

The first big rule I was taught about programming was:
C> If you use copy-paste in your project, you are most likely doing something wrong.
This is a very simple heuristic, but it is also very wise. Even now, whenever I reflect on this I am amazed how well a single and clear sentence expresses the key idea behind the "Do not repeat knowledge" principle. This is also often known as the Don’t Repeat Yourself (DRY) principle, which comes from the Pragmatic Programmer book by Andy Hunt and Dave Thomas. Some developers might be familiar with the WET antipattern1, which sarcastically teaches us the same. DRY/WET are also strongly connected to the Single Source of Truth (SSOT) practice. As you can see, this rule is quite popular and has many names, but it is often misused or abused. To understand this rule and the reasons behind it clearly, we need to introduce a bit of theory.
Let’s define knowledge in programming broadly as any piece of intentional information. It could be code or data, or it could be a lack of code or data, which means that we want to use the default behavior. For instance, when we inherit and we don’t override a method, it’s like saying that we want this method to behave the same as in the superclass.
Everything in our projects is some kind of knowledge when it is defined this way. Of course, there are many different kinds of knowledge: how an algorithm should work, what a UI should look like, what result we wish to achieve, etc. There are also many ways to express knowledge: for example by using code, configurations, or templates. In the end, every single piece of our program is information that can be understood by some tool, virtual machine, or directly by other programs.
There are two particularly important kinds of knowledge in our programs:
- Logic - How we expect our program to behave and what it should look like.
- Common algorithms - Implementation of algorithms to achieve the desired behavior.
The main difference between these is that business logic changes a lot over time, while common algorithms generally do not change once they are defined. They might be optimized or we might replace one algorithm with another, but algorithms themselves are generally stable. Because of this difference, we’ll concentrate on algorithms in the next item. For now, let’s concentrate on the first point: the logic - knowledge about our program.
There is a saying that the only constant in programming is change. Just think about projects from 10 or 20 years ago, which isn’t a long time. Can you think of a single popular application or website that hasn’t changed for so many years? Android was released in 2008. The first stable version of Kotlin was released in 2016. Not only technologies but also languages change so quickly. Think about your old projects. Most likely now you would use different libraries, architecture, and design.
Changes often occur where we don’t expect them. There is a story that once, when Einstein was examining his students, one of them stood up and loudly complained that the questions were the same as the previous year. Einstein responded that it was true but the answers were totally different that year. Even things that you think are constant because they are based on law or science might change one day. Nothing is absolutely safe.
Standards of UI design and technologies change much faster. Our understanding of clients often needs to change on a daily basis. This is why the knowledge in our projects will also change. For instance, here are some very typical reasons for these changes:
- A company learns more about its users’ needs or habits.
- Design standards change.
- We need to adjust to changes in a platform, libraries, or tools.
Most projects nowadays change their requirements and parts of internal structure every few months. This is often something desired. Many popular management systems are agile and can support constant changes in requirements. Slack was initially a game named Glitch2. The game didn’t work out, but customers liked its communication features.
Things change, and we should be prepared for that. The biggest enemy of change is knowledge repetition. Just think for a second: what if we need to change something that is repeated in many places in our program? The simplest answer is that, in such a case, you just need to search for all the places where this knowledge is repeated and change it everywhere. Searching can be frustrating, and it is also troublesome: What if you forget to change some repetitions? What if some of them have already been modified because they were integrated with other functionalities? It might be tough to change them all in the same way. These are real problems.
To make the problem less abstract, think of a universal button used in many different places in a project. If our graphic designer decides that this button needs to be changed, we would have a problem if we defined how it looks in every single usage. We would need to search our whole project and change every single instance separately. We would also need to ask the testers to check that we haven’t missed any instances.
Another example: Let’s say that we use a database in our project, then one day, we change the name of a table. If we forget to adjust all SQL statements that depend on this table, we might have a very problematic error. If we had a table structure that is defined only once, we wouldn’t have such a problem.
In both examples, you can see how dangerous and problematic knowledge repetition is. It makes projects less scalable and more fragile. The good news is that we programmers have worked for years on tools and features that help us eliminate knowledge redundancy. On most platforms, we can define a custom style for a button or a custom view/component to represent it. Instead of writing SQL in text format, we can use an ORM (like Hibernate) or a DAO (like Exposed).
All these solutions represent different kinds of abstractions, and they protect us from different kinds of redundancy. An analysis of different kinds of abstractions is presented in Item 26: Use abstraction to protect code against changes.
There are situations where we can see two pieces of code that are similar but should not be extracted into one. In this case, they look similar but represent different knowledge.
Let’s start with an example. Let’s say we have two independent Android applications in the same project. Their build tool configurations are similar, so it might be tempting to extract them. But what if we do that? These two applications are independent, so if we need to change something in the configuration, we will most likely need to change it in only one of them. Changes after this reckless extraction are harder, not easier. Configuration reading is harder as well. Configurations have boilerplate code, but developers are already familiar with it. Making abstractions means designing our own API, but it is another thing to learn for a developer using this API. This is a perfect example of how problematic it is to extract something that is not conceptually the same knowledge.
The most important question to ask ourselves when we decide if two pieces of code represent similar knowledge is: Are they more likely to change together or separately? Pragmatically, this is the most important question because this is the biggest result of extracting a common part: it is easier to change them both at the same time, but harder to change only one usage.
One useful heuristic is that if business rules come from different sources, we should assume that they are more likely to change independently. For such a case, we even have a rule that protects us from unintended code extraction. It is called the Single Responsibility Principle.
A very important rule that teaches us when we should not extract common code is the Single Responsibility Principle from SOLID. It states that "A class should have only one reason to change". This rule3 can be simplified by the statement that there should be no situations in which two actors need to change the same class. By actor, we mean the source of a change. Actors are often developers from different departments who know little about each other’s work and domains. Even if there is only a single developer in a project, there might be multiple managers, each of which should be treated as a separate actor. These are two sources of changes that know little about each other's domains. The situation in which two actors edit the same piece of code is especially dangerous.
Let’s see an example. Imagine that we work for a university, and we have a
Student class. This class is used by both the Scholarships Department and the Accreditations Department. Developers from those two departments have introduced two different functions:-
isPassingwas created by the Accreditations Department and answers the question of whether a student is passing. -
qualifiesForScholarshipwas created by the Scholarships Department and answers the question of whether a student has enough points to qualify for a scholarship.
Both functions need to calculate how many points a student collected in the previous semester, so a developer extracted a function
calculatePointsFromPassedCourses.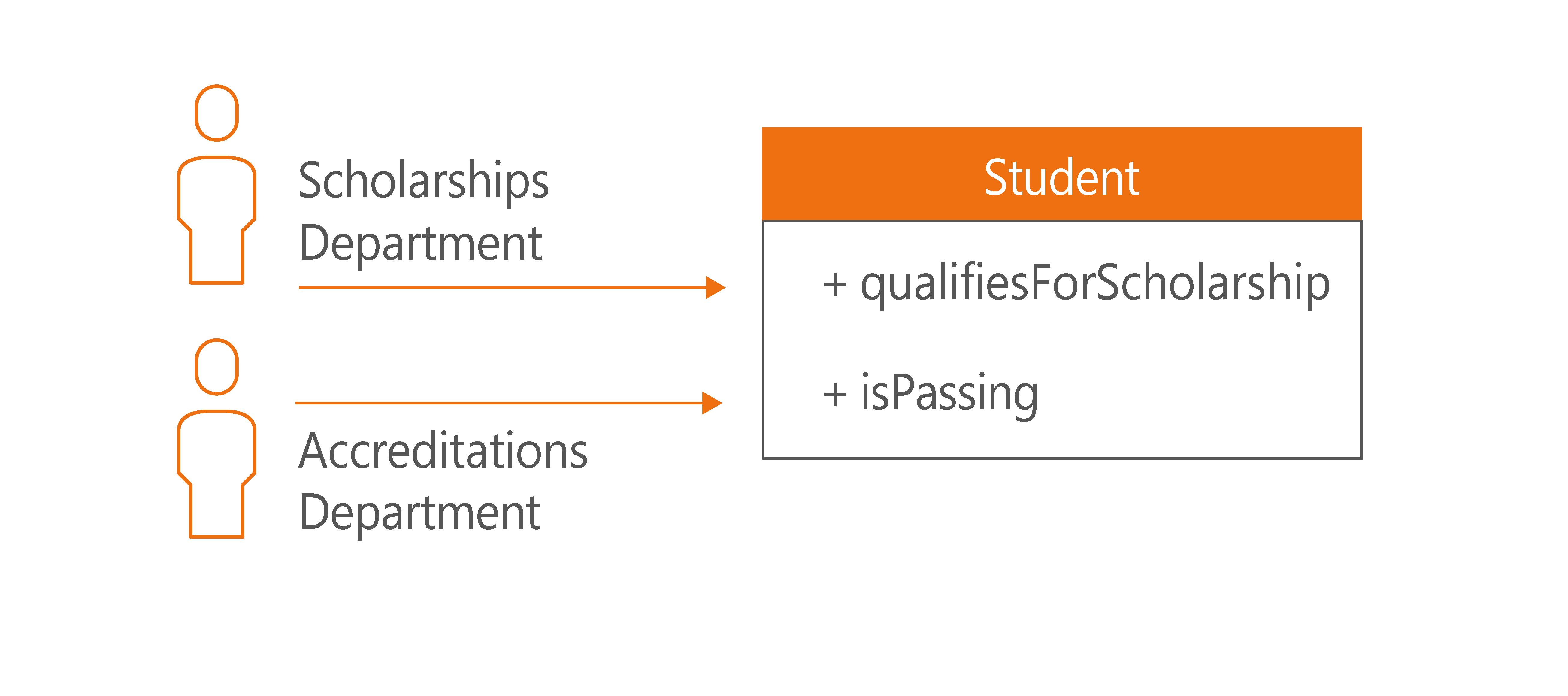
class Student { // ... fun isPassing(): Boolean = calculatePointsFromPassedCourses() > 15 fun qualifiesForScholarship(): Boolean = calculatePointsFromPassedCourses() > 30 private fun calculatePointsFromPassedCourses(): Int { //... } }
Then, the original rules changed, and the dean decided that less important courses should not qualify for the scholarship points calculation. The developer who was tasked with introducing this change checks the
qualifiesForScholarship function, finds that it calls the private method calculatePointsFromPassedCourses, and changes it to omit courses that do not qualify. Unintentionally, that developer changed the behavior of isPassing as well. Students who were supposed to pass were informed that they had failed the semester. You can imagine their reaction4.It is true that we could easily prevent such a situation if we had unit tests (Item 8: Write unit tests), but let’s skip this aspect for now.
The developer might check where else the function is used. However, the problem is that this developer didn’t know that this private function was used by another property with a totally different responsibility. Private functions are rarely used by more than one function.
The problem, in general, is that it is easy to couple responsibilities located very close to each other (in the same class/file). A simple solution would be to extract these responsibilities into separate classes. We might have separate
StudentIsPassingValidator and StudentQualifiesForScholarshipValidator classes, but in Kotlin, we don’t need to use such heavy artillery (see more in Chapter 4: Design abstractions). We can just define qualifiesForScholarship andcalculatePointsFromPassedCourses as extension functions on Student that are located in separate modules: one for which the Scholarships Department is responsible, and another for which the Accreditations Department is responsible.// scholarship module fun Student.qualifiesForScholarship(): Boolean { /*...*/ } // accreditations module fun Student.calculatePointsFromPassedCourses(): Boolean { /*...*/ }
What about extracting a function for calculating results? We can do this, but it cannot be a private function that is used as a helper for both of these methods. Instead, it can be:
- A general public function defined in a module used by both departments. In such a case, the common part is treated as something common, so a developer should not change it without modifying the contract and adjusting usages.
- Two separate helper functions, one for each department.
Both options are safe. The Single Responsibility Principle teaches us two things:
- Knowledge from two different sources (here, two different departments) is very likely to change independently, so we should treat these sources as two different types of knowledge.
- We should separate different types of knowledge because otherwise it is tempting to reuse parts of our code that should not be reused.
Everything changes and it is our job to prepare for that: to recognize common knowledge and extract it. If some elements have similar parts that we will likely need to change for all instances, extract them as this will save time on searching through the project to update many instances. On the other hand, protect yourself from unintentional modifications by separating parts from different sources. Often, this is the most important side of the problem. I see many developers who are so terrified of the literal meaning of "Don't Repeat Yourself" that they tend to look suspiciously at any 2 lines of code that look similar. Both extremes are unhealthy, and we need to always search for a balance. Sometimes, it is a tough decision whether something should be extracted or not. This is why designing information systems well is an art that requires time and a lot of practice.
- Stands for We Enjoy Typing, Waste Everyone's Time or Write Everything Twice. ↩
- See the presentation How game mechanics can drive product loyalty by Ali Rayl. ↩
- As described by the software engineer Robert C. Martin in his book Clean Architecture. ↩
- I imagine an angry mob of students storming university edifice with torches and rulers. Sounds abstract? Then read about St Scholastica Day riot. ↩
