

Cześć! To jest fragment książki Python od podstaw, która ma pomóc w nauce programowania od zera. Znajdziesz ją na Allegro, w Empikach i w księgarniach internetowych.
Kolejnym istotnym zastosowaniem programowania jest zbieranie informacji, na przykład z internetu. Tworzy się programy, nazywane botami, które chodzą po różnych witrynach i zbierają dane. Taki bot mógłby się przemieszczać po Allegro i zbierać informacje na temat cen różnych produktów, by później móc je porównać z cenami z innych miejsc, albo by sprawdzić, jak się zmieniają na przestrzeni czasu. Takie boty bardzo często pisze się właśnie w języku Python.
Zobaczmy, jak takie zbieranie danych mogłoby wyglądać. Na celownik weźmiemy zaś nagłówki blogów i portali informacyjnych. Na początek zacznę od popularnego bloga Wait but why.

Tytuły nagłówków moglibyśmy pobrać bezpośrednio ze strony głównej, ale zacznę od nieco łatwiejszej sztuczki. Większość blogów udostępnia stronę zwaną RSS feed, na której w uniwersalny sposób przedstawione są ostatnie artykuły. Wykorzystamy to, po czym przy użyciu pakietu
feedparser odczytamy nagłówki artykułów.import feedparser rss = feedparser.parse("http://waitbutwhy.com/rss") entry = rss.entries[1] titles = [feed.title for feed in rss.entries] for title in titles: print(title) # Mailbag #2 # The Big and the Small # You Won’t Believe My Morning # ...
Analogicznie moglibyśmy także odczytać ich treść czy linki do obrazków promujących te artykuły.
Strony RSS mają najczęściej ograniczenia na liczbę prezentowanych artykułów. Gdybyśmy więc chcieli pobrać większą ich liczbę albo pobierać nagłówki z rankingu najpopularniejszych artykułów, musielibyśmy już operować na stronie. To zaś przedstawię na stronie positive.news, która w kontrze do większości mediów, skupia się na pozytywnych wiadomościach ze świata.
Tutaj wykorzystamy pakiety:
urlopen do pobrania treści strony, oraz BeautifulSoup do odnajdywania konkretnych elementów na danej stronie. Wykorzystałem opcję "Zbadaj" przeglądarki Google Chrome i ustaliłem, że tytuły znajdują się w elementach typu a, z klasą card__title1.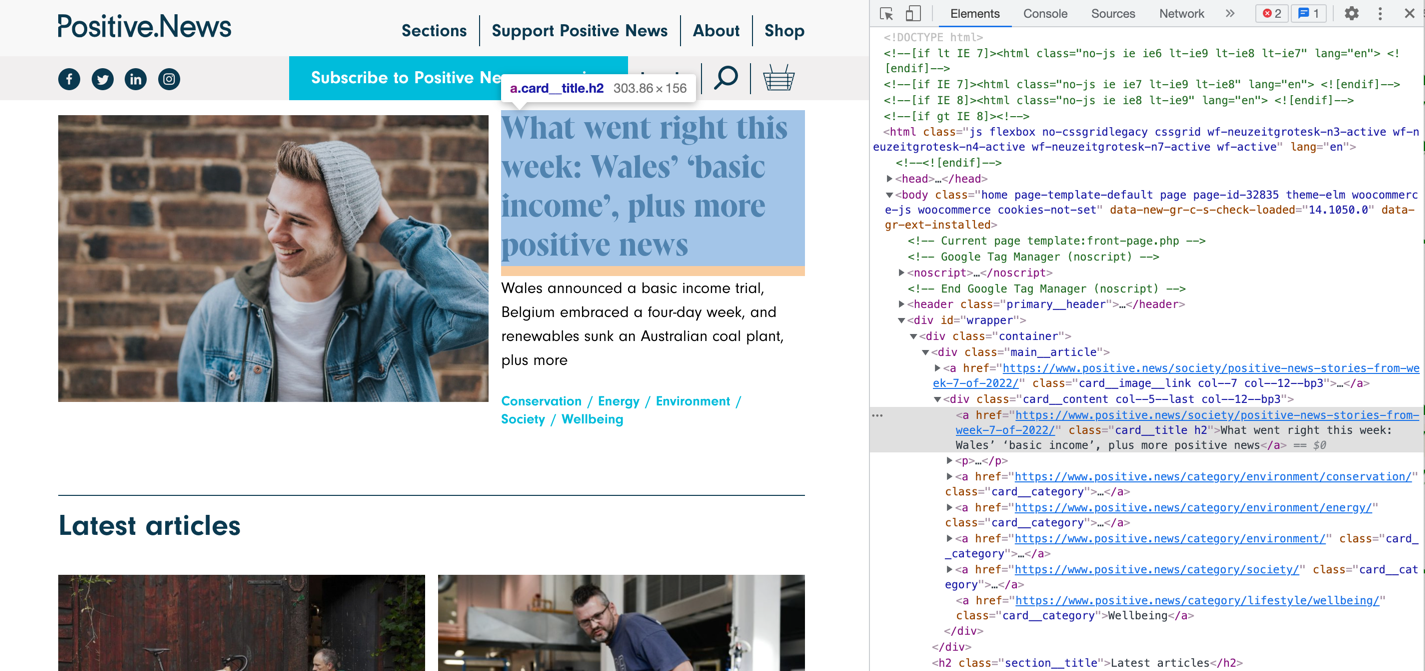
Na tej podstawie łatwo je odnaleźć i wyświetlić.
from bs4 import BeautifulSoup from urllib.request import urlopen html = urlopen("https://www.positive.news/").read() soup = BeautifulSoup(html, "html.parser") titles_elem = soup\ .find_all("a", {"class": "card__title"}) for title in titles_elem: print(title.text) # What went right this week: Wales’ ‘basic income’, ... # The bicycles that grow on trees # The plan to recycle Britain’s waste glass, with a ...
Przy pomocy tych narzędzi moglibyśmy na przykład napisać program, który raz na jakiś czas sprawdzałby, czy nie pojawił się nowy artykuł na interesujących nas portalach.
W praktycznych zastosowaniach programy do zbierania danych są bardziej skomplikowane. Chodzą po kolejnych stronach i poszukują interesujących je informacji. Jest to jednak po prostu bardziej rozbudowane wykorzystanie tego, co już w większości zobaczyliśmy.
Kiedy my korzystamy z portali takich jak Facebook, Twitter czy Instagram, to używamy stron internetowych. Czy zastanawiało Cię jednak, jak one się komunikują między sobą? Na przykład na Twitterze możesz zalogować się przez Google albo gdy publikujesz post na Instagramie, możesz zaznaczyć, by automatycznie był on udostępniany na Twitterze. Ciężko, żeby komputery, na których chodzi Instagram, wchodziły za Ciebie na stronę Twittera. One wysyłają mu wiadomość przez API.
API (skrót od Application Programming Interface) to zbiór reguł opisujący, jak powinny się między sobą komunikować komputery lub programy. W przypadku portali internetowych komunikacja ta najczęściej odbywa się przez wysyłanie sobie wiadomości o konkretnej strukturze.
Dzięki łatwości tworzenia i udostępniania pakietów, w bardzo prosty sposób możemy korzystać z różnych API. Znajdziemy na PyPI pakiety pozwalające nam na łatwą komunikację z Twitterem, Facebookiem, Instagramem i wieloma innymi. Znalazłem nawet pakiet do komunikacji z API zwracającym informacje na temat pokemonów.
import pokebase as pb charizard = pb.pokemon("charizard") print(charizard.name) # charizard print(charizard.height) # 17 types = [t.type.name for t in charizard.types] print(types) # ['fire', 'flying']
API do pobierania pokemonów jest publiczne, czyli nie wymaga od nas żadnych dowodów naszej tożsamości. Zupełnie inaczej jest z takim API Twittera, gdzie bardzo istotne jest upewnienie się, że kod ma uprawnienia do tego, by wykonywać określone akcje. W końcu jeden Tweet znanej osoby może poważnie narazić jej wizerunek na szwank. Dlatego zdobycie takich uprawnień nie jest proste. Pominę kroki rejestrowania aplikacji i uwierzytelniania osoby. Z punktu widzenia programistycznego, do wysłania Tweeta wystarczy następujący kod:
import tweepy consumer_key = "<Ukryte>" consumer_secret = "<Ukryte>" access_token = "<Ukryte>" access_token_secret = "<Ukryte>" auth = tweepy.OAuthHandler( consumer_key, consumer_secret ) auth.set_access_token( access_token, access_token_secret ) api = tweepy.API(auth) status = api.update_status(status="Hello, World!")

Jak widać jest to naprawdę proste. Podobnie z wieloma innymi portalami. Doceniają to programiści automatyzujący procesy. Na przykład właśnie planowanie i wysyłanie Tweetów w agencjach marketingowych.
W tym rozdziale zobaczyliśmy różne techniki komunikacji z serwisami internetowymi, które pomagają w zbieraniu danych czy automatyzacji procesów. Są one powszechnie wykorzystywane przez wiele firm. Przydają się nie tylko programistom, ale przede wszystkim testerom, administratorom oraz badaczom. Spotkałem także wielu managerów technicznych piszących boty, dzięki którym usprawniają swoją pracę. Na przykład, zamiast codziennie sprawdzać wyniki sprzedażowe, możemy napisać program, który zrobi to za nas i doda do dokumentu, w którym tworzony jest na ich podstawie wykres. Są to więc bardzo uniwersalne narzędzia, z których istnienia warto zdawać sobie sprawę.
- Przy tym wykorzystaniu języka Python, nie obejdziemy się bez znajomości HTML, czyli języka opisu stron. ↩
