

The Channel API was added as an inter-coroutine communication primitive. Many imagine a channel as a pipe, but I prefer a different metaphor. Are you familiar with public bookcases for exchanging books? One person needs to bring a book for another person to find it. This is very similar to how
Channel from kotlinx.coroutines works.
Channel supports any number of senders and receivers, and every value that is sent to a channel is received only once.
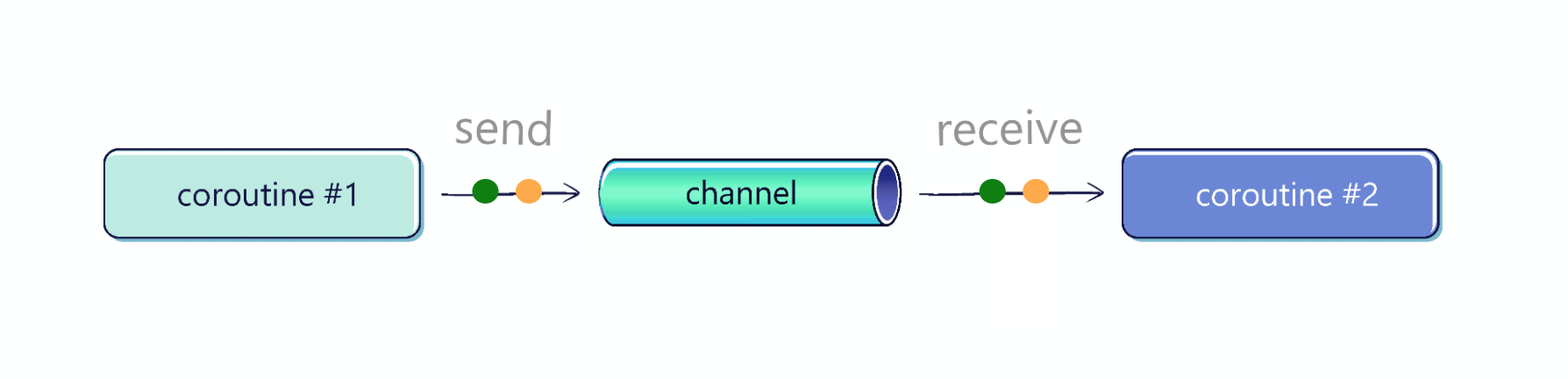
Channel is an interface that implements two other interfaces:SendChannel, which is used to send elements (adding elements) and to close the channel;ReceiveChannel, which receives (or takes)the elements.
interface SendChannel<in E> { suspend fun send(element: E) fun close(): Boolean //... } interface ReceiveChannel<out E> { suspend fun receive(): E fun cancel(cause: CancellationException? = null) // ... } interface Channel<E> : SendChannel<E>, ReceiveChannel<E>
Thanks to this distinction, we can expose just
ReceiveChannel or SendChannel in order to restrict the channel entry points.You might notice that both
send and receive are suspending functions. This is an essential feature:- When we try to
receiveand there are no elements in the channel, the coroutine is suspended until the element is available. Like in our metaphorical bookshelf, when someone goes to the shelf to find a book but the bookshelf is empty, that person needs to suspend until someone puts an element there. - On the other hand,
sendwill be suspended when the channel reaches its capacity. We will soon see that most channels have limited capacity. Like in our metaphorical bookshelf, when someone tries to put a book on a shelf but it is full, that person needs to suspend until someone takes a book and makes space.
If you need to send or receive from a non-suspending function, you can usetrySendandtryReceive. Both operations are immediate and returnChannelResult, which contains information about the success or failure of the operation, as well as its result. UsetrySendandtryReceiveonly for channels with limited capacity because they will not work for the rendezvous channel.
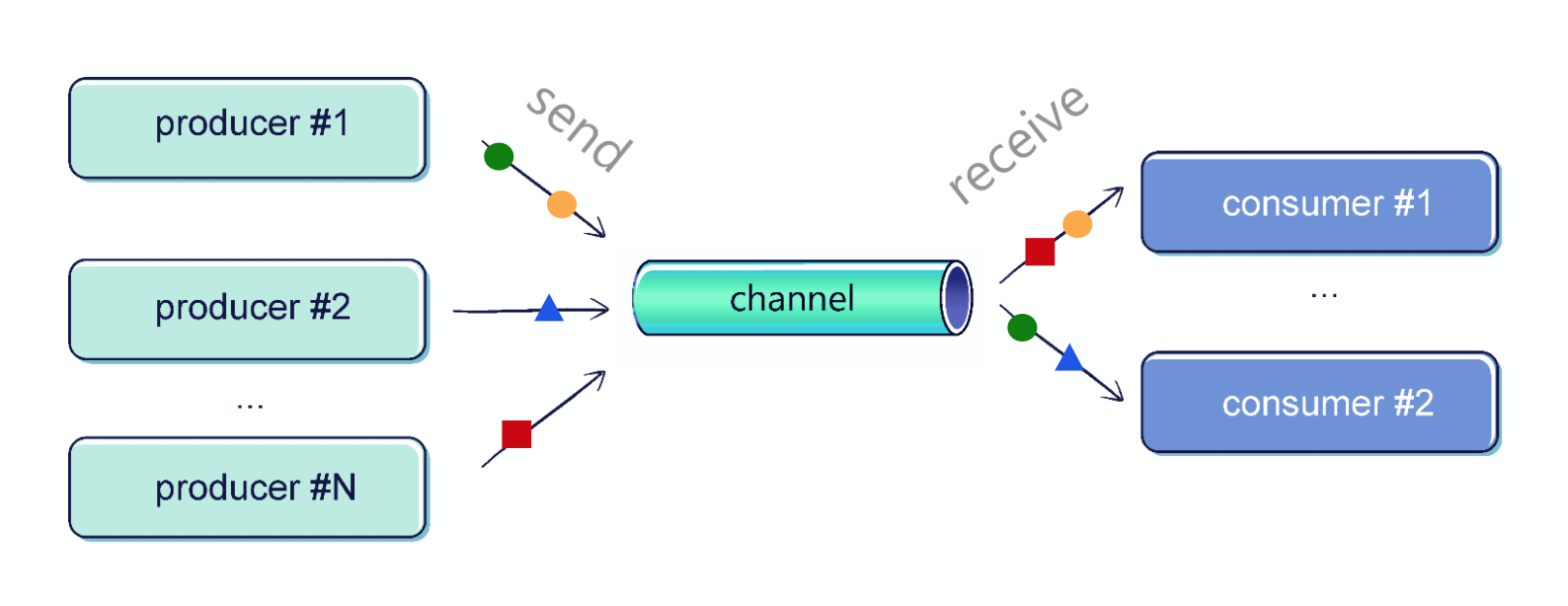
A channel might have any number of senders and receivers. However, the most common situation is when there is one coroutine on both sides of the channel.
To see the simplest example of a channel, we need to have a producer (sender) and a consumer (receiver) in separate coroutines. The producer will send elements, and the consumer will receive them. This is how it can be implemented:
import kotlinx.coroutines.* import kotlinx.coroutines.channels.Channel //sampleStart suspend fun main(): Unit = coroutineScope { val channel = Channel<Int>() launch { repeat(5) { index -> delay(1000) println("Producing next one") channel.send(index * 2) } } launch { repeat(5) { val received = channel.receive() println(received) } } } // (1 sec) // Producing next one // 0 // (1 sec) // Producing next one // 2 // (1 sec) // Producing next one // 4 // (1 sec) // Producing next one // 6 // (1 sec) // Producing next one // 8 //sampleEnd
Such an implementation is far from perfect. First, the receiver needs to know how many elements will be sent; however, this is rarely the case, so we would prefer to listen for as long as the sender is willing to send. To receive elements on the channel until it is closed, we could use a for-loop or
consumeEach function1.import kotlinx.coroutines.* import kotlinx.coroutines.channels.Channel //sampleStart suspend fun main(): Unit = coroutineScope { val channel = Channel<Int>() launch { repeat(5) { index -> println("Producing next one") delay(1000) channel.send(index * 2) } channel.close() } launch { for (element in channel) { println(element) } // or // channel.consumeEach { element -> // println(element) // } } } //sampleEnd
The common problem with this way of sending elements is that it is easy to forget to close the channel, especially in the case of exceptions. If one coroutine stops producing because of an exception, the other will wait for elements forever. It is much more convenient to use the
produce function, which is a coroutine builder that returns ReceiveChannel.// This function produces a channel with // next positive integers from 0 to max fun CoroutineScope.produceNumbers( max: Int ): ReceiveChannel<Int> = produce { var x = 0 while (x < 5) send(x++) }
The
produce function closes the channel whenever the builder coroutine ends in any way (finished, stopped, cancelled). Thanks to this, we will never forget to call close. The produce builder is a very popular way to create a channel, and for good reason: it offers a lot of safety and convenience.import kotlinx.coroutines.channels.produce import kotlinx.coroutines.* //sampleStart suspend fun main(): Unit = coroutineScope { val channel = produce { repeat(5) { index -> println("Producing next one") delay(1000) send(index * 2) } } for (element in channel) { println(element) } } //sampleEnd
Depending on the capacity size we set, we distinguish four types of channels:
- Unlimited - channel with capacity
Channel.UNLIMITEDthat has an unlimited capacity buffer, andsendnever suspends. - Buffered - channel with concrete capacity size or
Channel.BUFFERED(which is 64 by default and can be overridden by setting thekotlinx.coroutines.channels.defaultBuffersystem property in JVM). - Rendezvous2 (default) - channel with capacity
0orChannel.RENDEZVOUS(which is equal to0), meaning that an exchange can happen only if sender and receiver meet (so it is like a book exchange spot, instead of a bookshelf). - Conflated - channel with capacity
Channel.CONFLATEDwhich has a buffer of size 1, and each new element replaces the previous one.
Let's now see these capacities in action. We can set them directly on
Channel, but we can also set them when we call the produce function.We will make our producer fast and our receiver slow. With unlimited capacity, the channel should accept all the elements and then let them be received one after another.
import kotlinx.coroutines.channels.Channel import kotlinx.coroutines.channels.produce import kotlinx.coroutines.* //sampleStart suspend fun main(): Unit = coroutineScope { val channel = produce(capacity = Channel.UNLIMITED) { repeat(5) { index -> send(index * 2) delay(100) println("Sent") } } delay(1000) for (element in channel) { println(element) delay(1000) } } // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (1 - 4 * 0.1 = 0.6 sec) // 0 // (1 sec) // 2 // (1 sec) // 4 // (1 sec) // 6 // (1 sec) // 8 // (1 sec) //sampleEnd
With a capacity of concrete size, we will first produce until the buffer is full, after which the producer will need to start waiting for the receiver.
import kotlinx.coroutines.channels.produce import kotlinx.coroutines.* //sampleStart suspend fun main(): Unit = coroutineScope { val channel = produce(capacity = 3) { repeat(5) { index -> send(index * 2) delay(100) println("Sent") } } delay(1000) for (element in channel) { println(element) delay(1000) } } // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (1 - 2 * 0.1 = 0.8 sec) // 0 // Sent // (1 sec) // 2 // Sent // (1 sec) // 4 // (1 sec) // 6 // (1 sec) // 8 // (1 sec) //sampleEnd
With a channel of default (or
Channel.RENDEZVOUS) capacity, the producer will always wait for a receiver.import kotlinx.coroutines.channels.produce import kotlinx.coroutines.* //sampleStart suspend fun main(): Unit = coroutineScope { val channel = produce { // or produce(capacity = Channel.RENDEZVOUS) { repeat(5) { index -> send(index * 2) delay(100) println("Sent") } } delay(1000) for (element in channel) { println(element) delay(1000) } } // 0 // Sent // (1 sec) // 2 // Sent // (1 sec) // 4 // Sent // (1 sec) // 6 // Sent // (1 sec) // 8 // Sent // (1 sec) //sampleEnd
Finally, we will not be storing past elements when using the
Channel.CONFLATED capacity. New elements will replace the previous ones, so we will be able to receive only the last one, therefore we lose elements that were sent earlier.import kotlinx.coroutines.channels.Channel import kotlinx.coroutines.channels.produce import kotlinx.coroutines.* //sampleStart suspend fun main(): Unit = coroutineScope { val channel = produce(capacity = Channel.CONFLATED) { repeat(5) { index -> send(index * 2) delay(100) println("Sent") } } delay(1000) for (element in channel) { println(element) delay(1000) } } // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (1 - 4 * 0.1 = 0.6 sec) // 8 //sampleEnd
To customize channels further, we can control what happens when the buffer is full (
onBufferOverflow parameter). There are the following options:SUSPEND(default) - when the buffer is full, suspend on thesendmethod.DROP_OLDEST- when the buffer is full, drop the oldest element.DROP_LATEST- when the buffer is full, drop the latest element.
As you might guess, the channel capacity
Channel.CONFLATED is the same as setting the capacity to 1 and onBufferOverflow to DROP_OLDEST. Currently, the produce function does not allow us to set custom onBufferOverflow, so to set it we need to define a channel using the function Channel3.import kotlinx.coroutines.channels.* import kotlinx.coroutines.* //sampleStart suspend fun main(): Unit = coroutineScope { val channel = Channel<Int>( capacity = 2, onBufferOverflow = BufferOverflow.DROP_OLDEST ) launch { repeat(5) { index -> channel.send(index * 2) delay(100) println("Sent") } channel.close() } delay(1000) for (element in channel) { println(element) delay(1000) } } // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (0.1 sec) // Sent // (1 - 4 * 0.1 = 0.6 sec) // 6 // (1 sec) // 8 //sampleEnd
One more
Channel function parameter which we should know about is onUndeliveredElement. It is called when an element couldn't be handled for some reason. Most often this means that a channel was closed or cancelled, but it might also happen when send, receive, receiveOrNull, or hasNext throw an error. We generally use it to close resources that are sent by this channel.val channel = Channel<Resource>(capacity) { resource -> resource.close() } // or // val channel = Channel<Resource>( // capacity, // onUndeliveredElement = { resource -> // resource.close() // } // ) // Producer code val resourceToSend = openResource() channel.send(resourceToSend) // Consumer code val resourceReceived = channel.receive() try { // work with received resource } finally { resourceReceived.close() }
Multiple coroutines can receive from a single channel; however, to receive them properly we should use a for-loop (
consumeEach should not be used by multiple coroutines).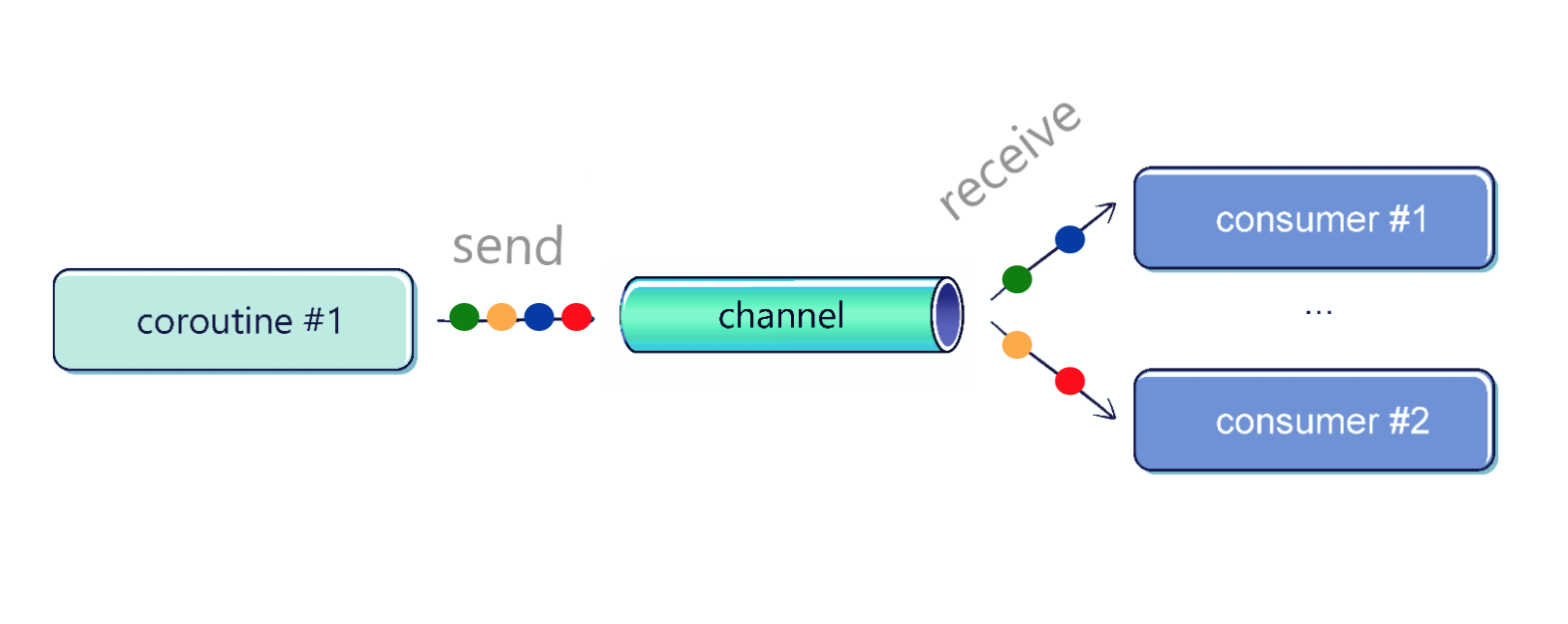
import kotlinx.coroutines.* import kotlinx.coroutines.channels.ReceiveChannel import kotlinx.coroutines.channels.produce //sampleStart fun CoroutineScope.produceNumbers() = produce { repeat(10) { delay(100) send(it) } } fun CoroutineScope.launchProcessor( id: Int, channel: ReceiveChannel<Int> ) = launch { for (msg in channel) { println("#$id received $msg") } } suspend fun main(): Unit = coroutineScope { val channel = produceNumbers() repeat(3) { id -> delay(10) launchProcessor(id, channel) } } // #0 received 0 // #1 received 1 // #2 received 2 // #0 received 3 // #1 received 4 // #2 received 5 // #0 received 6 // ... //sampleEnd
The elements are distributed fairly. The channel has a FIFO (first-in-first-out) queue of coroutines waiting for an element. This is why in the above example you can see that the elements are received by the next coroutines (0, 1, 2, 0, 1, 2, etc).
To better understand why, imagine kids in a kindergarten queuing for candies. Once they get some, they immediately eat them and go to the last position in the queue. Such distribution is fair (assuming the number of candies is a multiple of the number of kids, and assuming their parents are fine with their children eating candies).
Multiple coroutines can send to a single channel. In the below example, you can see two coroutines sending elements to the same channel.
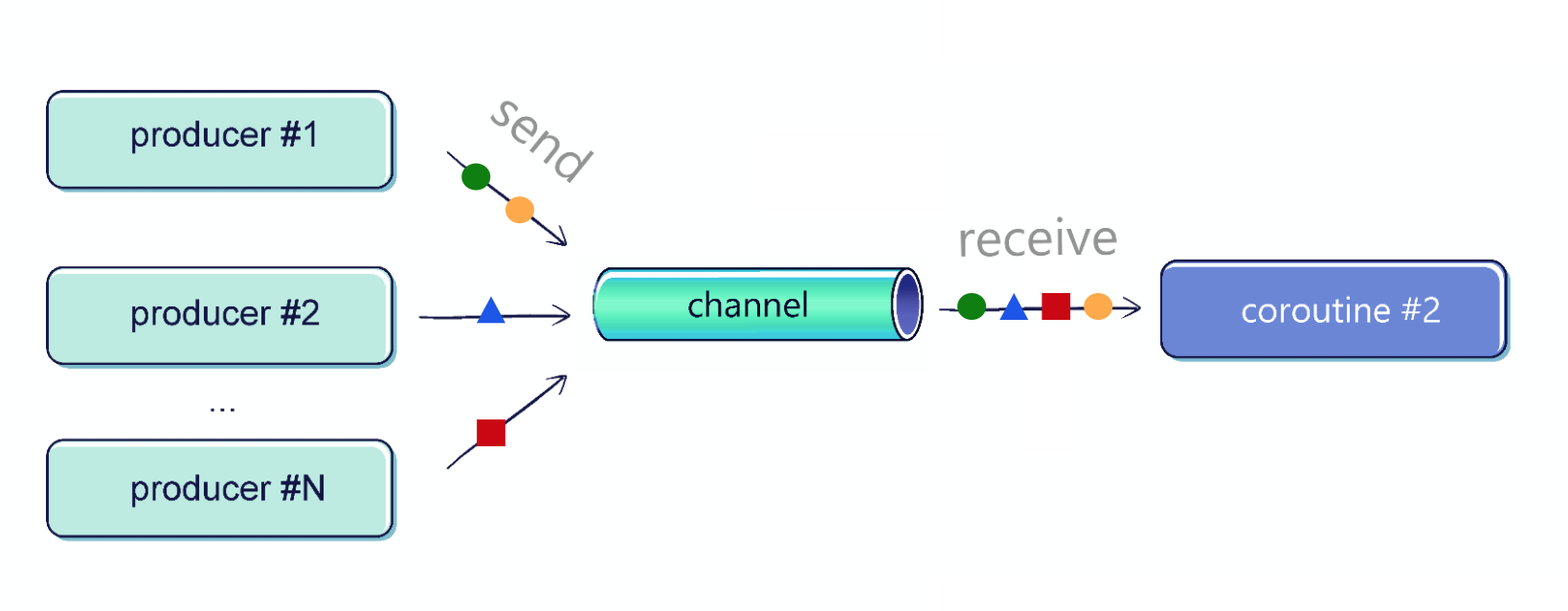
import kotlinx.coroutines.* import kotlinx.coroutines.channels.* //sampleStart suspend fun sendString( channel: SendChannel<String>, text: String, time: Long ) { while (true) { delay(time) channel.send(text) } } fun main(): Unit = runBlocking { val channel = Channel<String>() launch { sendString(channel, "foo", 200L) } launch { sendString(channel, "BAR!", 500L) } repeat(50) { println(channel.receive()) } coroutineContext.cancelChildren() } // (200 ms) // foo // (200 ms) // foo // (100 ms) // BAR! // (100 ms) // foo // (200 ms) // ... //sampleEnd
Sometimes, we need to merge multiple channels into one. For that, you might find the following function useful as it merges multiple channels using the
produce function:fun <T> CoroutineScope.fanIn( channels: List<ReceiveChannel<T>> ): ReceiveChannel<T> = produce { for (channel in channels) { launch { for (elem in channel) { send(elem) } } } }
Sometimes we set two channels such that one produces elements based on those received from another. In such cases, we call it a pipeline.
import kotlinx.coroutines.* import kotlinx.coroutines.channels.* //sampleStart // A channel of number from 1 to 3 fun CoroutineScope.numbers(): ReceiveChannel<Int> = produce { repeat(3) { num -> send(num + 1) } } fun CoroutineScope.square(numbers: ReceiveChannel<Int>) = produce { for (num in numbers) { send(num * num) } } suspend fun main(): Unit = coroutineScope { val numbers = numbers() val squared = square(numbers) for (num in squared) { println(num) } } // 1 // 4 // 9 //sampleEnd
Channels are useful when different coroutines need to communicate with each other. They guarantee no conflicts (i.e., no problem with the shared state) and fairness. A typical case in which we use channels is when values are produced on one side, and we want to process them on the other side. Channels are used to separate producers and consumers of data. For example, a sender might be a network listener, while a receiver might be a database writer, or a sender might be a UI event listener, while a receiver might be a UI updater. One example might be an application like SkyScanner, which searches for the cheapest flights by querying multiple airline websites. It could use a channel to receive flight offers from different airlines and then send them to the user as they arrive. However, in most of these cases it's better to use
channelFlow or callbackFlow, both of which are a hybrid of Channel and Flow (we will explain them in the Flow building chapter).
SkyScanner displays better and better flight search results as more and more airlines respond.
In their pure form, channels are often used as a queue of events that are processed one after another by one or more coroutines.
init { launch { for (event in eventChannel) { processEvent(event) } } } fun sendEvent(event: Event) { eventChannel.send(event) } fun processEvent(event: Event) { // process the event }
In some applications, whole pipelines are built using channels. For example, let's say that we are maintaining an online shop, like Amazon. Let's say that your service receives a big number of seller changes that might affect their offers. For each change, we need to first find a list of offers to update, and then we update them one after another.
Doing this the traditional way wouldn't be optimal. One seller might even have hundreds of thousands of offers. Doing it all in a single long process is not the best idea.
First, either an internal exception or a server restart might leave us not knowing where we stopped. Second, one big seller might block the server for a long time, thus leaving small sellers waiting for their changes to apply. Moreover, we should not send too many network requests at the same time so as to not overload the service that needs to handle them (and our network interface).
One solution to this problem is to set up a pipeline using channels. The first channel could contain the sellers to process, while the second one would contain the offers to be updated. These channels would have a buffer. The buffer in the second one could prevent our service from getting more offers when too many are already waiting. Thus, our server would be able to balance the number of offers we are updating at the same time.
We might also easily add functionalities to our pipeline, like:
- limiting queue sizes (to not let them grow too much);
- defining the number of coroutines that listen to on each channel (to decide how many concurrent requests to the external service we wish to make);
- removing duplicates from our queues (to not update the same offer twice, if seller changes are sent too quickly);
- adding persistence (to not lose the state of the pipeline when the server is restarted).
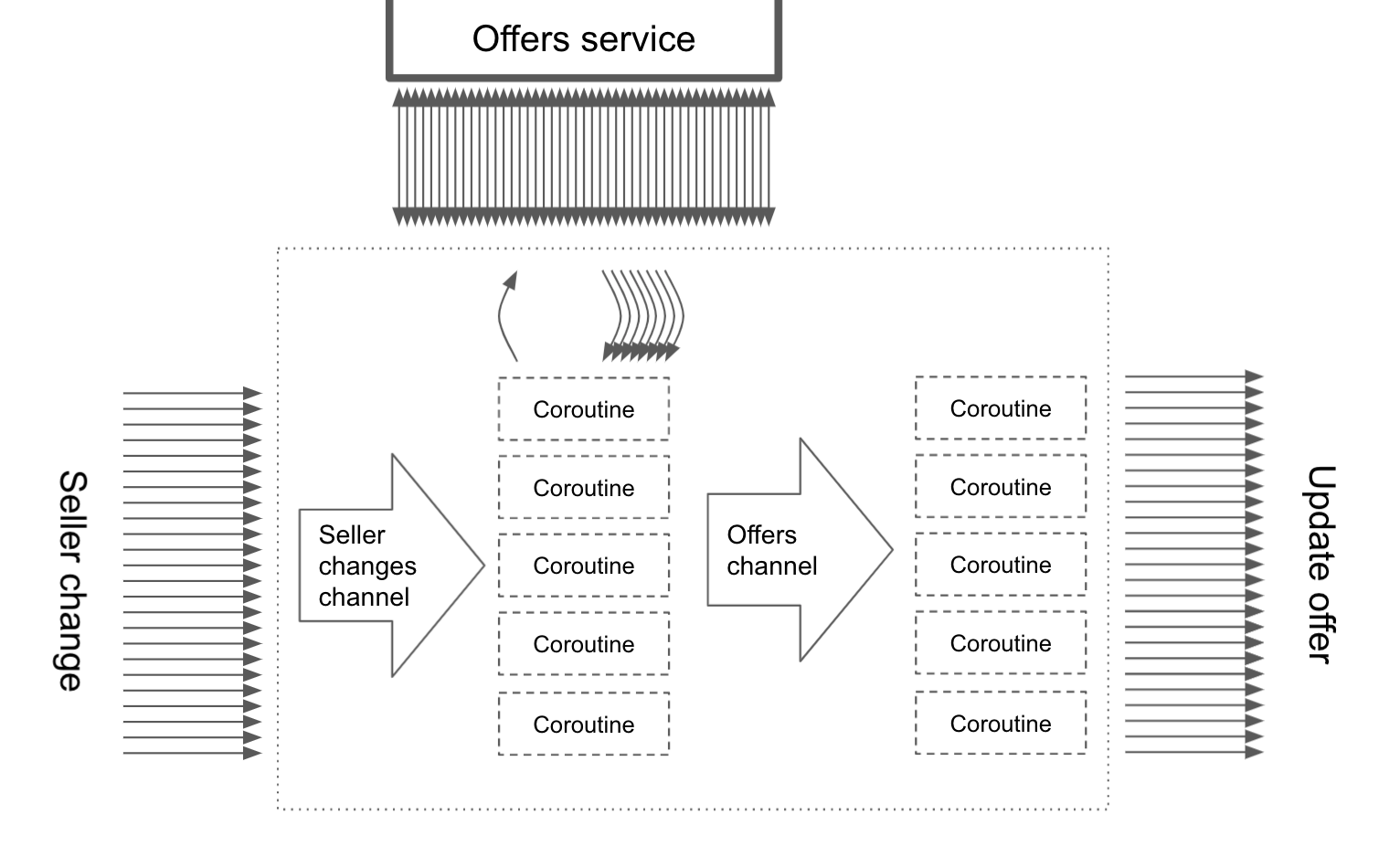
// A simplified implementation suspend fun handleOfferUpdates() = coroutineScope { val sellerChannel = listenOnSellerChanges() val offerToUpdateChannel = produce(capacity = UNLIMITED) { repeat(NUMBER_OF_CONCURRENT_OFFER_SERVICE_REQUESTS) { launch { for (seller in sellerChannel) { val offers = offerService .requestOffers(seller.id) offers.forEach { send(it) } } } } } repeat(NUMBER_OF_CONCURRENT_UPDATE_SENDERS) { launch { for (offer in offerToUpdateChannel) { sendOfferUpdate(offer) } } } }
Channel is a powerful inter-coroutine communication primitive. It supports any number of senders and receivers, and every value that is sent to a channel is received once. We often create a channel using the
produce builder, and observe a channel using for-loop. Channels can be used to set up a pipeline where we control the number of coroutines working on some tasks. Nowadays, we most often use channels in connection with Flow, which will be presented later in the book.-
The
consumeEachfunction uses a for-loop under the hood, but it also cancels the channel once it has consumed all its elements (so, once it is closed). ↩ - The origin is the French word "rendez-vous", which commonly means “appointment”. This beautiful word has crossed borders: in English, there is the less popular word "rendezvous"; in Polish, there is the word "randka", which means a date (a romantic appointment). ↩
-
Channelis an interface, soChannel()is a call of a function that is pretending to be a constructor. ↩



