

Walking on water and developing software from a specification are easy if both are frozen
-- Edward V Berard ; Essays on object-oriented software engineering, p. 46
When we hide actual code behind abstractions like functions or classes, we not only protect users from these details, but we also give ourselves the freedom to change this code later, often without users even being aware of it. For instance, when you extract a sorting algorithm into a function, you can later optimize its performance without changing the way it is used.
Returning to the car metaphor mentioned previously, car manufacturers and mechanics can change everything under the hood of a car, and as long as the operation remains the same, a user won’t notice. This gives manufacturers the freedom to make more environmentally friendly cars or to add more sensors to make them safer.
In this item, we will see how different kinds of abstractions give us freedom by protecting us from a variety of changes. We’ll examine three practical cases, then we’ll discuss finding a balance in terms of the number of abstractions we create. Let’s start with the simplest kind of abstraction: constant value.
Literal constant values are rarely self-explanatory and are especially problematic when they repeat in our code. Moving these values into constant properties not only assigns a meaningful name to them, it also helps us better manage the values of these constants when they need to be changed. Let’s see a simple example with password validation:
fun isPasswordValid(text: String): Boolean { if(text.length < 7) return false //... }
The number 7 can be understood on the basis of the context, but it would be easier if it were extracted into a constant:
const val MIN_PASSWORD_LENGTH = 7 fun isPasswordValid(text: String): Boolean { if(text.length < MIN_PASSWORD_LENGTH) return false //... }
With that, it is easier to modify the minimum password size. We don’t need to understand the validation logic; instead, we can just change this constant. This is why it is especially important to extract values that are used more than once. For instance, the maximum number of threads that can connect to our database at the same time:
val MAX_THREADS = 10
Once this value has been extracted, you can easily change it whenever you need. Just imagine how hard it would be to change it if this number was spread all over the project.
As you can see, extracting a constant:
- Names it
- Helps us change its value in the future
We will also see similar results for different kinds of abstractions.
Imagine that you are developing an application and you notice that you often need to display a toast message to users. This is how you do it programmatically:
Toast.makeText(this, message, Toast.LENGTH_LONG).show()

Toast message in Android
We can extract this common algorithm into a simple extension function that displays toast messages:
fun Context.toast( message: String, duration: Int = Toast.LENGTH_LONG ) { Toast.makeText(this, message, duration).show() } // Usage context.toast(message) // Usage in Activity or subclasses of Context toast(message)
This change helps us extract a common algorithm so that we don’t need to remember how to display a toast every time. It would also help if the way to display a toast, in general, changed (which is rather unlikely), but there are still other kinds of changes we are not prepared for.
What if we had to change the way we display messages to users from toasts to snackbars (a different kind of message display)? A simple answer is that by having extracted this functionality, we can just change the implementation inside this function and rename it.
fun Context.snackbar( message: String, length: Int = Toast.LENGTH_LONG ) { //... }

Snackbar message in Android
This solution is far from perfect. First of all, renaming the function might be dangerous even if it is used only internally1, especially if other modules depend on this function. The next problem is that parameters cannot be automatically changed so easily, thus we are still stuck with the toast API to declare the message duration. This is very problematic. When we display a snackbar, we should not depend on a field from
Toast. On the other hand, changing all usages to use the Snackbar's enum would also be problematic:fun Context.snackbar( message: String, duration: Int = Snackbar.LENGTH_LONG ) { //... }
When we know that the way the message is displayed might change, we know that what is really important is not how this message is displayed but that we want to be able to display messages to users. What we need is a more abstract method to display a message. Having that in mind, a programmer could hide the toast display behind a higher-level function
showMessage, which would be independent of the concept of toast:fun Context.showMessage( message: String, duration: MessageLength = MessageLength.LONG ) { val toastDuration = when(duration) { SHORT -> Toast.LENGTH_SHORT LONG -> Toast.LENGTH_LONG } Toast.makeText(this, message, toastDuration).show() } enum class MessageLength { SHORT, LONG }
The biggest change here is the name. Some developers might neglect the importance of this change and say that a name is just a label, which doesn’t matter. This perspective is valid from the compiler’s point of view, but not from a developer’s point of view. A function represents an abstraction, and the signature of this function informs us what abstraction it is. A meaningful name is very important.
A function is a very simple abstraction, but it is also very limited. A function does not hold a state. Changes in a function signature often influence all usages. A more powerful way to abstract away implementation is by using classes.
Here is how we can abstract displaying messages into a class:
class MessageDisplay(val context: Context) { fun show( message: String, duration: Length = Length.LONG ) { val toastDuration = when(duration) { SHORT -> Toast.LENGTH_SHORT LONG -> Toast.LENGTH_LONG } Toast.makeText(context, message, toastDuration) .show() } enum class Length { SHORT, LONG } } // Usage val messageDisplay = MessageDisplay(context) messageDisplay.show("Message")
The key reason why classes are more powerful than functions is that they can hold a state and expose many functions (class member functions are called methods). In this case, we have a
context in the class state, and it is injected via the constructor. By using a dependency injection framework, we can delegate the class creation:@Inject lateinit var messageDisplay: MessageDisplay
Additionally, we can mock a class to test the functionality of other classes that depend on it.
val messageDisplay: MessageDisplay = mockk()
Furthermore, one could add more methods to set up the message display:
messageDisplay.setChristmasMode(true)
As you can see, classes give us more freedom, but they still have limitations. For instance, when a class is final, we know what exact implementation is under its type. We have a bit more freedom with open classes because we could serve a subclass instead. This abstraction is still strongly bound to this class though. To get more freedom we can make our implementation even more abstract and hide this class behind an interface.
When reading the Kotlin standard library, you might notice that nearly everything is represented as an interface. Just take a look at a few examples:
-
The
listOffunction returnsList, which is an interface. This is similar to other factory methods (we will explain them in Item 32: Consider factory functions instead of secondary constructors). -
Collection processing functions are extension functions on
IterableorCollection, and they returnList,Map, etc. These are all interfaces. -
Property delegates are hidden behind
ReadOnlyPropertyorReadWriteProperty, which are also interfaces. Actual classes are often private. Thelazyfunction also declares theLazyinterface as its return type.
It is common practice for library creators to restrict the visibility of inner classes and expose them from behind interfaces, and there are good reasons for that. This way, library creators are sure that users do not use these classes directly, so they can change their implementations without any worries, as long as the interfaces stay the same. This is exactly the idea behind this item: by hiding objects behind an interface, we abstract away any actual implementation and we force users to depend only on this abstraction. This way, we reduce coupling.
In Kotlin, there is another reason behind returning interfaces instead of classes: Kotlin is a multiplatform language and the same
listOf returns different list implementations for Kotlin/JVM, Kotlin/JS, and Kotlin/Native. This is an optimization as Kotlin generally uses platform-specific native collections, which is fine because they all respect the List interface.Let’s see how we can apply this idea to our message display. This is how it could look when we hide our class behind an interface:
interface MessageDisplay { fun show( message: String, duration: Length = LONG ) } class ToastDisplay(val context: Context): MessageDisplay { override fun show( message: String, duration: Length ) { val toastDuration = when(duration) { SHORT -> Toast.LENGTH_SHORT LONG -> Toast.LENGTH_LONG } Toast.makeText(context, message, toastDuration) .show() } enum class Length { SHORT, LONG } }
In return, we’ve got more freedom. For instance, we can inject the class that displays toasts on tablets and snackbars on phones. One might also use
MessageDisplay in a common module shared between Android, iOS, and Web. Then, we could have a different implementation for each platform. For instance, on iOS and Web, it could display an alert.Another benefit is that interface faking for testing is simpler than class mocking, and it does not need a mocking library:
val messageDisplay: MessageDisplay = TestMessageDisplay()
Finally, the declaration is more decoupled from the usage, so we have more freedom in changing actual classes like
ToastDisplay. On the other hand, if we want to change the way it is used, we would need to change the MessageDisplay interface and all the classes that implement it.Let’s discuss one more example. Let’s say that we need a unique ID in our project. A very simple way is to have a top-level property to hold the next ID and increment it whenever we need a new ID:
var nextId: Int = 0 // Usage val newId = nextId++
Seeing such usage spread around our code should cause some alerts. What if we wanted to change the way IDs are created? Let’s be honest, this way is far from perfect:
- We start at 0 whenever we cold-start our program.
- It is not thread-safe.
If we accept this solution for now, we should protect ourselves from change by extracting ID creation into a function:
private var nextId: Int = 0 fun getNextId(): Int = nextId++ // Usage val newId = getNextId()
Notice this solution only protects us from the need to change the way how ID is created. There are many changes that we are still prone to, the biggest of which is a change of ID type. What if one day we need to store ID as a
String? Also notice that someone who sees that ID is represented as an Int might use some type-dependent operations. For instance, use comparison to check which ID is older. Such assumptions might lead to serious problems. To prevent this and to make it easy to change ID type in the future, we might extract ID as a class:data class Id(private val id: Int) private var nextId: Int = 0 fun getNextId(): Id = Id(nextId++)
Once again, it is clear that more abstractions give us more freedom, but they also make definitions and their usage harder to define and understand.
We’ve presented a few common ways to introduce abstraction:
- Extracting constants
- Wrapping behaviors into functions
- Wrapping functions into classes
- Hiding classes behind interfaces
- Wrapping universal types into context-specific types
We’ve shown how each of these give us different kinds of freedom. Notice that there are many more options available, such as:
- Using generic type parameters
- Extracting inner classes
- Restricting creation, for instance by forcing object creation via factory methods2
On the other hand, there is a dark side to abstractions. They give us freedom and separate code, but they can often make code harder to understand and modify. Let’s talk about problems with abstractions.
Adding new abstractions requires readers of our code to learn or already be familiar with specific concepts. When we define another abstraction, it is another thing that needs to be understood in our project. Of course, this is less of a problem when we restrict the visibility of our abstractions (Item 29: Minimize elements’ visibility) or when we define abstractions that are used only for concrete tasks. This is why modularity is so important in bigger projects. We need to understand that defining abstractions incurs this cost, therefore we should not abstract everything by default.
We can infinitely extract abstractions, but this will soon do more harm than good. This fact was parodied in the FizzBuzz Enterprise Edition project3, where the authors showed that even for such a simple problem as Fizz Buzz4, one can extract a ridiculous amount of abstractions, which ends up making this solution extremely hard to comprehend and work on. At the time of writing this book, in the project, there are 61 classes and 26 interfaces. All that, to solve a problem that generally requires less than 10 lines of code. Sure, applying changes at any level is easy, but understanding what this code does and how it does it is extremely hard.
Abstractions can hide a lot. On the one hand, it is easier to do development when there is less to think about; on the other hand, it becomes harder to understand the consequences of our actions when we use too many abstractions. You might use the
showMessage function and think that it still displays toast, but you might be surprised when it displays a snackbar. When you see that an unintended toast message is displayed, you might look for Toast.makeText and have problems finding it because it is displayed using showMessage. Having too many abstractions makes it harder to understand our code. It can also make us anxious when we are not sure what the consequences of our actions are.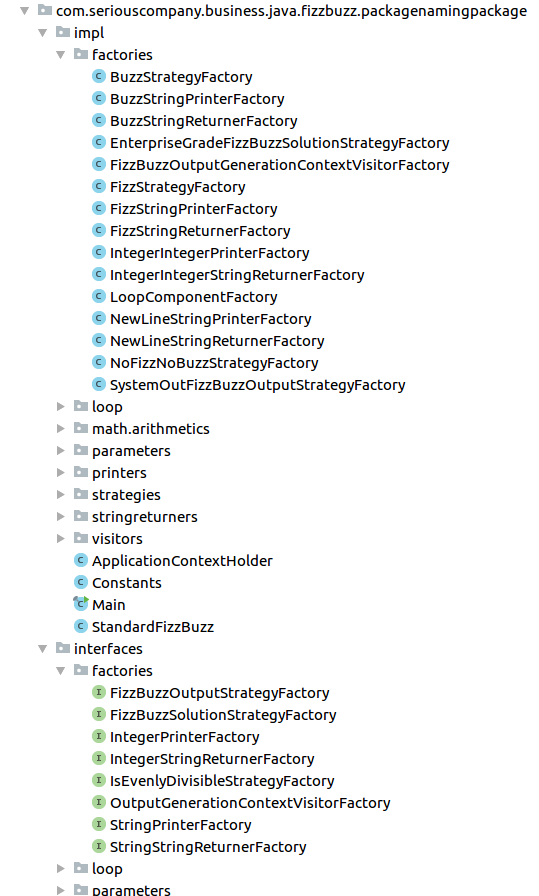
*Part of the FizzBuzz Enterprise Edition structure of classes. In the description of this project, you can find the following sarcastic rationale: “This project is an example of how the popular FizzBuzz game might be built were it subject to the high-quality standards of enterprise software.” *
To understand abstractions, examples are very helpful. Abstractions are made more real for us by unit tests or examples in the documentation that show how an element can be used. For the same reason, I filled this book with concrete examples for most ideas I present. It is hard to understand abstract descriptions, and it is also easy to misunderstand them.
The rule of thumb is: every level of complexity gives us more freedom and organizes our code, but also makes it harder to understand what is really going on in our project. Both extremes are bad. The best solution is always somewhere in the middle, but where exactly this is depends on many factors, like:
- Team size
- Team experience
- Project size
- Feature set
- Domain knowledge
We are constantly looking for balance in every project. Finding a proper balance is almost an art as it requires intuition gained over hundreds if not thousands of hours architecting and coding projects. Here are a few suggestions I can give:
- In bigger projects with more developers, it is much harder to change object creation and usage later, so we prefer more abstract solutions. Also, separation between modules or parts is especially useful in such projects.
- We care less about how difficult creation is when we use a dependency injection framework because we probably only need to define this creation once anyway.
- Testing or making different application variants might require us to use some abstractions.
- When your project is small and experimental, you can enjoy your freedom to directly make changes without the necessity of dealing with abstractions. However, when your project gets serious, organize it as soon as possible.
Another thing that we need to constantly think about is what might change and what are the odds of each change. For instance, there is only a very small chance that the API for the toast display will change, but there is a reasonable probability that we will need to change the way we display a message. Is there a chance we might need to mock this mechanism? Is there a chance that one day you will need a more generic mechanism or a mechanism that might be platform-independent? These probabilities are not 0, so how big are they? Observing how things change over the years gives us better and better intuition.
Abstractions are not only to eliminate redundancy and to organize our code: they also help us when we need to change our code. Although using abstractions makes our code harder to understand. Abstractions are something we need to learn and understand. It is also harder to understand the consequences of using abstract structures. That is why we need to understand both the importance and risk of using abstractions, and we need to search for a balance in every project, as having too many or too few abstractions is not ideal.
- When a function is a part of an external API, we cannot easily adjust calls and so we are stuck with the old name for at least some time (Item 27: Specify API stability). ↩
- More about this in Chapter 4: Object creation. ↩
- github.com/EnterpriseQualityCoding/FizzBuzzEnterpriseEdition ↩
- The problem is defined as: For numbers 1 through 100, if a number is divisible by 3, print Fizz; if a number is divisible by 5, print Buzz; if a number is divisible by both 3 and 5 (e.g., 15), print FizzBuzz; in all other cases, print the number. ↩
