

- Why do we need yet another article on Structured Concurrency?
- What is Structured Concurrency?
- What is a hierarchy of coroutines?
- Why is Structured Concurrency important?
- 💯 Completion
- 🙅 Cancellation
- 💥 Exceptions
- 👨👩👧👦 Context inheritance
- 🧠 Conceptual understanding
- How to use Structured Concurrency?
- When not to use Structured Concurrency?
- How to bypass certain elements of Structured Concurrency
- Bypass automatic cancellation on failure
- Non-cancellable context
- Jobs and Structured Concurrency
- 🧙♂️ Coroutines mastery course
- 🏛️ Motivation for Structured Concurrency
- 🚀 What's next for Structured Concurrency?
- 🤖 IntelliJ IDEA / Android Studio plugin
- ☕️ Structured concurrency compared to Java and other programming languages
- 📚 Resources
- Who am I?
Don't we have enough articles on Structured Concurrency already? 🤔🤣
I have an ambitious goal for my article to become the definitive guide on Structured Concurrency! 💪
My plan is to explain the concepts clearly and concisely (Kotlin-style). Sample code snippets will illustrate the concepts.
Additional material and resources are optional but can be used to gain a deeper understanding of its motivation, potential upcoming changes, and more.
If you have any questions or have suggestions to improve the content, please let me know via a comment.
I have an ambitious goal for my article to become the definitive guide on Structured Concurrency! 💪
My plan is to explain the concepts clearly and concisely (Kotlin-style). Sample code snippets will illustrate the concepts.
Additional material and resources are optional but can be used to gain a deeper understanding of its motivation, potential upcoming changes, and more.
If you have any questions or have suggestions to improve the content, please let me know via a comment.
Structured concurrency is the Kotlin coroutines' mechanism that keeps track of a hierarchy of coroutines which works as a unit (I mean: it works as an entity, please don't confuse it with the
Unit keyword) and is used to avoid resource leaks, avoid running unnecessary processes, properly await completion, and proper error handling.A hierarchy of coroutines consists of the original coroutine (launched in a given scope), its children, their children, etc.
For example:
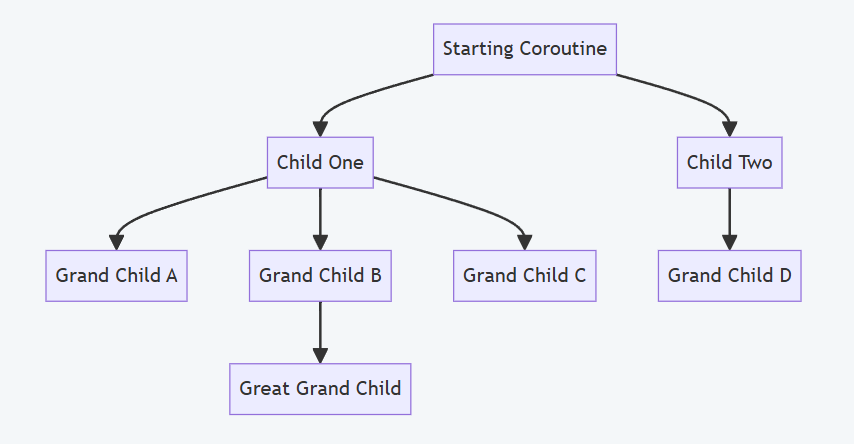
A hierarchy of coroutines
A hierarchy of coroutines
A parent cannot complete until all its children have completed. The completion guarantee is what makes Structured Concurrency structured. It transforms what might be a messy graph of concurrent tasks into a well-defined tree with a clear root, clear ownership, and a clear end. And that makes the code much easier to understand and reason.
❌ Without Structured Concurrency
import kotlinx.coroutines.* import kotlin.time.Duration.Companion.seconds private suspend fun main() { val scope = CoroutineScope(Dispatchers.Default) val job1 = scope.launch { println("Child 1: Starting heavier work...") delay(2.seconds) println("Child 1: Heavier work completed.") } val job2 = scope.launch { println("Child 2: Starting lighter work...") delay(1.seconds) println("Child 2: Lighter work completed.") } // Since we are breaking Structured Concurrency by launching the jobs in a different coroutine, // we need to wait for both children to complete, otherwise `main` finishes before the jobs finish // Comment-out `joinAll` to see that joinAll(job1, job2) } // Child 2: Starting lighter work... // Child 1: Starting heavier work... // (1 sec) // Child 2: Lighter work completed. // (1 sec) // Child 1: Heavier work completed.
✅ With Structured Concurrency
import kotlinx.coroutines.* import kotlin.time.Duration.Companion.seconds private suspend fun main(): Unit = coroutineScope { launch { println("Child 1: Starting heavier work...") delay(2.seconds) println("Child 1: Heavier work completed.") } launch { println("Child 2: Starting lighter work...") delay(1.seconds) println("Child 2: Lighter work completed.") } // Since we are relying on Structured Concurrency, there is no need to wait for both children to complete // That happens automagically // And there is no need to keep track of `job1` and `job2` } // Child 2: Starting lighter work... // Child 1: Starting heavier work... // (1 sec) // Child 2: Lighter work completed. // (1 sec) // Child 1: Heavier work completed.
Structured Concurrency ensures that when a scope is canceled, all of its child coroutines are automatically canceled (NOTE: sibling coroutines are not canceled). This prevents orphan coroutines from running, consuming resources, and potentially causing memory leaks. If we were running on a cell phone, we would be conserving precious battery life.
Why bother running unnecessary processes if their result would have been consumed by a coroutine that has been canceled?
Why bother running unnecessary processes if their result would have been consumed by a coroutine that has been canceled?
❌ Without Structured Concurrency
import kotlinx.coroutines.* import kotlin.time.Duration.Companion.seconds suspend fun main() { val scope1 = CoroutineScope(Dispatchers.Default) val scope2 = CoroutineScope(Dispatchers.Default) val job1 = scope1.launch { try { println("Child 1: Starting heavier work...") delay(4.seconds) println("Child 1: Heavier work completed.") // NOTE: Child 1 continues running, but why!? We should not continue processing Child 1, because scope2 was canceled we would expect all coroutines to be canceled } catch (e: CancellationException) { // We won't catch any cancellations because we are breaking Structured Concurrency println("Child 1: Was canceled during delay.") throw e // You should always rethrow CancellationException if caught, to propagate the cancellation } finally { // Cleanup logic runs even if canceled println("Child 1: Performing cleanup.") } } val job2 = scope2.launch { try { println("Child 2: Starting lighter work...") delay(2.seconds) println("Child 2: Lighter work completed.") } finally { println("Child 2: Performing cleanup.") } } delay(1.seconds) scope2.cancel("Just to demonstrate what happens when a scope is canceled") // Since we are breaking Structured Concurrency by launching the jobs in different scopes, // we need to wait for both children to complete, otherwise main finishes before the jobs finish joinAll(job1, job2) } // Child 2: Starting lighter work... // Child 1: Starting heavier work... // (1 sec) // Child 2: Performing cleanup. // (3 sec) // Child 1: Heavier work completed. // Child 1: Performing cleanup.
✅ With Structured Concurrency
import kotlinx.coroutines.* import kotlin.time.Duration.Companion.seconds private suspend fun performCancellableWork() { val scope = CoroutineScope(Dispatchers.Default) scope.launch { try { println("Child 1: Starting heavier work...") delay(4.seconds) // This is a suspension point and cooperative to cancellation println("Child 1: Heavier work completed.") // This will never print because all child coroutines in the scope are canceled thanks to Structured Concurrency } catch (e: CancellationException) { println("Child 1: Was canceled during delay.") throw e // You should always rethrow CancellationException if caught, to propagate the cancellation } finally { // We need the `NonCancellable` context if the cleanup requires invoking any suspending functions withContext(NonCancellable) { delay(1.seconds) println("Child 1: Performing cleanup with NonCancellable context.") } } } scope.launch { try { println("Child 2: Starting lighter work...") delay(2.seconds) // This is a suspension point and cooperative to cancellation // This message won't be printed because the coroutine will be canceled println("Child 2: Lighter work completed.") // This will never print because all child coroutines in the scope are canceled thanks to Structured Concurrency } catch (e: CancellationException) { println("Child 2: Was canceled during delay.") throw e // You should always rethrow CancellationException if caught, to propagate the cancellation } finally { println("Child 2: Performing cleanup without calling suspending functions, no need for NonCancellable context.") } } delay(1.seconds) scope.cancel("Just to demonstrate what happens when a scope is canceled") // Wait for all child coroutines to complete cleaning up scope.coroutineContext.job.join() } fun main(): Unit = runBlocking { performCancellableWork() println("Main scope: All work finished.") } // Child 1: Starting heavier work... // Child 2: Starting lighter work... // (1 sec) // Child 1: Was canceled during delay. // Child 2: Was canceled during delay. // Child 2: Performing cleanup without calling suspending functions, no need for NonCancellable context. // (1 sec) // Child 1: Performing cleanup with NonCancellable context. // Main scope: All work finished.
ℹ️ NOTE: Structured Concurrency relies on code being Cooperative to Cancellation to enforce the Cancellation guarantee. Suspend functions fromkotlinx.coroutinesare cancellable.
The code you write should also be cancellable. This can be done by either checkingjob.isActiveorensureActive()or by allowing other work to happen by callingyield().
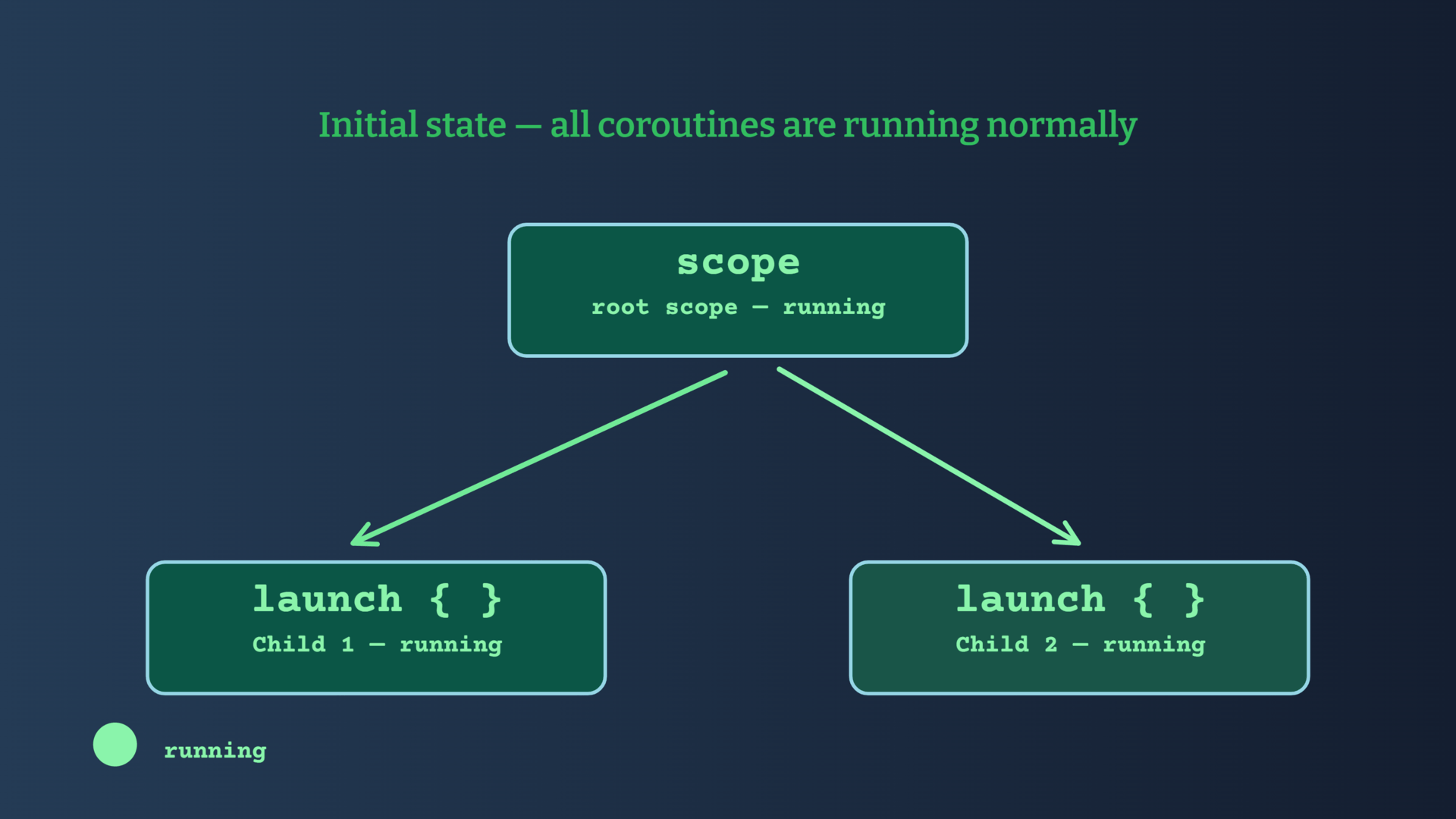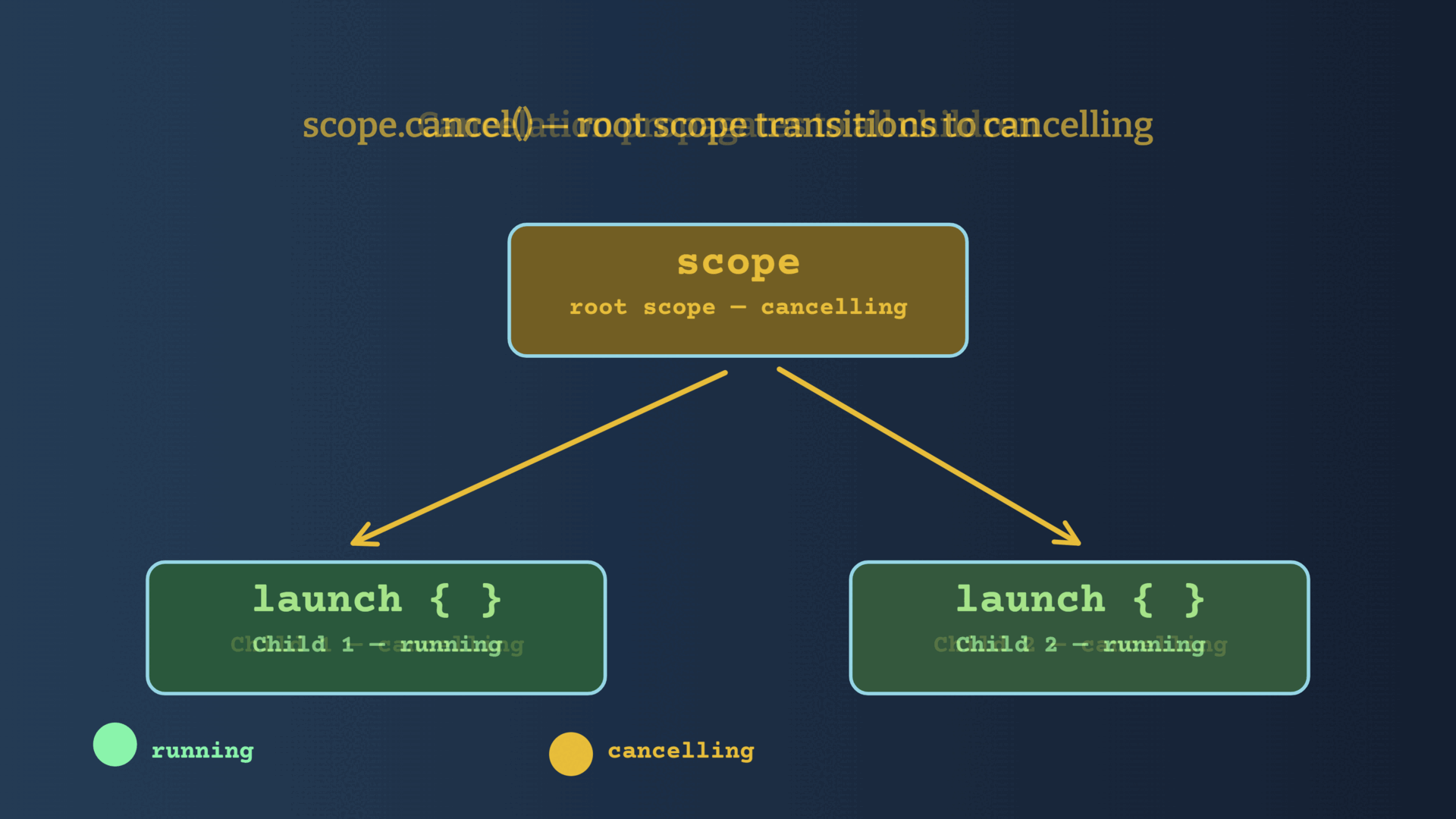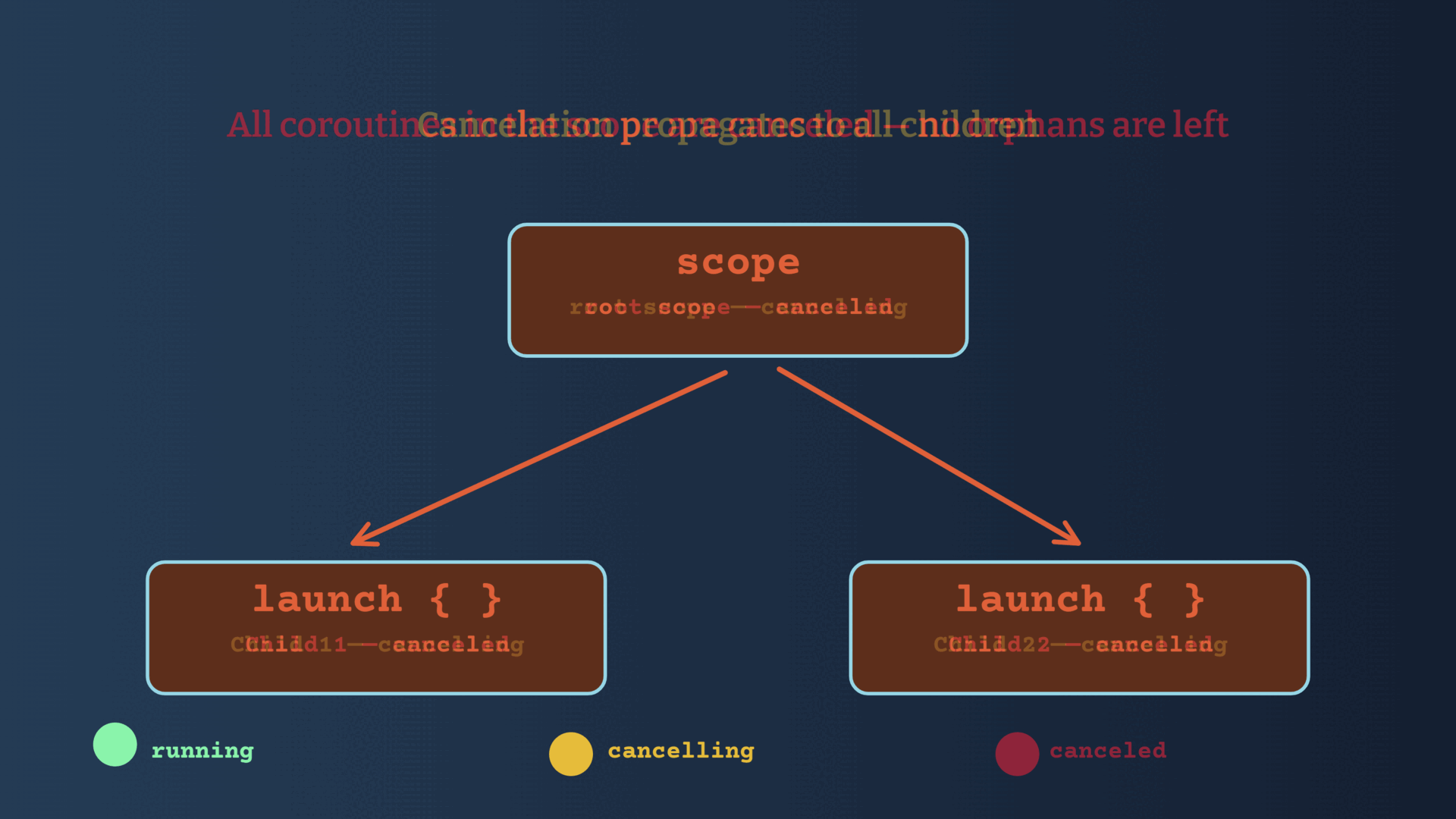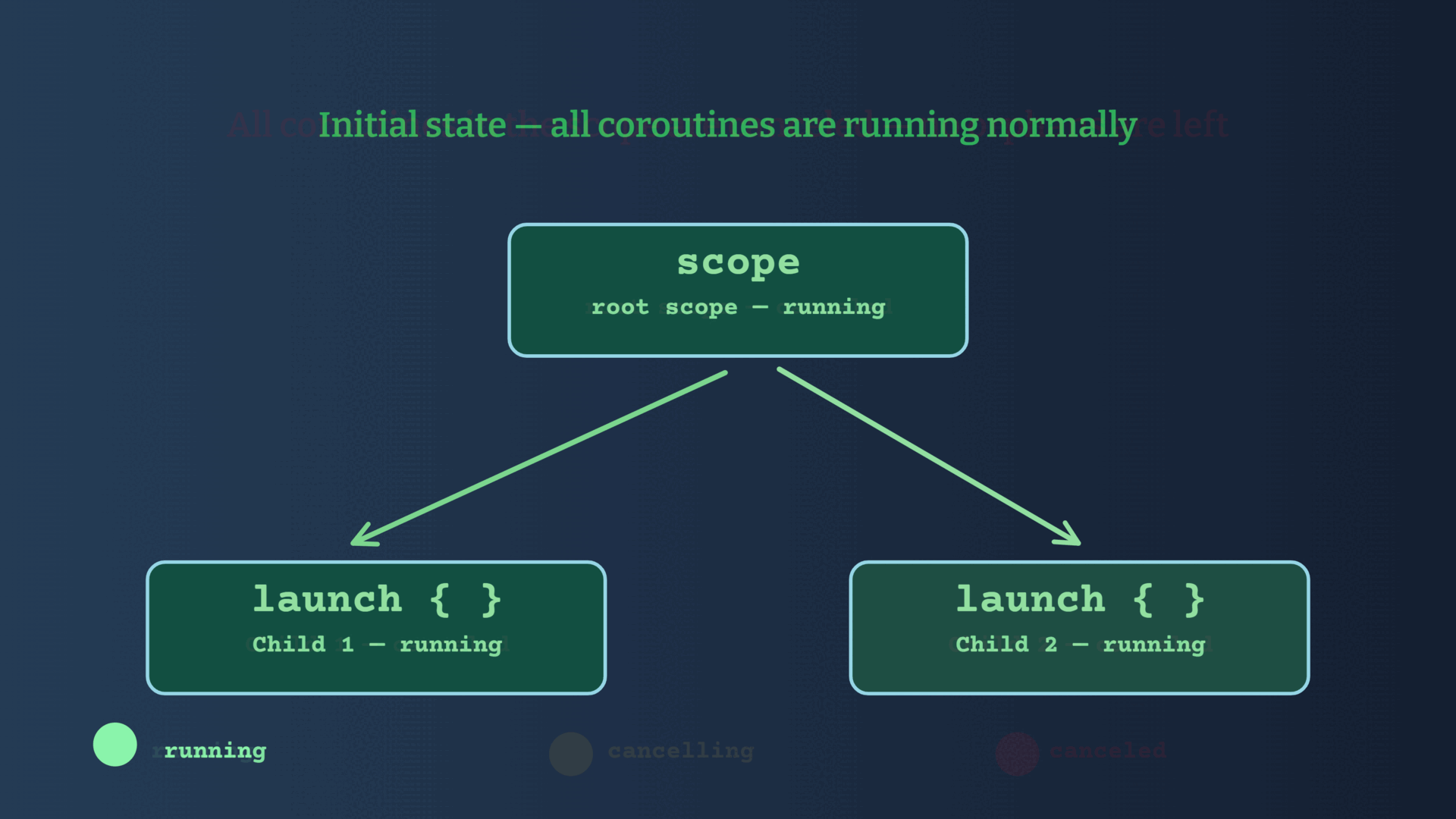
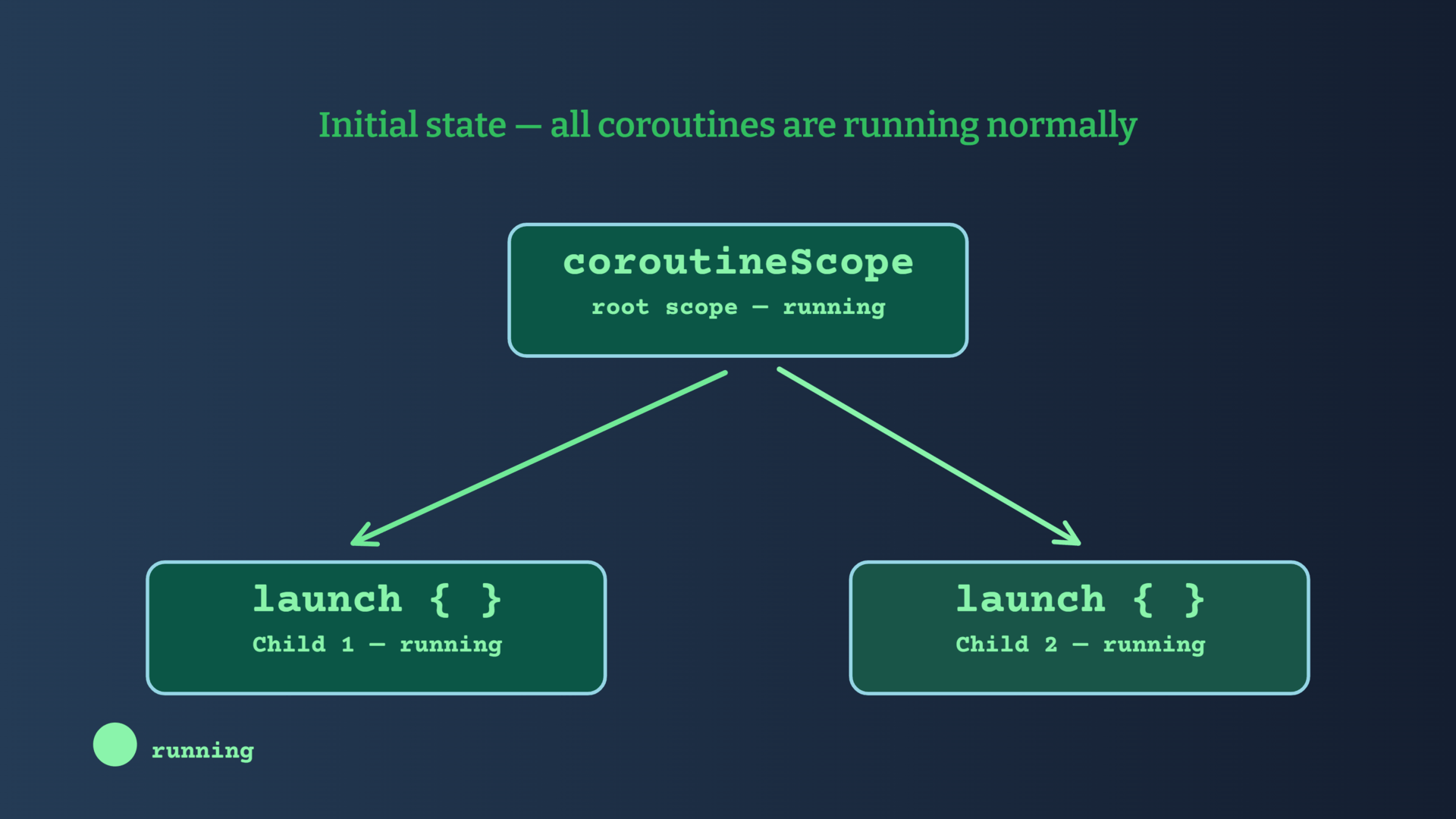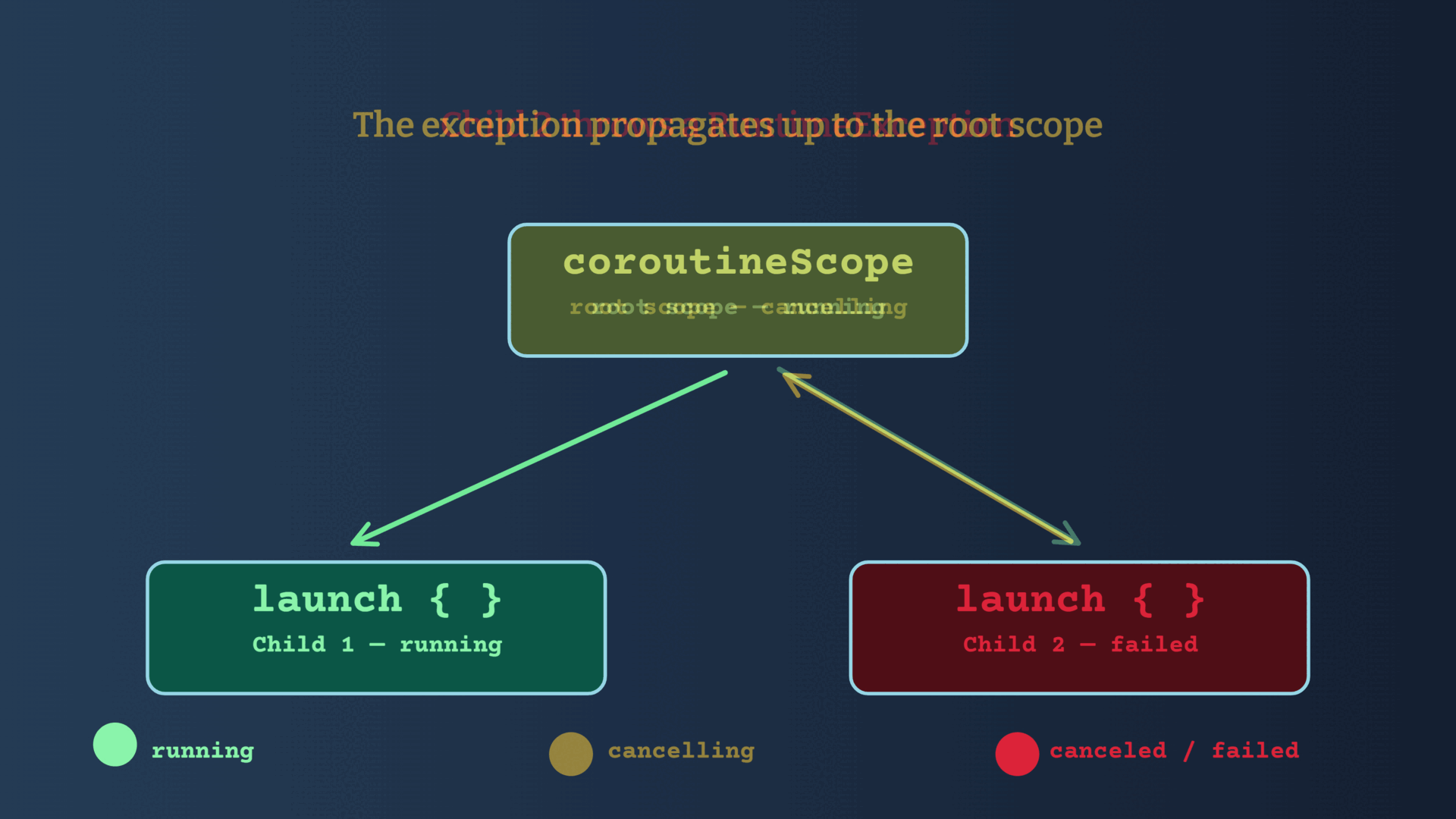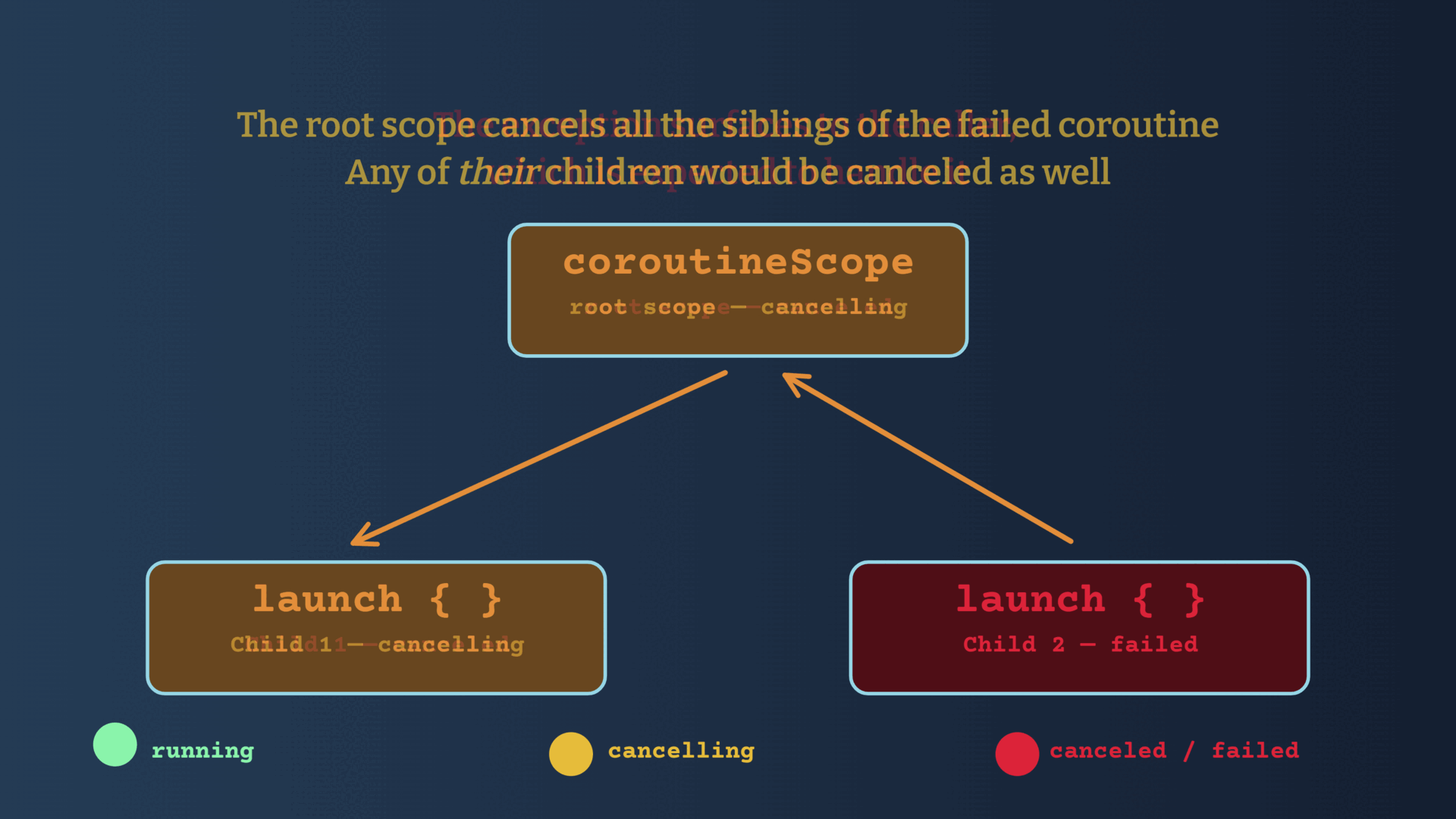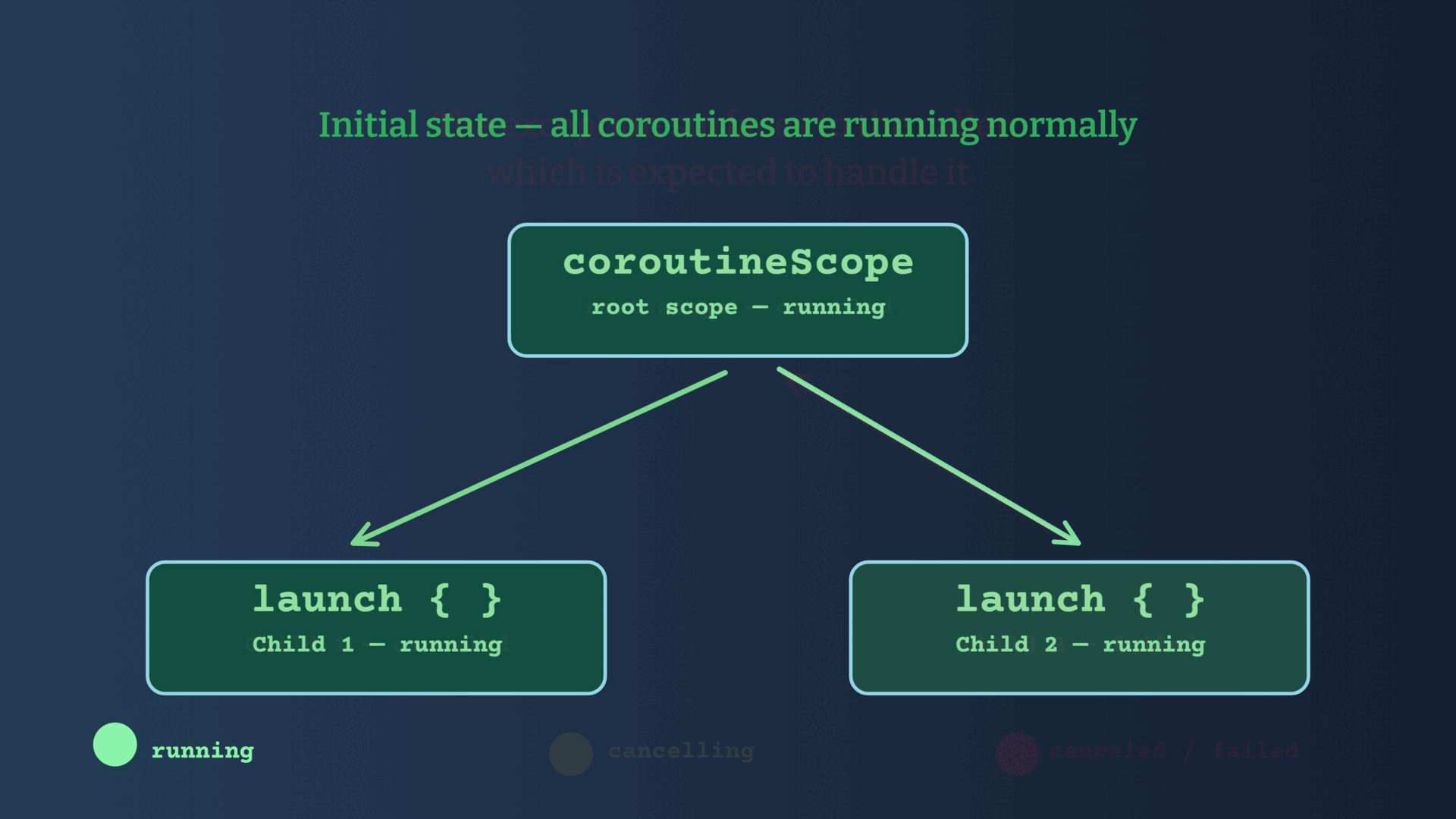
If a child coroutine completes with an exception, Structured Concurrency ensures that the exception is propagated to the parent which will then cancel all sibling coroutines, and it will then re-throw the exception to its caller.
Let's say that your process starts many coroutines, and one of them throws an exception -> all the other coroutines will be canceled automatically.
Let's say that your process starts many coroutines, and one of them throws an exception -> all the other coroutines will be canceled automatically.
This is important because:
- It ensures that exceptions are not silently ignored
- Other coroutines in the tree are canceled, so no resources are wasted
- Everything succeeds or nothing succeeds. Similar to a transaction in a database.
❌ Without Structured Concurrency
import kotlinx.coroutines.* import kotlin.time.Duration.Companion.seconds suspend fun performWorkThatCanThrow(): Unit = coroutineScope { val scope1 = CoroutineScope(Dispatchers.Default) val scope2 = CoroutineScope(Dispatchers.Default) val job1 = scope1.launch { println("Child 1: Starting heavier work...") delay(2.seconds) // If we had Structure Concurrency, we would not see this message because this coroutine would have been canceled println("Child 1: Heavier work completed.") } val job2 = scope2.launch { println("Child 2: Starting lighter work...") delay(1.seconds) println("Child 2: Lighter work completed.") throw RuntimeException("Something went wrong in Child 2") // An exception here should cancel the parent scope and all children } // Since we are breaking Structured Concurrency by launching the jobs in different scopes, // we need to wait for both children to complete, otherwise main finishes before the jobs finish joinAll(job1, job2) } fun main(): Unit = runBlocking { try { performWorkThatCanThrow() } catch (e: RuntimeException) { // The exception from Child 2 should propagate here, but doesn't because we broke Structured Concurrency println("Main scope: Caught exception: ${e.message}") } println("Main scope: All work finished.") } // Child 1: Starting heavier work... // Child 2: Starting lighter work... // (1 sec) // Child 2: Lighter work completed. // Exception in thread "DefaultDispatcher-worker-1 @coroutine#3" java.lang.RuntimeException: Something went wrong in Child 2 // at FileKt$performWorkThatCanThrow$2$job2$1.invokeSuspend(File.kt:19) // ... // Suppressed: kotlinx.coroutines.internal.DiagnosticCoroutineContextException: [CoroutineId(3), "coroutine#3":StandaloneCoroutine{Cancelling}@3c243ebc, Dispatchers.Default] // (1 sec) // Child 1: Heavier work completed. // Main scope: All work finished.
The exception is not propagated to the caller. It either crashes silently or requires a separate
CoroutineExceptionHandler to be caught. Also, other coroutines keep running. With Structured Concurrency, they would have been canceled.✅ With Structured Concurrency
import kotlinx.coroutines.* import kotlin.time.Duration.Companion.seconds suspend fun betterPerformWorkThatCanThrow(): Unit = coroutineScope { launch { println("Child 1: Starting heavier work...") delay(2.seconds) // Thanks to Structured Concurrency, we won't see this message because this coroutine is canceled once its sibling coroutine throws an exception println("Child 1: Heavier work completed.") } launch { println("Child 2: Starting lighter work...") delay(1.seconds) println("Child 2: Lighter work completed.") throw RuntimeException("Something went wrong in Child 2") } } fun main(): Unit = runBlocking { try { betterPerformWorkThatCanThrow() } catch (e: RuntimeException) { // The exception from Child 2 propagates here, thanks to Structured Concurrency println("Main scope: Caught exception: ${e.message}") } println("Main scope: All work finished.") } // Child 1: Starting heavier work... // Child 2: Starting lighter work... // (1 sec) // Child 2: Lighter work completed. // Main scope: Caught exception: Something went wrong in Child 2 // Main scope: All work finished.
Children inherit their parents' context.
❌ Without Structured Concurrency
import kotlinx.coroutines.* import kotlin.time.Duration.Companion.seconds suspend fun main(): Unit = withContext(Dispatchers.IO + CoroutineName("Parent")) { // Child launched in a completely separate, manually defined scope val childScope = CoroutineScope(Dispatchers.Default) childScope.launch { println("Running in dispatcher=${coroutineContext[ContinuationInterceptor] as CoroutineDispatcher}, name=${coroutineContext[CoroutineName]}") }.join() } // Running in dispatcher=Dispatchers.Default, name=null // NOTE: The coroutine did not inherit the parent's context (i.e.: Dispatcher and Name) because it was launched in a different scope, breaking Structured Concurrency
The child uses its own hardcoded scope, so the parent's
Dispatcher and CoroutineName (and any other context elements like MDCContext for logging) are silently lost.✅ With Structured Concurrency
import kotlinx.coroutines.* suspend fun main(): Unit = withContext(Dispatchers.IO + CoroutineName("Parent")) { launch { // Inherits Dispatchers.IO and CoroutineName from its parent, automatically thanks to Structured Concurrency println("Running in dispatcher=${coroutineContext[ContinuationInterceptor] as CoroutineDispatcher}, name=${coroutineContext[CoroutineName]}") } } // Running in dispatcher=Dispatchers.IO, name=CoroutineName(Parent)
Children automatically inherit their parents' context. Dispatcher, name, and any custom context elements, such as tracing or logging MDC, are carried through without any extra wiring.
Last but not least: Structured Concurrency makes it easy to reason about a hierarchy where the lifetime of a concurrent operation is limited by the scope in which it is launched.
The nice thing about using Structured Concurrency in Kotlin is that we don't need to do anything special. It is the standard behavior now. Originally, this was not the case. Scary times 👻. Read more about this later.
ℹ️ NOTE: Structured Concurrency creates a hierarchy that represents the parent-child relationships established when launching the coroutines within a scope.
Most of the time, you should rely on Structured Concurrency.
An exception to this rule is when you either don't want to (and hopefully there is a good reason for it):
- await the completion of all coroutines in a hierarchy and/or
- cancel all coroutines in the hierarchy when one is canceled and/or
- inherit the
contextfrom the parent coroutine
supervisorScope is very similar to coroutineScope, but a failure in one child doesn't automatically cancel the others.This way, exceptions from its children are ignored (they only call the coroutine exception handler, so by default, that is print stacktrace).
Beware that
If an exception occurs in a child of a child, it propagates to the parent of this child, destroys it, and only then gets ignored.
Beware that
supervisorScope only ignores exceptions from its children. If an exception occurs within supervisorScope itself, it breaks this coroutine builder and the exception propagates to its parent.If an exception occurs in a child of a child, it propagates to the parent of this child, destroys it, and only then gets ignored.
supervisorScope is often used when we need to start multiple independent processes, and we don't want an exception in one of them to cancel the others.Non-cancellable context
When a coroutine is canceled, we know that, thanks to Structured Concurrency, all the coroutines in its hierarchy are also canceled.
Imagine having a coroutine in this hierarchy that is used for doing some cleanup. But if the cleanup requires launching other coroutines, that wouldn't normally work, because the coroutine is in
Imagine having a coroutine in this hierarchy that is used for doing some cleanup. But if the cleanup requires launching other coroutines, that wouldn't normally work, because the coroutine is in
state=Cancelling. To bypass that, and as a workaround, we need to launch that clean up coroutine withContext(NonCancellable).🚩 BEWARE: When youlauncha coroutine, you can optionally pass a context (among other things). If that context includes a Job, that will break Structured Concurrency, and it's very likely not what you were trying to do.
The same thing applies to launching a coroutine withasyncorwithContext.
Similarly, we are not supposed to override the
Job in a coroutine starter (launch, async, withContext) context:suspend fun main(): Unit = coroutineScope { // ❌ Not a good idea launch(context = Job()) { delay(1.seconds) } }
To make things more confusing,
Job is the only coroutine context that is not inherited by a coroutine from another coroutine. 🤦♂️coroutineScope { launch { // ✅ NOTE: We don't provide a Job in the context when invoking *launch*. This keeps Structured Concurrency. Nice! val childJob = coroutineContext[Job] println(childJob == someJob) // false, so Job is not inherited println(childJob == someJob.children.first()) // true, so it is a child of the job from the parent } val someJob = Job() launch(context = someJob) { // ❌ NOTE: We do provide a Job in the context when invoking *launch*. This *breaks* Structured Concurrency and should normally be avoided. Not good. val childJob = coroutineContext[Job] println(childJob == someJob) // false, so Job is not inherited println(childJob == someJob.children.first()) // true, so it is a child of the job from the parent } }
As part of the amazing Coroutines Mastery class taught by Marcin Moskała, we got exclusive access to Q&A with Roman Elizarov, the original creator of Kotlin Coroutines, former Kotlin Team Lead at JetBrains and also with Vsevolod Tolstopyatov, Kotlin Team Lead at JetBrains, responsible for the roadmap and future of coroutines.
Please consider joining the next edition of Coroutines Mastery, starting in November 2026.
Please consider joining the next edition of Coroutines Mastery, starting in November 2026.
Roman gave us background on the motivation for Structured Concurrency and some of its history.
There seems to be a myth that says that Roman was inspired by this article to come up with Structured Concurrency. He dispelled that rumor by saying that the article only helped him to come up with the term "Structured Concurrency" 🤣. In the article I listed under [Resources], he recommends reading it, so it may have inspired him beyond just the term.
He also told us C# and Go were great inspirations, but they lacked a mechanism like Structured Concurrency.
In very early workshops, developers were shown the proper way to create coroutines, and it was noticed that even though the developers were instructed to pass the parent's
Instead of asking developers to code for the default (and desired) behavior, we now only need to write special code for edge cases. That is likely to change. See the next section 😜
There seems to be a myth that says that Roman was inspired by this article to come up with Structured Concurrency. He dispelled that rumor by saying that the article only helped him to come up with the term "Structured Concurrency" 🤣. In the article I listed under [Resources], he recommends reading it, so it may have inspired him beyond just the term.
He also told us C# and Go were great inspirations, but they lacked a mechanism like Structured Concurrency.
In very early workshops, developers were shown the proper way to create coroutines, and it was noticed that even though the developers were instructed to pass the parent's
Job when launching a coroutine, many times the developers forgot. This caused problems with cancellations and with exceptions. That's when the team decided to enforce Structured Concurrency by automatically building the hierarchy, since that is what we want 99% of the time.Instead of asking developers to code for the default (and desired) behavior, we now only need to write special code for edge cases. That is likely to change. See the next section 😜
Vsevolod talked about the future of coroutines and hinted at future improvements to Structured Concurrency:
- Instead of simply keeping track of the hierarchy as in the parent-child relationship of coroutines, there are plans to additionally keep track of what that relationship means. This can include whether the child wants to be canceled if the parent is canceled, or whether an exception in the child should also be thrown in the parent or not. This change is expected in experimental builds soon.
- Once this change is available, we won't have to use:
- ❌
supervisorScopeorCoroutineScope(SupervisorJob())because we will be able to specify during thelaunchthat we want to handle our own exceptions - ❌ the (ugly) workaround of launching a cleanup coroutine
withContext(NonCancellable)because we will be able to specify during thelaunchthat we want this coroutine to be created even if the parent has been canceled - ❌ the trick of injecting a scope when you want to
launchcoroutines, but you don't want to tie their lifetime to a specific scope, because we will be able to specify during thelaunchthat we don't want our coroutine to be tied to a specific scope - There are no plans to modify the behavior of waiting for all the children to complete. That behavior is at the core of Structured Concurrency, and getting rid of that would mean the end of Structured Concurrency 😉
- Ultimately, the goal is to allow us developers to express our intent clearly and not get lost with special code that works around odd situations and edge cases.
- Support for Rich Errors. Vsevolod said that it was planned, but didn't know how or when this would happen.
- Gradual introduction of context parameters. This change would unblock quite a few use cases, such as the proper nesting of coroutine scopes with the respective names and also suspense properties (getters and setters). This change will likely take longer to be released.
I highly recommend using Santiago Mattiauda's Structured Coroutines plugin as it will look for coroutine antipatterns in your code and offer fixes to follow best practices.
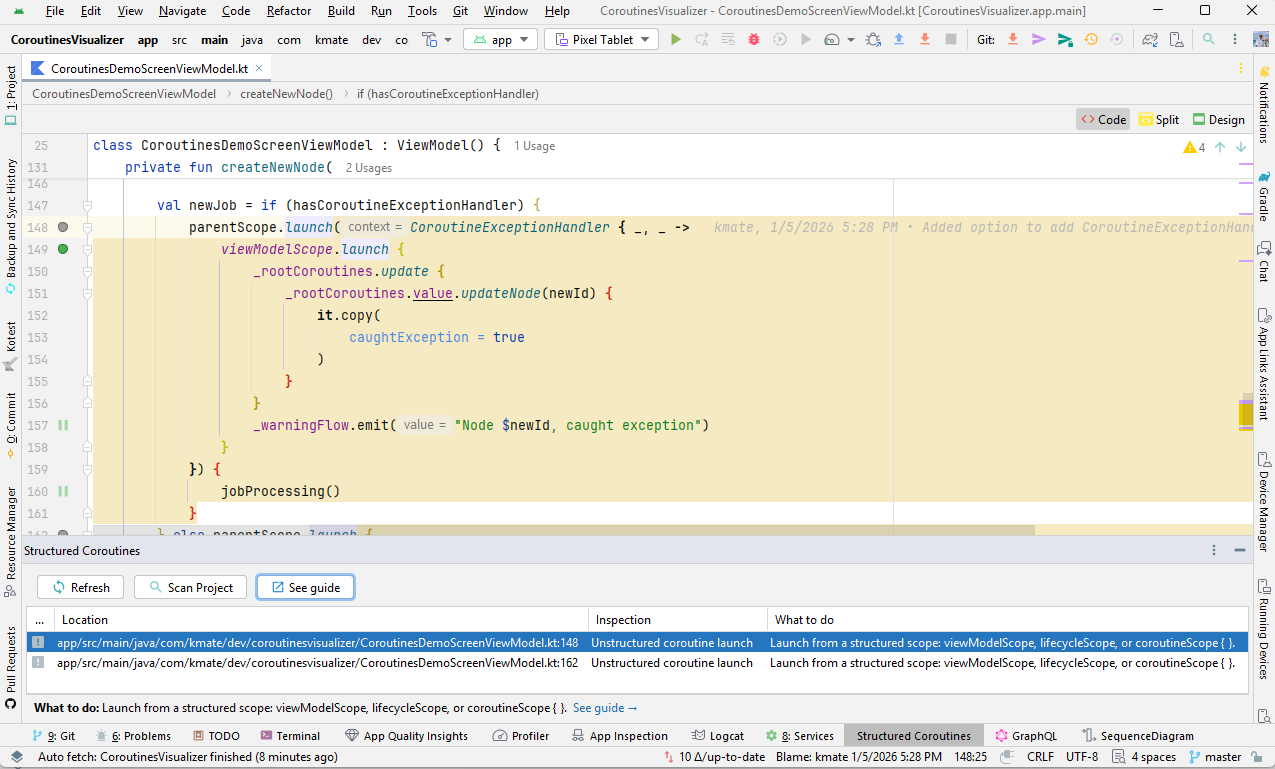
Sample screenshot
Clicking on the See guide button takes you here: 1.3 SCOPE_003 — Breaking Structured Concurrency
Java (and many other programming languages) used unstructured concurrency via
Thread or ExecutorService.In that model:
- Threads are not bound to a specific scope. They can easily outlive the function that started them. There is no automatic cancellation. You must manually keep track of
Futureobjects or thread references. - Error handling is manual and error-prone. If a background thread fails, the parent often is not aware.
With the introduction of Virtual Threads (Project Loom) and the Structured Concurrency API (JEP 453), Java is moving toward a model very similar to Kotlin's, using
StructuredTaskScope to ensure that subtasks are completed before the scope closes. Java always seems to play catch up with Kotlin. 🙃Sample code in Java:
// Java Invoice createInvoice(int orderId, int customerId, String language) throws InterruptedException { try (var scope = StructuredTaskScope.open()) { Subtask<Order> orderSubtask = scope.fork(() -> orderService.getOrder(orderId)); Subtask<Customer> customerSubtask = scope.fork(() -> customerService.getCustomer(customerId)); Subtask<InvoiceTemplate> invoiceTemplateSubtask = scope.fork(() -> invoiceTemplateService.getTemplate(language)); scope.join(); Order order = orderSubtask.get(); Customer customer = customerSubtask.get(); InvoiceTemplate template = invoiceTemplateSubtask.get(); return Invoice.generate(order, customer, template); } }
- Coroutine scope and Structured Concurrency - Official Kotlin Documentation
- Structured concurrency by Roman Elizarov
- Coroutines: first things first - Cancellation and Exceptions in Coroutines by Manuel Vivo
- Structured Coroutines by Santiago Mattiauda
- Kotlin Coroutines Best Practices by Santiago Mattiauda
- An Overview of Structured Concurrency by Shamil Gulmetov
- Coroutines Visualizer - A simple Android application that visualizes Coroutines Structured Concurrency and exceptions propagation/handling by Krystian Mateja
- Structured Concurrency in Java with StructuredTaskScope by Sven Woltmann
Hi! My name is Pato Moschcovich. I ❤️ Kotlin! I've been using it for over 4 years, and I enjoy it so much. My favorite thing is how expressive the language is and how simple it is to understand code and to write it. I am a Backend Software Engineer at a great company called Inductive Automation
Let's connect on LinkedIn
Let's connect on LinkedIn
