

Це фрагмент книги Python з нуля, яка допоможе вам навчитися програмуванню з нуля. Ви можете знайти його на Allegro, Empik та в інтернет-книгарнях.
Ще одне важливе застосуванняя програмування — це збір інформації, наприклад з інтернету. Створюються програми, які називаються ботами, які відвідують різні вебсайти та збирають дані. Такий бот міг би, наприклад, відвідувати певний маркетплейс і збирати інформацію про ціни на різні товари, а потім порівнювати їх із цінами в інших місцях або переглядати, як вони змінюються з часом. Такі боти часто пишуться на Python.
Погляньмо, як може виглядати такий збір даних. Перегляньмо заголовки блогів і новинних вебсайтів. Я почну з популярного блогу Wait but why.

Назви заголовків можна було б взяти безпосередньо з домашньої сторінки, але дозволь мені поділитися дещо простішим прийомом. У більшості блогів є сторінка під назвою канал RSS (RSS feed), яка надає перелік останніх публікацій. Ми використаємо це, після чого зчитаємо заголовки статей за допомогою пакета
feedparser.import feedparser rss = feedparser.parse("http://waitbutwhy.com/rss") entry = rss.entries[1] titles = [feed.title for feed in rss.entries] for title in titles: print(title) # Mailbag #2 # The Big and the Small # You Won’t Believe My Morning # ...
Так само ми могли б зчитати їхній зміст або посилання на зображення, які ілюструють ці статті.
RSS-сторінки зазвичай мають обмеження на кількість представлених публікацій. Тому, якщо ми хочемо завантажити більше заголовків або взяти заголовки з рейтингу найпопулярніших статей, нам доведеться робити якісь операції зі сторінкою. Я покажу це на прикладі positive.news — вебсайту, який, на відміну від більшості ЗМІ, зосереджується на позитивних світових новинах.
Тут ми використаємо пакети:
urlopen для завантаження вмісту вебсайту, та BeautifulSoup для пошуку конкретних елементів на цій сторінці. Я скористався опцією "Перевірити" в Google Chrome і виявив, що заголовки містяться в елементах типу а, з класом card__title 1.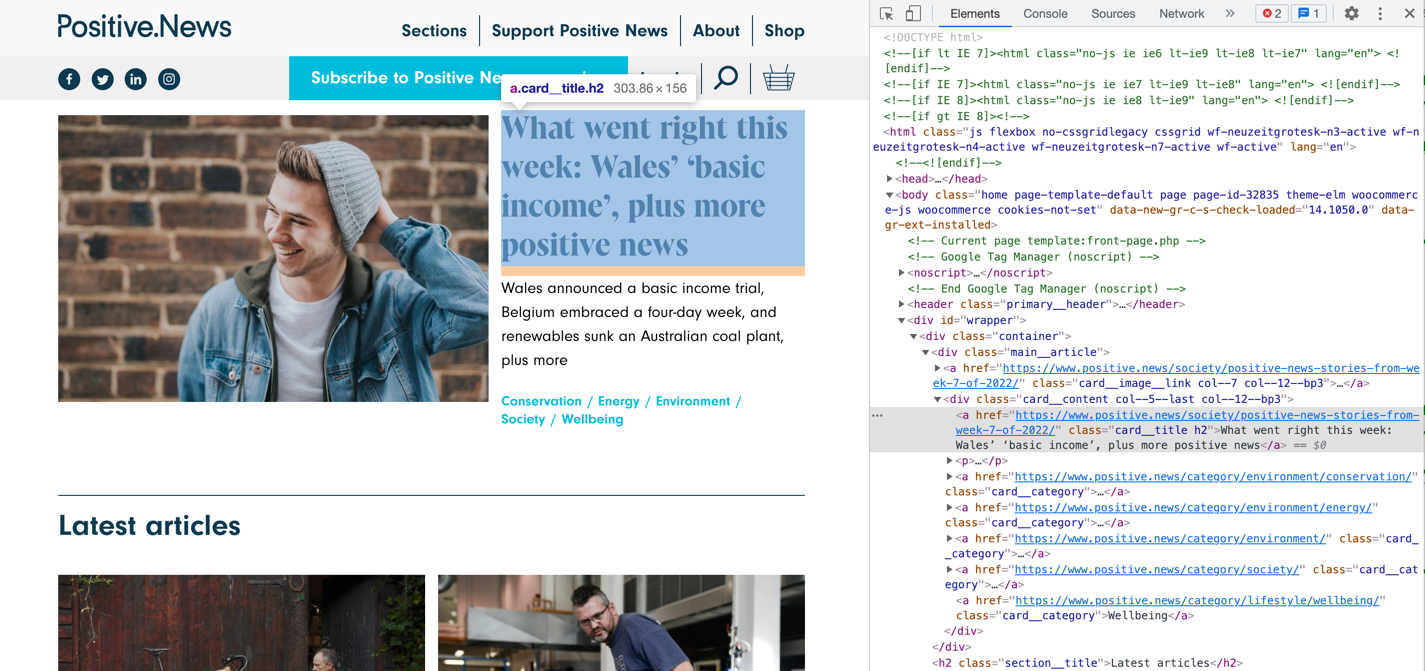
Завдяки цьому їх легко знайти та відобразити.
from bs4 import BeautifulSoup from urllib.request import urlopen html = urlopen("https://www.positive.news/").read() soup = BeautifulSoup(html, "html.parser") titles_elem = soup\ .find_all("a", {"class": "card__title"}) for title in titles_elem: print(title.text) # What went right this week: Wales’ ‘basic income’, ... # The bicycles that grow on trees # The plan to recycle Britain’s waste glass, ...
За допомогою цих інструментів ми могли б, наприклад, написати програму, яка час від часу перевірятиме, чи з’явилася нова стаття на сайтах, які нас цікавлять.
У практичних застосуваннях програми для збору даних дещо складніші. Вони постійно досліджують різні сторінки в пошуках потрібної інформації. Однак це просто більш розбудоване використання того, що ми здебільшого вже бачили.
Коли ми користуємося Facebook, Twitter чи Instagram, ми відвідуємо їхні вебсайти. Ви колись задумувалися, як вони спілкуються один з одним? Наприклад, у Twitter можна увійти за допомогою Google, або, публікуючи допис в Instagram, можна налаштувати автоматичну публікацію у Twitter. Важко уявити, щоб пристрій, з якого ти користуєшся Instagram, заходив замість тебе у Twitter. Повідомлення з одного сервісу іншому надходить за допомогою API.
API (скорочено від Application Programming Interface) — це набір правил, які описують, як комп’ютери або програми взаємодіють одне з одним. У випадку вебсайтів це спілкування найчастіше здійснюється шляхом надсилання один одному повідомлень із певною структурою.
Завдяки простоті створення та поширення пакетів ми можемо легко використовувати різні API. У PyPI є пакети, які дозволяють нам спілкуватися з Twitter, Facebook, Instagram та багатьма іншими платформами. Я навіть знайшов пакет для зв’язку з API, який повертає інформацію про покемонів.
import pokebase as pb charizard = pb.pokemon("charizard") print(charizard.name) # charizard print(charizard.height) # 17 types = [t.type.name for t in charizard.types] print(types) # ['fire', 'flying']
API для завантаження покемонів публічний, що означає, що він не потребує підтвердження нашої особи. Дещо інакше працює API для Twitter, де дуже важливо переконатися, що код має повноваження виконувати певні дії. Адже один допис відомої людини може серйозно нашкодити її іміджу. Тому отримати такі повноваження нелегко. Я пропущу кроки реєстрації та автентифікації особи. З точки зору програмування для відправлення твіту достатньо такого коду:
import tweepy consumer_key = "<Приховано>" consumer_secret = "< Приховано >" access_token = "< Приховано >" access_token_secret = "< Приховано>" auth = tweepy.OAuthHandler( consumer_key, consumer_secret ) auth.set_access_token( access_token, access_token_secret ) api = tweepy.API(auth) status = api.update_status(status="Hello, World!")

Як бачиш, це дуже просто. Аналогічно з багатьма іншими порталами. Це цінують програмісти, які займаються автоматизацією процесів. Наприклад, плануванням та публікацією твітів у маркетингових агентствах.
У цьому розділі ми ознайомилися з різними методами спілкування з вебсайтами, які допомагають збирати дані або автоматизувати процеси. Вони широко використовуються багатьма компаніями. І не лише програмістами, а й, перш за все, тестувальниками, адміністраторами та дослідниками. Також я зустрічав багато технічних менеджерів, які пишуть боти, щоб спростити свою роботу. Наприклад, замість того, щоб кожного дня перевіряти результати продажів, можна написати програму, яка робитиме це сама і додаватиме дані до документа, який створюватиме на їхній основі графік. Тож це дуже універсальні інструменти, про які точно слід знати.
- Для такого використання Python нам знадобиться знання HTML, тобто мови опису вебсторінок. ↩

