I often see codebases where everything is defined like a square-hole

- In 1983, an Air Canada plane ran out of fuel due to calculation errors as a result of switching from imperial units to the metric system.
- In 1999, the Mars Climate Orbiter, a $125 million space probe, was lost as a result of NASA and Lockheed Martin using different units for thrust.
- In medical history, you’ll find many cases of people dying as a result of being given the wrong dosages as a result of calculating dosages based on the patient’s weight in kilograms instead of pounds
And these are but a few of many examples … yet, in most code-bases, we still use primitives for everything. We could agree on just using one standard, but how’s that been working out so far … we have four different codes for the same language, country codes can be either two or three characters, and the US won’t switch to the Metric system like the rest of the world and the UK wants to go back to imperial units.

Here’s a simple example of how most of us would have written and used an API for the Mars Climate Orbiter:
fun main() { val mco = MarsClimateOrbiter() // let's apply 120 Newtons of thrust mco.thrust(120) }
The result of this code is:
applying 120 Pound of thrust
Oooof, we would have lost the probe!
If we look at the
MarsClimateObserver class, we’ll see that it actually expects Pound-Force and not Newtons, but unless we looked at the source code, we wouldn’t have known this, and even if we had looked, it might have changed.class MarsClimateOrbiter { fun thrust(thrust: Int) { println("applying $thrust Pound of thrust") } }
Let’s fix this by defining some types first and while we’re at it, let’s define some helper extension variables:
object Types { @JvmInline value class Newton(val value: Int) { companion object { val Int.N: Newton get() = Newton(this) } } @JvmInline value class PoundForce(val value: Int) { companion object { val Int.lbf: PoundForce get() = PoundForce(this) } } }
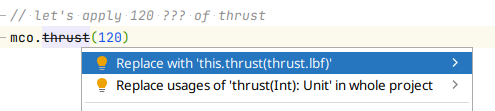
Let’s deprecate the existing thrust method and add two new methods that take values in
PoundForce and Newton:class MarsClimateOrbiter { @Deprecated( message = "this is dangerous, explicitly specify PoundForce or Newton", replaceWith = ReplaceWith( expression = "this.thrust(thrust.lbf)", imports = ["mco.Types.Pounds.Companion.lb"] ) ) fun thrust(thrust: Int) { println("applying $thrust Pound of thrust") } fun thrust(thrust: Types.PoundForce) { println("applying $thrust Pounds of thrust") } fun thrust(thrust: Types.Newton) { println("applying $thrust Newtons of thrust") } }
Going back to our main method, we’ll now have the option to convert this unit-less input to use the expected units
// let's apply 120 Newtons of thrust mco.thrust(120.N) // let's apply 120 Pounds of thrust mco.thrust(120.lbf)
Et voilà, it’s now blatantly obvious which unit a method is expecting and if you pass in the wrong unit, the code simply won’t compile unless you first convert it. Nothing stops you from using regular or data classes, but value classes are compiled out of the way so there’s no runtime overhead.
https://kotlinlang.org/docs/inline-classes.html
https://kotlinlang.org/docs/inline-classes.html
We already learned from our mistake and we’re now diligently using value classes instead of primitive types
fun main() { val mco = MarsClimateOrbiter() while (true) { val elevation: Types.Meter = mco.getElevation() if (elevation < 100.m) { mco.thrust(1.N) } Thread.sleep(100) } }
…but when we test it in simulation, we lose our orbiter again
Exception in thread "main" mco.MarsClimateOrbiter$SensorOfflineException
If only we knew that
getElevation could throw an Exception. Unlike Java which has checked exceptions that force you to handle all exceptions, Kotlin only has unchecked exceptions, and unless we look at the source of getElevation, we wouldn’t have known that getElevation can throw an exception.class SensorOfflineException : Exception() fun getElevation(): Types.Meter = when (Random.nextBoolean()) { true -> this.elevation false -> throw SensorOfflineException() }
Let’s fix this by using the
Result class:class SensorOfflineException : Exception() fun getElevation(): Result<Types.Meter> = when (Random.nextBoolean()) { true -> Result.success(this.elevation) false -> Result.failure(SensorOfflineException()) }
We are now forced to handle errors at the call-site either by using
link to documentation.
onSuccess / onFailure, getOrNull, exceptionOrNull, getOrDefault, getOrElselink to documentation.
fun main() { val mco = MarsClimateOrbiter() while (true) { mco.getElevation().onSuccess { elevation -> if (elevation < 100.m) { mco.thrust(1.N) } }.onFailure { println("something went wrong, let's ignore it") } } // or we can use the getOrNull flavour while (true) { val elevation: Types.Meter? = mco.getElevation().getOrNull() elevation?.let { if (elevation < 100.m) { mco.thrust(1.N) } } Thread.sleep(100) } }
This certainly solves the problem of error handling, but at what cost?
Let’s loop through each of these options a million times so we can get some good average measurements.
const val times = 1_000_000
Option1: return a result class
fun getElevationWithResultClass(input: Int): Result<Types.Meter> { return when (input % 2) { 0 -> Result.success(elevation) else -> Result.failure(SensorOfflineException()) } } fun option1() { val mco = MarsClimateOrbiter() (1..times).forEach { i -> mco.getElevationWithResultClass(i).getOrNull()?.let { if (it < 100.m) { mco.thrust(1.N) } } } }
Option2: throwing an exception
class SensorOfflineException : Exception() fun getElevationWithException(input: Int): Types.Meter { return when (input % 2) { 0 -> elevation else -> throw SensorOfflineException() } } fun option2() { val mco = MarsClimateOrbiter() (1..times).forEach { i -> try { mco.getElevationWithException(i).let { if (it < 100.m) { mco.thrust(1.N) } } } catch (e: MarsClimateOrbiter.SensorOfflineException) { // ignore exception } } }
Option3: using a sealed class to hold the error
sealed interface ElevationResult { data class Success(val value: Types.Meter) : ElevationResult object SensorOffline : ElevationResult } fun getElevationWithError(input: Int): ElevationResult { return when (input % 2) { 0 -> ElevationResult.Success(elevation) else -> ElevationResult.SensorOffline } } fun option3() { val mco = MarsClimateOrbiter() (1..times).forEach { i -> mco.getElevationWithError(i).let { result -> when (result) { is MarsClimateOrbiter.ElevationResult.Success -> { if (result.value < 100.m) { mco.thrust(1.N) } } is MarsClimateOrbiter.ElevationResult.SensorOffline -> { // ignore } } } } }
Option4: the same as the third option, but we change the object to a data class in the sealed interface
sealed interface ElevationResult { data class Success(val value: Types.Meter) : ElevationResult data class SensorOffline(val message: String) : ElevationResult }
Let’s create a mini benchmark that first warms up the JVM and then a bunch of runs to get the average time taken (I’m too lazy to set up JMH, share your results if you’ve tested it with JMH)
fun benchmark(option: () -> Unit) { // warmup repeat(25) { option() } // benchmark val results = mutableListOf<Long>() repeat(25) { measureTimeMillis { option() }.let { results.add(it) } } println("average=${results.average()}ms") } fun main() { // benchmark(::option1) // benchmark(::option2) benchmark(::option3) }
Results:
- Option1 — Result Class: ~376ms
- Option2 — Throwing an Exception: ~376ms
- Option3 — Sealed Interface (error object): ~3.84ms
- Option4 — Sealed Interface (error data class): ~2.15ms
Woah, using the Sealed Interface is ~100x faster, but this may be an exaggerated example since every second call is an error. That being said, if an error is part of your expected flow (validation error, no result found, etc), don’t use an exception for it, you’re taking a huge performance penalty when doing so.
The Mars Climate Orbiter is sending back some raw data to earth in bytes that need to be queried in mcoql (Mars Climate Orbiter Query Language, a made-up language for the purpose of this article). One team specializes in writing queries for this data, and another team works with the repository created by the low-level team.
The team that processes the data often needs to look at functions like this to figure out what data they need to send and what data to expect back.
fun queryThrusterLog(timestamp: TimeStamp): Array<Array<ByteArray>> { return mco { query( // language=mcoql """ SEL 63 6f 6c 31 63 6f 6c FROM mcodata WHERE time > $1 """, timestamp ) } }
For someone new on the project who’ve never used mcoql, it’s not obvious what format the data needs to be in and what format the result is returned. We can see that it’s returning
Array<Array<ByteArray>>, which is a grid, but we can’t see the number of columns being returned just by looking at the method signature.Adding some helper functions to TimeStamp allows the user to convert from their preferred date-time format to whatever date-time format is required to run the query,
TimeStamp.of(java.util.Date), TimeStamp.of(java.util.Calendar) or TimeStamp.of(java.time.LocalDateTime).The // language=mcoql is an intellij feature that allows you to apply syntax highlighting on any String by simply adding a comment above the String saying what language the String is. Try it with any supported IntelliJ languages like HTML, SQL, XML, JSON, JavaScript, etc.
Wouldn’t it be great if we could write
query<INT4, …, INT8> and depending on the number of generics we provide, that’s the number of results we can destructure to?// col1 is of type INT4 val (col1) = query<INT4>("...", date) // col1: INT4, col2: INT8 val (col1, col2) = query<INT4, INT8>("...", date) // col1: VARCHAR, col2: INT4, col3: INT8 val (col1, ..., colN) = query<INT4, ..., INT4>("...", date)
Ultimately we want to return a data class and make sense of these values, but at the low level, we want to be as close as possible to what the documentation says, if the documentation says running this query returns an INT4 and an INT8, the above format will make it very easy to see the intent whereas converting directly to a data class obfuscates the low-level intent. The same applies when writing database drivers, for example, see the PostgreSQL protocol message format documentation:
https://www.postgresql.org/docs/14/protocol-message-formats.html
or working with ISO bank integrations, or writing code that interacts with ATMs, planes, or just about anything that goes over the network in binary format.
https://www.postgresql.org/docs/14/protocol-message-formats.html
or working with ISO bank integrations, or writing code that interacts with ATMs, planes, or just about anything that goes over the network in binary format.
Eventually, we want to end up with something like this:
data class QueryThrusterLog( val thrustX: Types.Newton, val thrustY: Types.Newton, val time: Types.TimeStamp ) sealed interface QueryThrusterLogResults { data class Success(val results: List<QueryThrusterLog>) : QueryThrusterLogResults data class Failure(val error: Types.Message) : QueryThrusterLogResults } fun queryThrusterLog(timestamp: Types.TimeStamp): QueryThrusterLogResults { return mco { query<INT4, INT8, INT4, INT8, TIMESTAMP>( // language=mcoql """ SEL 63 6f 6c 31 63 6f 6c FROM mcodata WHERE created > $1 """, timestamp ).onSuccess { rows -> // rows: QueryResults5<INT4, INT8, INT4, INT8, TIMESTAMP> // row: QueryResult5<INT4, INT8, INT4, INT8, TIMESTAMP> QueryThrusterLogResults.Success( rows.map { row -> val (x, xUnit, y, yUnit, time) = it // we assume we’re getting Newtons back check(xUnit.isNewtons()) check(yUnit.isNewtons()) QueryThrusterLog(x = x.toNewton(), y = y.toNewton(), timestamp = time) } ) }.onFailure(::QueryThrusterLogResults.Failure) } }
Getting this exact structure is left as an exercise to the reader, in this article, we’ll only explore getting
List<Result4<A,B,C,D>> from query<A,B,C,D>` instead of a List<List<ByteArray>Let’s start with the
TypeMarker class that will allow us up to 5 columns (you can increase this to however many you want, but to keep things short, we’re only going up to 5 here).sealed class TypeMarker5<out T1, out T2, out T3, out T4, out T5> { @PublishedApi internal object IMPL : TypeMarker5<Nothing, Nothing, Nothing, Nothing, Nothing>() } typealias TypeMarker4<T1, T2, T3, T4> = TypeMarker5<T1, T2, T3, T4, Nothing> typealias TypeMarker3<T1, T2, T3> = TypeMarker4<T1, T2, T3, Nothing> typealias TypeMarker2<T1, T2> = TypeMarker3<T1, T2, Nothing> typealias TypeMarker1<T1> = TypeMarker2<T1, Nothing>
Now for the upgraded query functions:
fun <T1> query( vararg args: Any, typeMarker: TypeMarker1<T1> = TypeMarker5.IMPL, ): Array<T1> { TODO() } fun <T1, T2> query( vararg args: Any, typeMarker: TypeMarker2<T1, T2> = TypeMarker5.IMPL, ): Array<Pair<T1, T2>> { TODO() } fun <T1, T2, T3> query( vararg args: Any, typeMarker: TypeMarker3<T1, T2, T3> = TypeMarker5.IMPL, ): Array<Triple<T1, T2, T3>> { TODO() }
This now allows us to extract the values with correct types using destructuring:
query<INT4>().forEach { (a) -> // a: INT4 // ... } query<INT4, INT8>().forEach { (b, c) -> // b: INT4, c: INT8 // ... } query<INT4, INT8, BOOL>().forEach { (d, e, f) -> // d: INT4, e: INT8, f: BOOL // ... }
The following snippet will still compile, but we’re throwing away the second value:
query<INT4, BOOL>().forEach { (b) -> // b: INT4 // ... }
The following one, however, will not compile since we’re expecting 3 values, but only 2 are returned, we’re requesting more data than what is returned.
query<INT4, INT8>().forEach { (b, c, d) -> // b: INT4, c: INT8, d: ??? -> compiler error // ... }
What about handling 4, 5, …, 100+ values? Kotlin only has
Pair and Triple.We’ll need a
Tuple, I’m only writing a Tuple4 here, but you’ll need one of these for each number of columns you want to support.data class Tuple4<out T1, out T2, out T3, out T4>( val value1: T1, val value2: T2, val value3: T3, val value4: T4, )
Ultimately, you will write some simple code that generates this as text output using a simple for loop and some
printlns for Tuple1 to 100 and copy-paste it into your source file. I don’t recommend writing it by hand unless you’re looking for an excuse to practice your DVORAK or something.fun <T1, T2, T3, T4> query( vararg args: Any, typeMarker: TypeMarker4<T1, T2, T3, T4> = TypeMarker5.IMPL, ): Array<Tuple4<T1, T2, T3, T4>> { ... }
allowing us to do
query<INT4, INT8, BOOL, CHAR>().forEach { // g: INT4, h: INT8, i: BOOL, j: CHAR val (g, h, i, j) = it }
Now the engineers working at the byte-level can at least encapsulate their queries giving the untyped data some form of bounded context keeping the code in such a way that the code matches the documentation terminology 1:1 and then one layer further up, you can convert to something that’s closer to the user-space
val result: Array<Thrust> = query<INT4, INT8, INT4, INT8>().map { // x: INT4, xunit: INT8, y: INT4, yunit: INT8 val (x, xunit, y, yunit) = it Thrust( x = x.toNewton(), xUnit = xunit.toUnit(), y = y.toNewton(), yUnit = yunit.toUnit(), ) }
Using some of these ideas, you’ll end up improving your APIs so that not everything goes into the square hole.
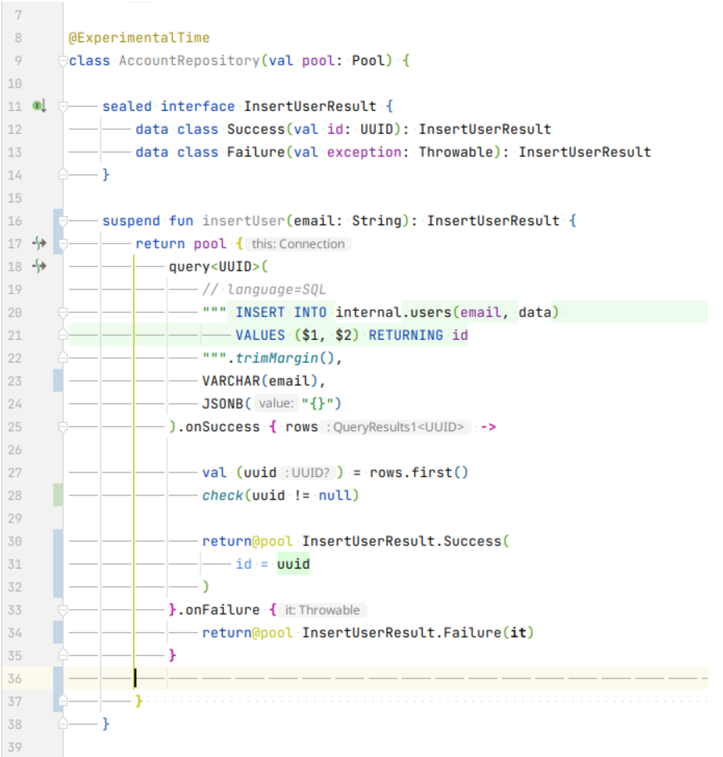
Addendum, here’s an example of this syntax in the wild (this is from the Coroutines PostgreSQL driver in the Alumonium library). Since we have
query<UUID>, we’re expecting QueryResults1<UUID> and if we had query<UUID, INT4>, we’re expecting QueryResults2<UUID, INT4>, etc.