

Another well-known function for collections is
flatMap. In the case of collections, it is similar to a map, but the transformation function needs to return a collection that is then flattened. For example, if you have a list of departments, each of which has a list of employees, you can use flatMap to make a list of all employees in all departments.val allEmployees: List<Employee> = departments .flatMap { department -> department.employees } // If we had used map, we would have a list of lists instead val listOfListsOfEmployee: List<List<Employee>> = departments .map { department -> department.employees }
How should
flatMap look on a flow? It seems intuitive that we might expect its transformation function to return a flow that should then be flattened. The problem is that flow elements can be spread in time. So, should the flow produced from the second element wait for the one produced from the first one, or should it process them concurrently? Since there is no clear answer, there is no flatMap function for Flow, but instead there are flatMapConcat, flatMapMerge and flatMapLatest.The
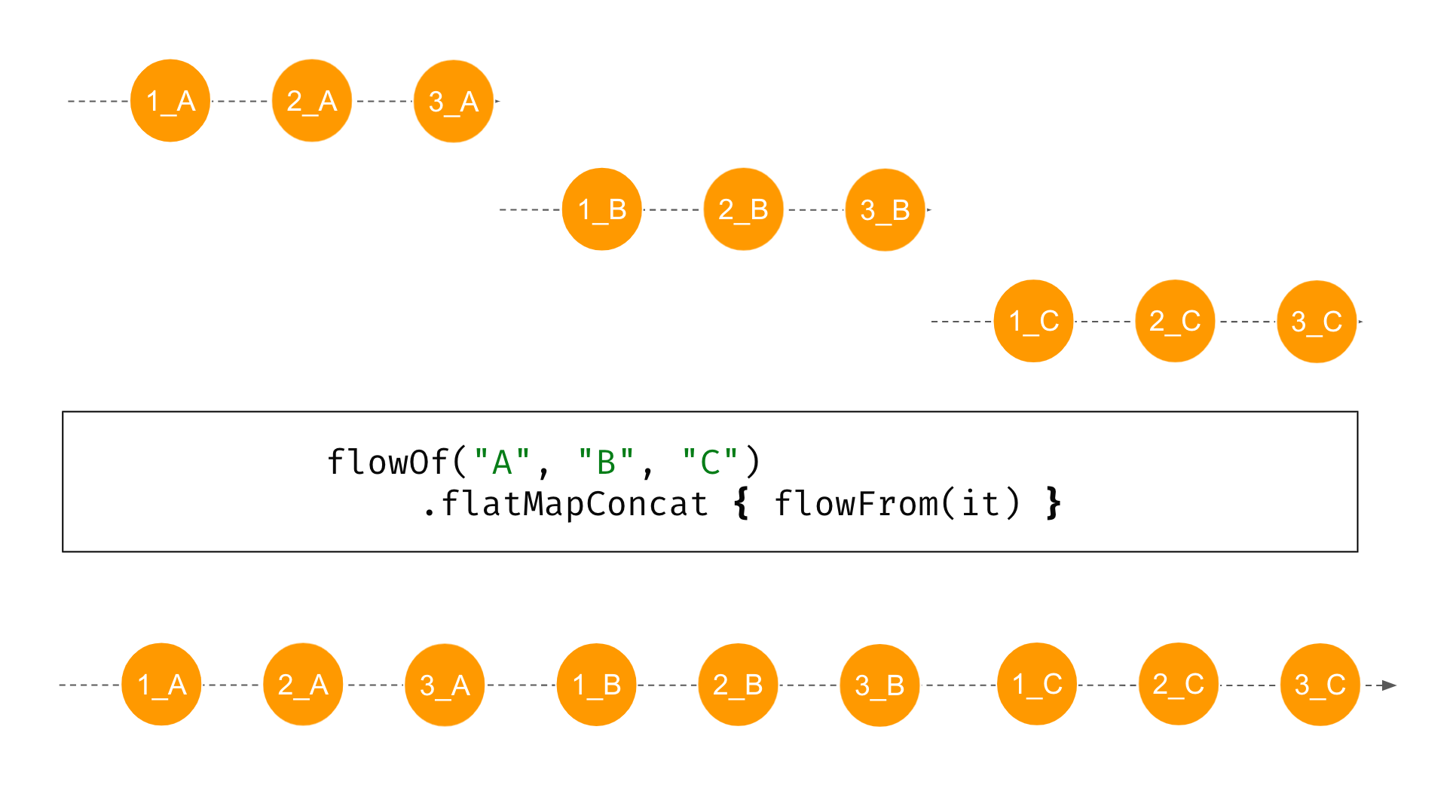
flatMapConcat function is a sequential option, that do not introduce any asynchrony. Only after the first flow is done, the second one can start. In the following example, we make a flow from the characters "A", "B", and "C". The flow produced by each of them includes these characters and the numbers 1, 2, and 3, with a 1-second delay in between.import kotlinx.coroutines.delay import kotlinx.coroutines.flow.* fun flowFrom(elem: String) = flowOf(1, 2, 3) .onEach { delay(1000) } .map { "${it}_${elem} " } suspend fun main() { flowOf("A", "B", "C") .flatMapConcat { flowFrom(it) } .collect { println(it) } } // (1 sec) // 1_A // (1 sec) // 2_A // (1 sec) // 3_A // (1 sec) // 1_B // (1 sec) // 2_B // (1 sec) // 3_B // (1 sec) // 1_C // (1 sec) // 2_C // (1 sec) // 3_C
The second mentioned function,
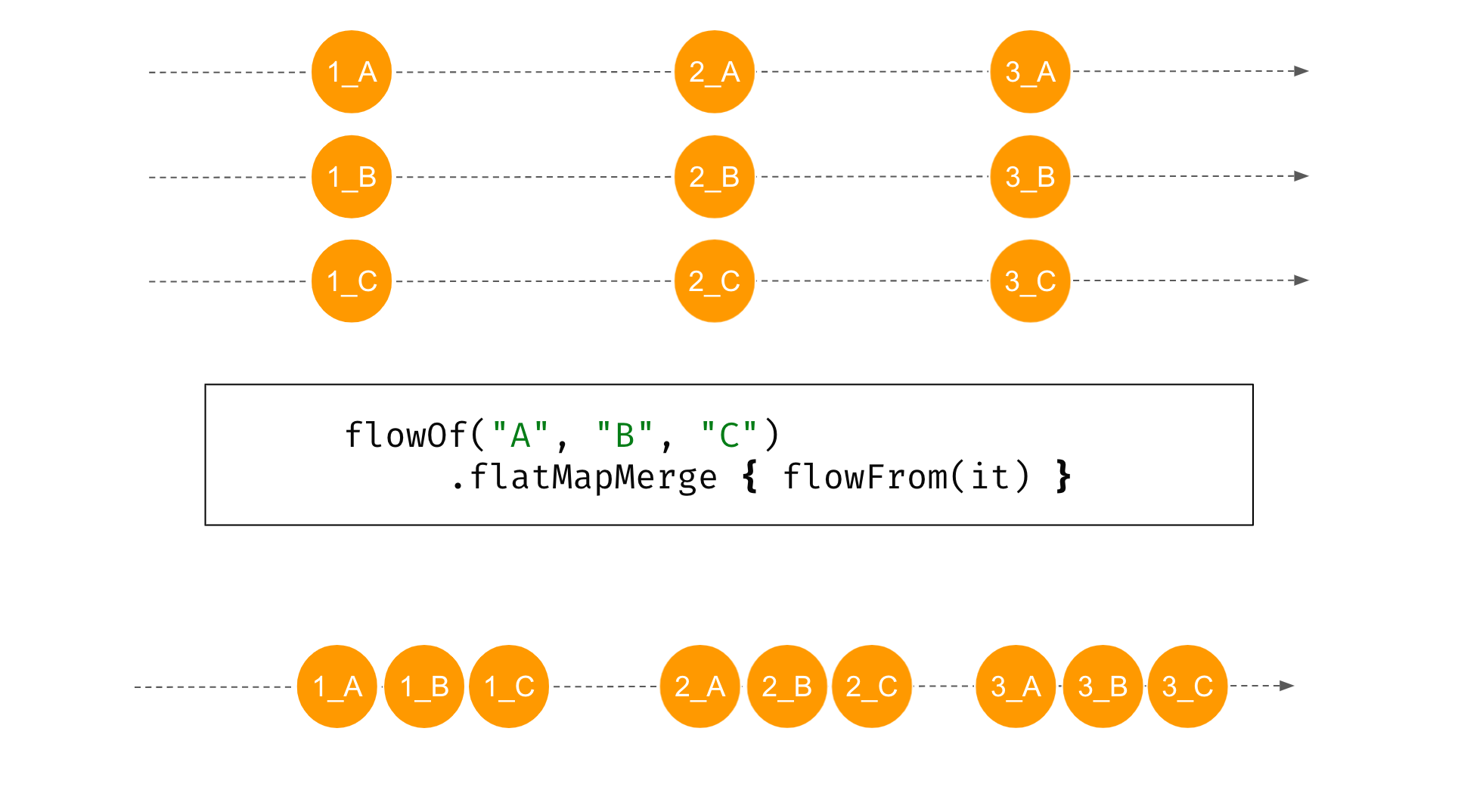
flatMapMerge, introduces asynchrony. Each flow is started on a new coroutine, so they can be processed concurrently. The following example is the same as the previous one, but with flatMapMerge instead of flatMapConcat.import kotlinx.coroutines.delay import kotlinx.coroutines.flow.* fun flowFrom(elem: String) = flowOf(1, 2, 3) .onEach { delay(1000) } .map { "${it}_${elem} " } suspend fun main() { flowOf("A", "B", "C") .flatMapMerge { flowFrom(it) } .collect { println(it) } } // (order may vary) // (1 sec) // 1_A // 1_B // 1_C // (1 sec) // 2_A // 2_B // 2_C // (1 sec) // 3_A // 3_B // 3_C
The number of flows that can be concurrently processed can be set using the
concurrency parameter. The default value of this parameter is 16, but it can be changed in the JVM using the DEFAULT_CONCURRENCY_PROPERTY_NAME property. Beware of this default limitation because if you use flatMapMerge on a flow with many elements, only 16 will be processed at the same time.import kotlinx.coroutines.delay import kotlinx.coroutines.flow.* fun flowFrom(elem: String) = flowOf(1, 2, 3) .onEach { delay(1000) } .map { "${it}_${elem} " } suspend fun main() { flowOf("A", "B", "C") .flatMapMerge(concurrency = 2) { flowFrom(it) } .collect { println(it) } } // (1 sec) // 1_A // 1_B // (1 sec) // 2_A // 2_B // (1 sec) // 3_A // 3_B // (1 sec) // 1_C // (1 sec) // 2_C // (1 sec) // 3_C
The typical use of
flatMapMerge is when we need to request data for each element in a flow. For instance, we have a list of categories, and you need to request offers for each of them. You already know that you can do this with the async function. There are two advantages of using a flow with flatMapMerge instead:- we can control the concurrency parameter and decide how many categories we want to fetch at the same time (to avoid sending hundreds of requests at the same time);
- we can return
Flowand send the next elements as they arrive (so, on the function-use side, they can be handled immediately).
suspend fun getOffers( categories: List<Category> ): List<Offer> = coroutineScope { categories .map { async { api.requestOffers(it) } } .flatMap { it.await() } } // A better solution suspend fun getOffers( categories: List<Category> ): Flow<Offer> = categories .asFlow() .flatMapMerge(concurrency = 20) { flow { emit(api.requestOffers(it)) } // or suspend { api.requestOffers(it) }.asFlow() }
Notice that in the above example I needed to wrap
api.requestOffers(it) with flow builder. You cannot use flowOf instead, because then suspension would happen during the creation of the flow, not during its collection. flatMapMerge introduces asynchrony only for the collection of the flows, not for their creation.flatMapMerge has a special behavior for the concurrency parameter set to 1. In this case, it behaves like flatMapConcat. That is not consistent with the other values of the concurrency parameter passed to flatMapMerge, because flatMapConcat operates on one coroutine only (for producing and collecting its flows), and flatMapMerge operates on one coroutine for producing and the number of coroutines for collecting constrained by the concurrency parameter (so for concurrency set to 1 it should operate on 2 coroutines, but in the reality, it operates on only 1).The last function is
flatMapLatest. It forgets about the previous flow once a new one appears. With every new value, the previous flow processing is forgotten. So, if there is no delay between "A", "B" and "C", then you will only see "1_C", "2_C", and "3_C".import kotlinx.coroutines.delay import kotlinx.coroutines.flow.* fun flowFrom(elem: String) = flowOf(1, 2, 3) .onEach { delay(1000) } .map { "${it}_${elem} " } suspend fun main() { flowOf("A", "B", "C") .flatMapLatest { flowFrom(it) } .collect { println(it) } } // (1 sec) // 1_C // (1 sec) // 2_C // (1 sec) // 3_C
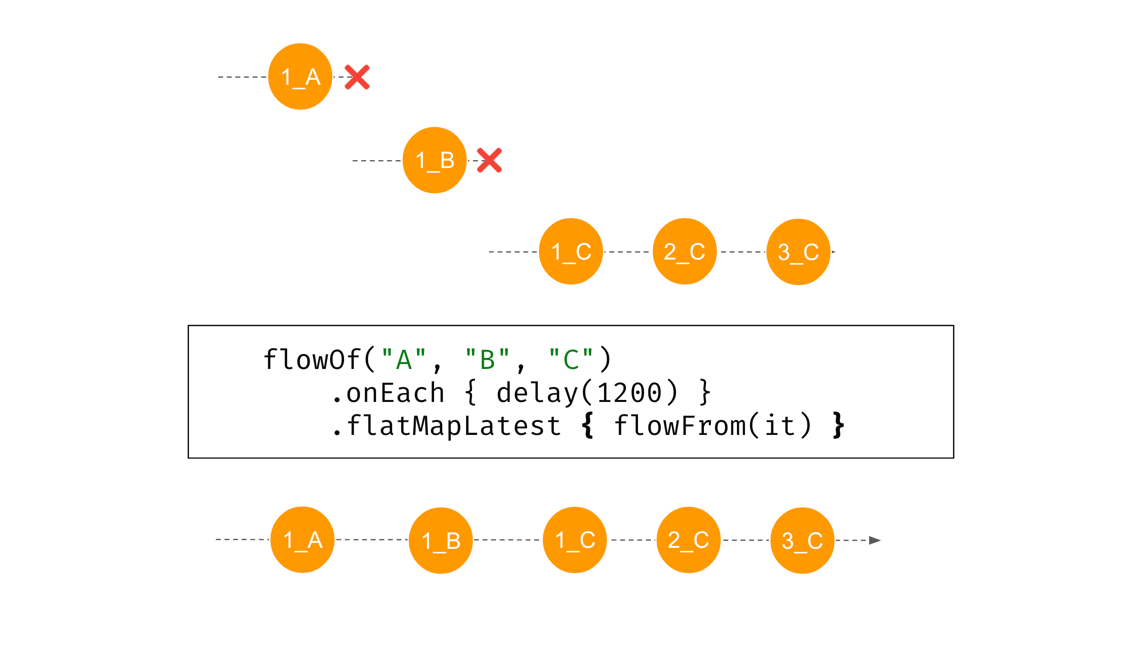
It gets more interesting when the elements from the initial flow are delayed. What happens in the example below is that (after 1.2 sec) "A" starts its flow, which was created using
flowFrom. This flow produces an element "1_A" in 1 second, but 200 ms later "B" appears and this previous flow is closed and forgotten. "B" flow managed to produce "1_B" when "C" appeared and started producing its flow. This one will finally produce elements "1_C", "2_C", and "3_C", with a 1-second delay in between.import kotlinx.coroutines.delay import kotlinx.coroutines.flow.* fun flowFrom(elem: String) = flowOf(1, 2, 3) .onEach { delay(1000) } .map { "${it}_${elem} " } suspend fun main() { flowOf("A", "B", "C") .onEach { delay(1200) } .flatMapLatest { flowFrom(it) } .collect { println(it) } } // (2.2 sec) // 1_A // (1.2 sec) // 1_B // (1.2 sec) // 1_C // (1 sec) // 2_C // (1 sec) // 3_C
In Android,
flatMapLatest is useful when you have a flow of user inputs and you want to process only the latest one. For instance, you have a flow of search queries and you want to fetch search results only for the latest query. In such a case, we often use debounce, which will wait for a certain time before processing the latest value. It will be explained in the next chapter.val productSearchResults = searchQueryFlow .debounce(300.milliseconds) .flatMapLatest { query -> fetchSearchResults(query) } .stateIn( scope = viewModelScope, started = SharingStarted.Lazily, initialValue = emptyList() )


