freedom to change a final property into a property represented by a getter. However, when we don’t need to use anything more complicated, we should define final properties, which are easier to reason about as their value is stated next to their definition. They are also better supported in Kotlin. For instance, they can be smart-casted:val name: String? = "Márton" val surname: String = "Braun" val fullName: String? get() = name?.let { "$it $surname" } val fullName2: String? = name?.let { "$it $surname" } fun main() { if (fullName != null) { println(fullName.length) // ERROR } if (fullName2 != null) { println(fullName2.length) // 12 } }
Smart casting is impossible for
fullName because it is defined using a getter; so, when checked it might give a different value than it does during use (for instance, if some other thread sets name). Non-local properties can be smart-casted only when they are final and do not have a custom getter.Similarly, just as Kotlin separates read-write and read-only properties, Kotlin also separates read-write and read-only collections. This is achieved thanks to how the hierarchy of collections was designed. Take a look at the diagram presenting the hierarchy of collections in Kotlin. On the left side, you can see the
Iterable, Collection, Set, and List interfaces, all of which are read-only. This means that they do not have any methods that would allow modification. On the right side, you can see the MutableIterable, MutableCollection, MutableSet, and MutableList interfaces, all of which represent mutable collections. Notice that each mutable interface extends the corresponding read-only interface and adds methods that allow mutation. This is similar to how properties work. A read-only property means just a getter, while a read-write property means both a getter and a setter.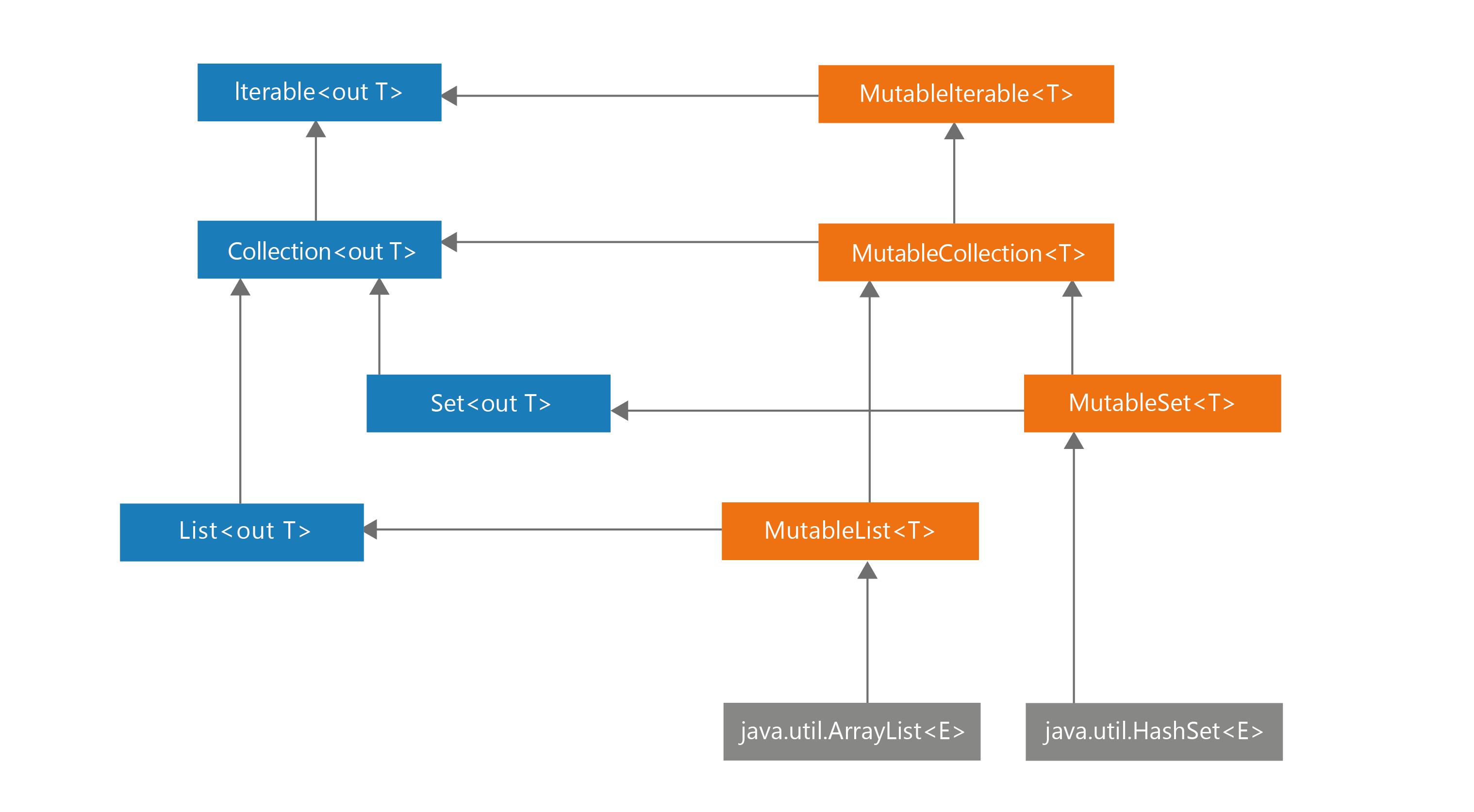
The hierarchy of collection interfaces in Kotlin and the actual objects that can be used in Kotlin/JVM. On the left side, the interfaces are read-only. On the right side, the collections and interfaces are mutable.
Read-only collections are not necessarily immutable. They are often mutable, but they cannot be mutated because they are hidden behind read-only interfaces. For instance, the
Iterable<T>.map and Iterable<T>.filter functions return ArrayList (which is a mutable list) as a List, which is a read-only interface. In the snippet below, you can see a simplified implementation of Iterable<T>.map from stdlib.inline fun <T, R> Iterable<T>.map( transformation: (T) -> R ): List<R> { val size = if (this is Collection) size else 10 val list = ArrayList<R>(size) for (elem in this) { list.add(transformation(elem)) } return list }
The design choice to make these collection interfaces read-only instead of truly immutable is very important because it gives us much more freedom. Under the hood, any actual collection can be returned as long as it satisfies the interface; therefore, we can use platform-specific collections.
The safety of this approach is close to what is achieved by having immutable collections. The only risk is when a developer tries to "hack the system" by performing down-casting. This is something that should never be allowed in Kotlin projects. We should be able to trust that when we return a list as read-only, it is only used to read it. This is part of the contract. More about this in Part 2.
Down-casting collections not only breaks their contract and depends on implementation instead of abstraction (as we should), but it is also insecure and can lead to surprising consequences. Take a look at this code:
val list = listOf(1, 2, 3) // DON’T DO THIS! if (list is MutableList) { list.add(4) }
The result of this operation depends on our compilation target. On JVM,
listOf returns an instance of Arrays.ArrayList that implements the Java List interface, which has methods like add and set, so it translates to the Kotlin MutableList interface. However, Arrays.ArrayList does not implement add and some other operations that mutate objects. This is why the result of this code is UnsupportedOperationException. On different platforms, the same code could give us different results.What is more, there is no guarantee how this will behave a year from now. The underlying collections might change; they might be replaced with truly immutable collections implemented in Kotlin that do not implement
MutableList at all. Nothing is guaranteed. This is why down-casting read-only collections to mutable ones should never happen in Kotlin. If you need to transform from read-only to mutable, you should use the List.toMutableList function, which creates a copy that you can then modify:val list = listOf(1, 2, 3) val mutableList = list.toMutableList() mutableList.add(4)
This way does not break any contract, and it is safer for us as we can feel safe that when we expose something as
List it won’t be modified from outside.There are many reasons to prefer immutable objects – objects that do not change their internal state, like
String or Int. In addition to the previously given reasons why we generally prefer less mutability, immutable objects have their own advantages:- They are easier to reason about since their state stays the same once they have been created.
- Immutability makes it easier to parallelize a program as there are no conflicts among shared objects.
- References to immutable objects can be cached as they will not change.
- We do not need to make defensive copies of immutable objects. When we do copy immutable objects, we do not need to make a deep copy.
- Immutable objects are the perfect material to construct other objects, both mutable and immutable. We can still decide where mutability is allowed, and it is easier to operate on immutable objects.
- We can add them to sets or use them as keys in maps, unlike mutable objects, which shouldn't be used this way. This is because both these collections use hash tables under the hood in Kotlin/JVM. When we modify an element that is already classified in a hash table, its classification might not be correct anymore, therefore we won’t be able to find it. This problem will be described in detail in Item 43: Respect the contract of hashCode. We have a similar issue when a collection is sorted.
data class User(var name: String) val user = User("Alex") val map = mutableMapOf<User, String>() map[user] = "Some value" println(map[user]) // Some value user.name = "Bob" println(map[user]) // null
At the last check, the collection returned false even though that person is in this set. It couldn't be found because it is at an incorrect position.
As you can see, mutable objects are more dangerous and less predictable. On the other hand, the biggest problem of immutable objects is that data sometimes needs to change. The solution is that immutable objects should have methods that produce a copy of this object with the desired changes applied. For instance,
Int is immutable, and it has many methods like plus or minus that do not modify it but instead return a new Int, which is the result of the operation. Iterable is read-only, and collection processing functions like map or filter do not modify it but instead return a new collection. The same can be applied to our immutable objects. For instance, let’s say that we have an immutable class User, and we need to allow its surname to change. We can support it with the withSurname method, which produces a copy with a particular property changed:class User( val name: String, val surname: String ) { fun withSurname(surname: String) = User(name, surname) } var user = User("Maja", "Markiewicz") user = user.withSurname("Moskała") print(user) // User(name=Maja, surname=Moskała)
Writing such functions is possible but it’s also tedious if we need one for every property. So, here comes the
data modifier to the rescue. One of the methods it generates is copy. The method copy creates a new instance in which all primary constructor properties are, by default, the same as in the previous one. New values can be specified as well. copy and other methods generated by the data modifier are described in detail in Item 37: Use the data modifier to represent a bundle of data. Here is a simple example showing how it works:data class User( val name: String, val surname: String ) var user = User("Maja", "Markiewicz") user = user.copy(surname = "Moskała") print(user) // User(name=Maja, surname=Moskała)
This elegant and universal solution supports making data model classes immutable. This way is less efficient than just using a mutable object instead, but it is safer and has all the other advantages of immutable objects. Therefore it should be preferred by default.
Let’s say that we need to represent a mutating list. There are two ways we can achieve this: either by using a mutable collection or by using the read-write
var property:val list1: MutableList<Int> = mutableListOf() var list2: List<Int> = listOf()
Both properties can be modified, but in different ways:
list1.add(1) list2 = list2 + 1
Both of these ways can be replaced with the plus-assign operator, but each of them is translated into a different behavior:
list1 += 1 // Translates to list1.plusAssign(1) list2 += 1 // Translates to list2 = list2.plus(1)
Both these ways are correct, and both have their pros and cons. They both have a single mutating point, but each is located in a different place. In the first one, the mutation takes place on the concrete list implementation. We might depend on the fact that the collection has proper synchronization in the case of multithreading, if we used a collection with support for concurrency1. In the second one, we need to implement the synchronization ourselves, but the overall safety is better because the mutating point is only a single property. However, in the case of a lack of synchronization, remember that we might still lose some elements:
var list = listOf<Int>() for (i in 1..1000) { thread { list = list + i } } Thread.sleep(1000) print(list.size) // Very unlikely to be 1000, // every time a different number, like for instance 911
Using a mutable property instead of a mutable list allows us to track how this property changes when we define a custom setter or use a delegate (which uses a custom setter). For instance, when we use an observable delegate, we can log every change of a list:
var names by observable(listOf<String>()) { _, old, new -> println("Names changed from $old to $new") } names += "Fabio" // Names changed from [] to [Fabio] names += "Bill" // Names changed from [Fabio] to [Fabio, Bill]
To make this possible for a mutable collection, we would need a special observable implementation of the collection. For read-only collections in mutable properties, it is also easier to control how they change as there is only a setter instead of multiple methods mutating this object, and we can make it private:
var announcements = listOf<Announcement>() private set
In short, using mutable collections is more efficient when we mutate them more often than we need to expose them (which requires making a defensive copy). This is a more common situation, so mutable collections are often considered more efficient.
class UserRepository { private val storedUsers: MutableMap<Int, String> = ConcurrentHashMap() fun loadAll(): Map<Int, String> = storedUsers.toMap() // Expensive fun add(id: Int, name: String) { storedUsers[id] = name // Cheap } //... }
On the other hand, read-only collections with mutable properties are easier to control and synchronize. They require no defensive copies, and we can observe their mutations.
class UserRepository { private var storedUsers: Map<Int, String> = mapOf() fun loadAll(): Map<Int, String> = storedUsers // Cheap fun add(id: Int, name: String) { storedUsers += id to name // Expensive } //... }
Notice that the worst solution is to have both a mutating property and a mutable collection:
// Don’t do that var list3 = mutableListOf<Int>()
The general rule is that one should not create unnecessary ways to mutate a state. Every way to mutate a state is a cost. Every mutation point needs to be understood and maintained. We prefer to limit mutability.
In this chapter, we’ve learned why it is important to limit mutability and to prefer immutable objects. We’ve seen that Kotlin gives us many tools that support limiting mutability. We should use them to limit mutation points. The simple rules are:
- Prefer
valovervar. - Prefer an immutable property over a mutable one.
- Prefer objects and classes that are immutable over mutable ones.
- If you need immutable objects to change, consider making them data classes and using
copy. - When you hold a state, prefer read-only over mutable collections.
- Design your mutation points wisely and do not produce unnecessary ones.
There are some exceptions to these rules. Sometimes we prefer mutable objects because they are more efficient. Such optimizations should be preferred only in performance-critical parts of our code (Part 3: Efficiency); when we use them, we need to remember that mutability requires more attention when we prepare it for multithreading. The baseline is that we should limit mutability.
- We will discuss such collections in the next item. ↩




