

If you want to run asynchronous or non-blocking code in Kotlin, you have to run it inside a
CoroutineScope. If you’re dealing with callbacks, you have to convert it to a suspending function with suspendCancellableCoroutine so that you can call it inside a CoroutineScope:@ExperimentalCoroutinesApi suspend fun Blah.doSomethingSuspending() = suspendCancellableCoroutine { continuation -> this.onSuccess { continuation.resume( value = it, onCancellation = continuation::cancel ) } this.onError { continuation.resumeWithException(exception = it) } this.onCancel { continuation.cancel(cause = it) } }
For blocking code, unfortunately, you are stuck with
Dispatchers.IO, which is a giant thread pool where each dispatch is still blocking a thread:withContext(Dispatchers.IO) { blockingFunction() }
What if instead of blocking a regular thread, we run it on one of Project Loom’s virtual threads, effectively turning the blocking code into something non-blocking while still being Coroutine compatible?
withContext(Dispatchers.LOOM) { blockingFunction() }
For this to work, let’s first enable JDK19’s preview features with some VM options so that we can make use of virtual threads:
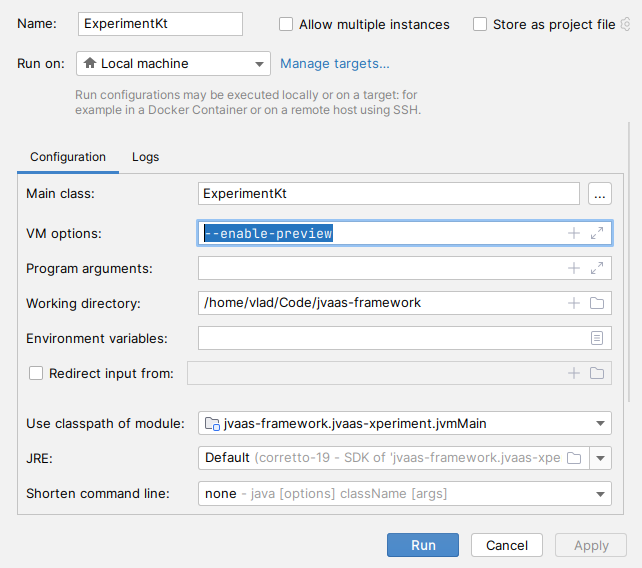
Next, we need to define our custom Dispatcher. If you want to customize how the Dispatcher works, you can extend ExecutorCoroutineDispatcher …
val Dispatchers.LOOM: CoroutineDispatcher get() = object : ExecutorCoroutineDispatcher(), Executor { override val executor: Executor get() = this override fun close() { error("Cannot be invoked on Dispatchers.LOOM") } override fun dispatch(context: CoroutineContext, block: Runnable) { Thread.startVirtualThread(block) } override fun execute(command: Runnable) { Thread.startVirtualThread(command) } override fun toString() = "Dispatchers.LOOM" }
or we can create an ExecutorService and convert it to a Dispatcher:
val Dispatchers.LOOM: CoroutineDispatcher get() = Executors.newVirtualThreadPerTaskExecutor().asCoroutineDispatcher()
We’ll use
Thread.sleep as a placeholder for blocking functions: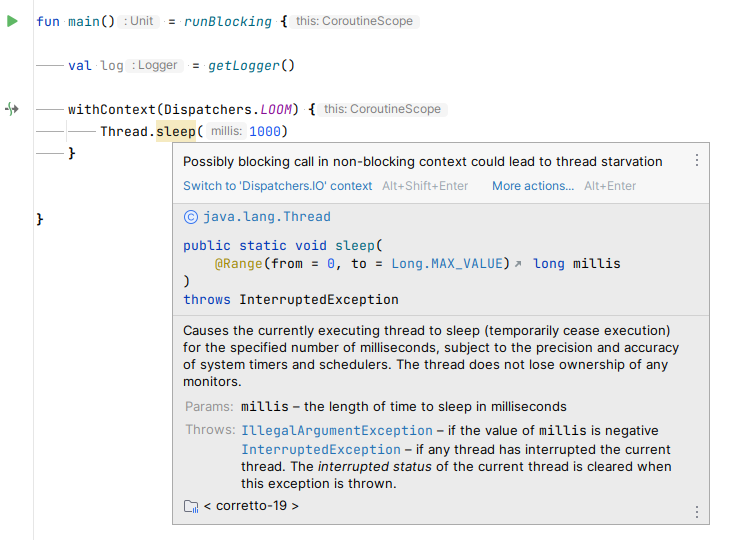
IntelliJ warns us that
Thread.sleep is a blocking function inside a non-blocking context, even though our goal is to run blocking code inside this context. Let’s get rid of this warning.val Dispatchers.LOOM: @BlockingExecutor CoroutineDispatcher get() = Executors.newVirtualThreadPerTaskExecutor().asCoroutineDispatcher()
If we include JetBrains Java Annotations (org.jetbrains:annotations) as a dependency, we get access to @BlockingExecutor, which marks our CoroutinesDispatcher as blocking-compatible.
Let’s launch a million blocking calls and see how long it takes! We’ll be using supervisory scope so that we can wait for all 1 million launches to finish before capturing the duration.
If we’re using
Dispatchers.IO, we’re expecting the total duration to be 1 million x 1000 ms / 64 actual threads, which should be roughly 4 hours and 20 minutes (assuming IO_PARALLELISM_PROPERTY_NAME was left untouched at its default of 64)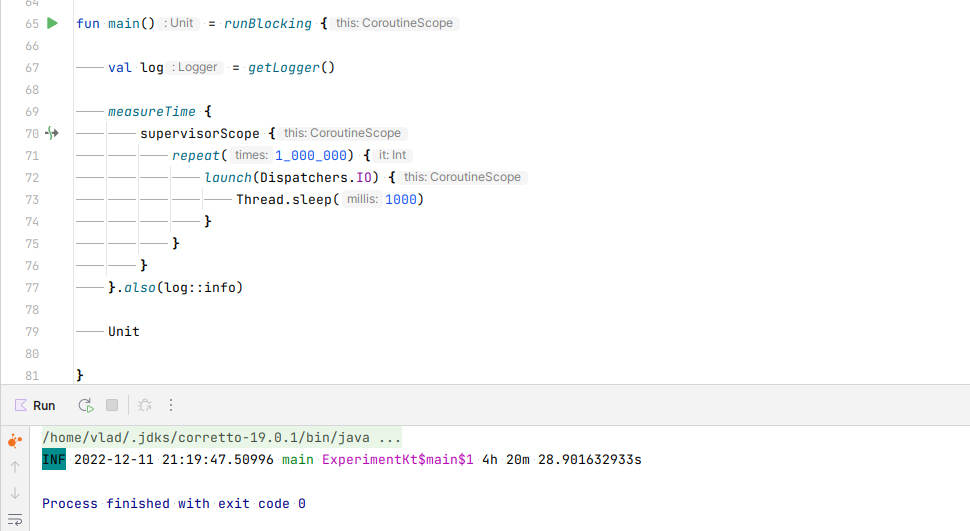
Nothing stops you from doing
Dispatchers.IO.limitedParallelism(1_000_000), but let me know how long your computer runs before it becomes completely unresponsive.If we use something more realistic like 5_000, we can expect the total duration to be 1 million x 1000ms / 5000 actual threads, which should be roughly 3 minutes and 20 seconds

If I push for 10_000 threads, my computer just becomes completely unresponsive, so that seems to be bordering on how fast we can go using
Dispatchers.IO.Launching the same number of blocking calls inside our LOOM Dispatcher, we’re expecting the total duration to be 1 million x 1000 ms / 1 million virtual threads, and we should finish in roughly 1 second, assuming JVM warmup and no overheads.
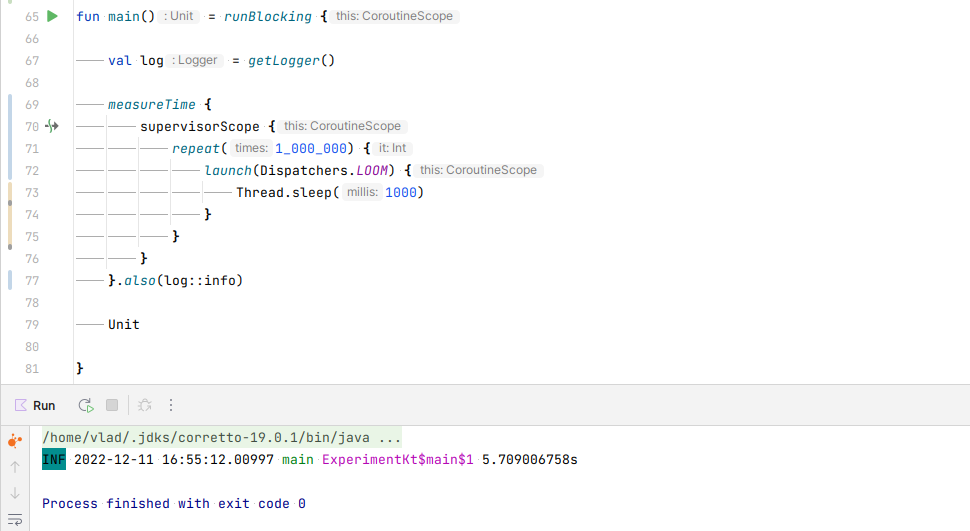
In the real world, however, we have some overhead, and not warming up the JVM will penalize us too, so we end up with ~6 seconds instead of the predicted 1 second. Still, that is +30x faster than what we could achieve with
Dispatchers.IO.If we compare this with launching 1 million non-blocking calls in a
CoroutineScope, we’re expecting a duration in the same ballpark.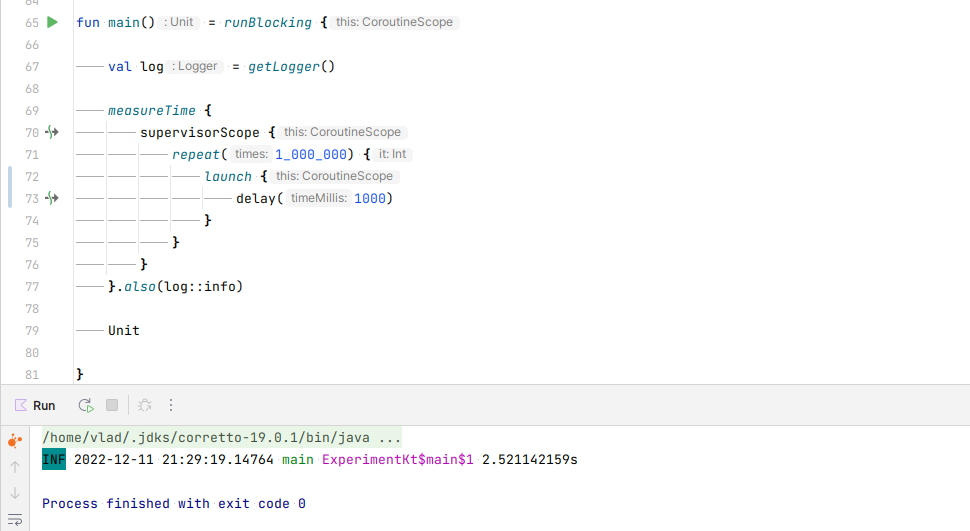
Let’s compare some under-the-hood stats!
If we launch a million
Thread.sleeps inside Dispatchers.IO with parallelism set to 5000, notice how the CPU consumption is almost zero most of the time and the number of threads being 5556. Threads context switching seems to be our limiting factor here rather than CPU / Memory.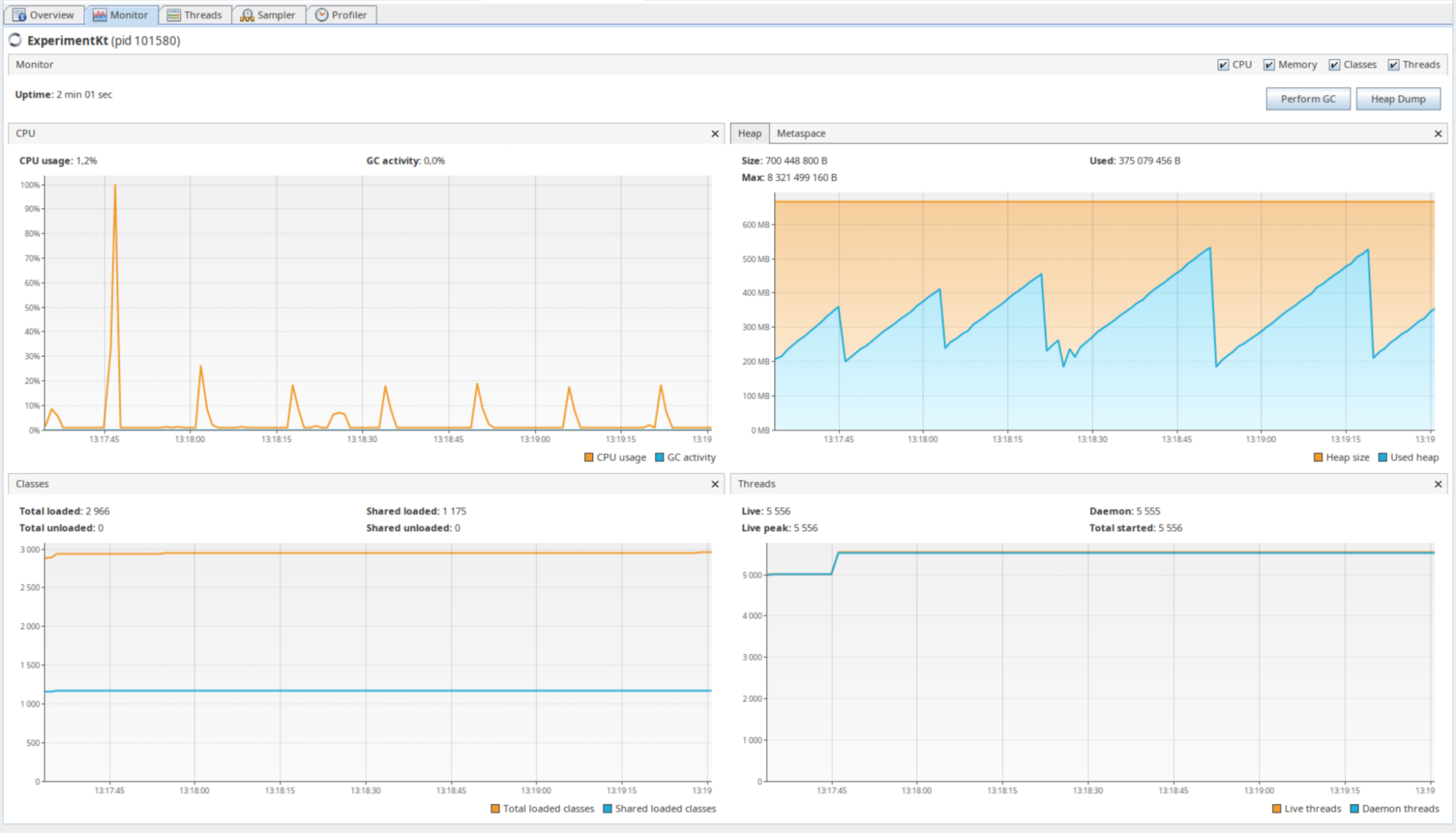
If we launch a million
Thread.sleeps inside Dispatchers.LOOM, you can see the thread count stays relatively low peaking at 30, but it maximizes CPU usage.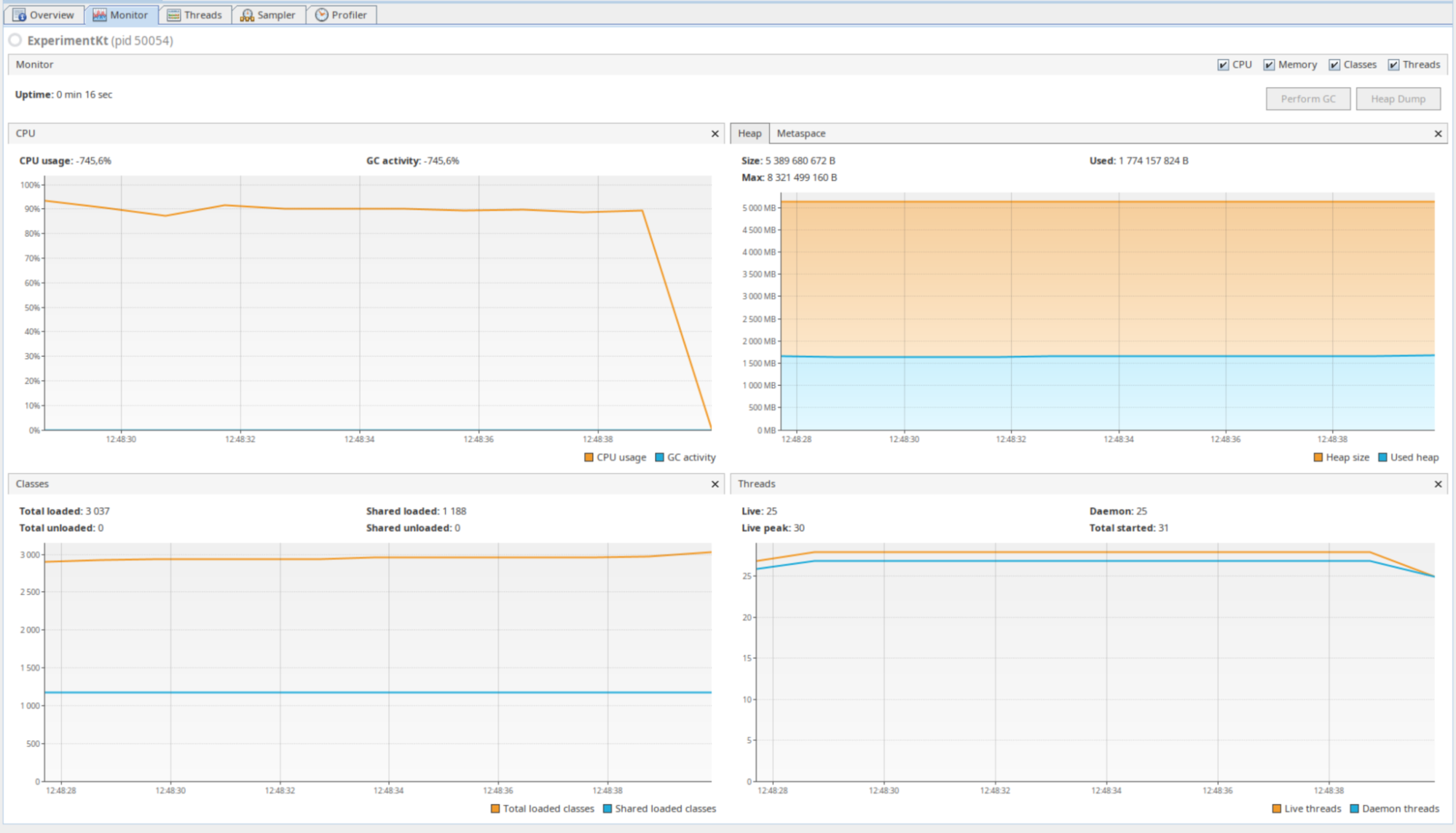
Of those 30 threads, 12 are worker threads that are there by default when using Coroutines (equivalent to the number of CPU cores) and 1 thread is marked “VirtualThread-unparker” while the rest are related to IntelliJ and / or VisualVM.

In conclusion: with our custom LOOM Dispatcher, we are now able to convert blocking code into non-blocking coroutine-compatible code instead of being limited by
Dispatchers.IO.
