


Dlaczego warto używać Kotlin Coroutines?
Po co tak właściwie uczyć się kotlin Coroutines, gdy od dawna istnieją biblioteki JVM o ugruntowanej już pozycji takie RxJava czy Reactor, które umożliwiają nam współbieżne wykonywanie operacji. Co więcej, sama Java wspiera wielowątkowość, a nawet mimo tego wciąż wielu ludzi i tak decyduje się używać zwykłe przestarzałe callbacki.
Kotlin Coroutines ma nam do zaoferowania wiele więcej niż pozostałe rozwiązania. Opierają się one na pojęciu stworzonym w 1963 roku1, lecz dopiero po wielu latach zostały one przystosowane do wykorzystania w komercyjnych projektach2. Kotlin coroutines łączy w sobie potężne rozwiązania zaprezentowane pół wieku temu, z biblioteką zaprojektowaną tak, aby perfekcyjnie pomagała nam w rzeczywistych przypadkach. Co więcej, Kotlin Coroutines wspiera wieloplatformowość, co oznacza, że mogą zostać wykorzystane na wszystkich platformach wspierających Kotlina (takich jak JVM, JS i iOS). Mają one niewielki wpływ na strukturę kodu oraz ich możliwości mogą zostać wykorzystane w po prostu sposób (czego nie można powiedzieć o RxJava lub callbackach). To właśnie sprawia, że są one przyjazne nawet dla początkujących3.
Zobaczmy ich działania w praktyce, sprawdzimy, jak w różnych scenariuszach sprawdzą się korutyny a jak inne, bardziej tradycyjne podejścia. Zaprezentuje dwa identyczne problemy przy implementacji logiki biznesowej w aplikacji na platformę Android.
Korutyny na Androidzie (i innych platformach)
Kiedy implementujesz logikę aplikacji, często musisz zdecydować się na:
- Pobranie danych z jednego lub wielu źródeł (API, view element, baza danych, preferences, tudzież inna aplikacja).
- Przetworzenie pobranych danych.
- Wykorzystania danych (wyświetlenie widoku, zapisanie w bazie danych lub wysłanie do API).
Przyjmijmy, że tworzymy aplikacje na Androida. Zacznijmy od sytuacji, w której potrzebujemy pobrać dane z API, przesortować oraz wyświetlić je na ekranie. Poniżej została przedstawiona funkcja, która miałaby takie zadanie realizować:
Niestety nie da się tego łatwo zrobić. Na Androidzie, każda aplikacja ma tylko jeden wątek mogący modyfikować widoki. Jest bardzo ważny wątek i pod żadnym pozorem nie może on zostać zablokowany, właśnie dlatego nie możemy w taki sposób zaimplementować tej funkcji. Gdybyśmy wykonali to na wątku głównym, funkcja getNewsFromApi zablokowałaby go, co doprowadziłoby do zawieszenia aplikacji. Natomiast gdybyśmy chcieli wykonać te operacje na innym wątku, również byłoby to niemożliwe, ponieważ funkcja showNews musi zostać wykonana na wątku głównym (Android nie pozwala na operacje UI w innych wątkach).
Przeskakiwanie po wątkach
Oczywiście, moglibyśmy rozwiązać ten problem, przenosząc operacje na wątek mogący zostać zablokowanym, a następnie wykonać showNews na wątku UI.
Powyższe rozwiązanie wciąż można znaleźć, w co niektórych aplikacjach, ale wykorzystanie tego niesie to ze sobą parę problemów:

- Nie mamy kontroli nad wykonywanymi operacjami, nie możemy ich też anulować. Może to powodować wycieki pamięci.
- Wątki są ciężkie, zbyt duża ilość w znaczącym stopniu obciąża aplikacje.
- Częsta zmiana wątków wprowadza zamieszanie i jest ciężka do zarządzania.
- Tworzy się przy tym dużo zbędnego i skomplikowanego kodu.
Aby lepiej zobrazować sobie te problemy, wyobraźmy sobie taką sytuację. Szybko otwierasz i zamykasz jakiś widok. Podczas otwarcia pracę zaczyna wykonywać kilka wątków, które będą się starać pobrać i przetworzyć dane. W sytuacji, gdy widok zostanie zamknięty, a wątek nie skończy swojej pracy, po zakończeniu jej może on próbować wykonać operacje na widoku, który już nie istnieje. Urządzenie nie potrzebnie wykonuje dodatkową pracę, ponadto może mogą zostać wyrzucone wyjątki oraz zdarzyć się może wiele innych nieprzewidywalnych sytuacji.
Biorąc pod uwagę wszystkie te problemy, poszukajmy lepszego rozwiązania.
Callbacki
Callback to kolejny wzorzec, który również może zostać wykorzystany do rozwiązania tego problemu. W tym przypadku tworzymy nasze funkcje tak, aby nie blokowały głównego wątku i przekazujemy do nich inną funkcję, która powinna zostać wykonana po zakończeniu procesu.
Niestety również i tutaj często nie mamy możliwości anulowania rozpoczętych już operacji. Moglibyśmy zmodyfikować te funkcje tak, aby to umożliwiały, ale nie należy to do rzeczy szybkich i prostych. Każda taka funkcja wymagałaby indywidualnej implementacji procesu anulowania.
Śmiało można powiedzieć, że funkcje z callbackami mogą nam pomóc przy rozwiązywaniu prostych problemów, ale niestety mają one też masę wad. Aby lepiej zrozumieć słabe strony takiego rozwiązania, przeanalizujemy bardziej skomplikowany przypadek, w którym musimy pobrać dane z trzech endpointów.
Powyższemu fragmentowi kodu daleko do perfekcji, zobaczmy dlaczego:
- Pobieranie newsów oraz danyh użytkownika mogłoby się odbywać równolegle, ale funkcje callbackowe nie dają takiej możliwości.
- Dodanie wsparcia dla anulowania tych procesów byłoby bardzo skomplikowane.
- Wielokrotne korzystanie z callbacków może doprowadzić do tak zwanego callbackowego piekła, czyli dużej ilości wcięć w kodzie sprawiających, że kod staje się nieczytelny. Takie zjawisko często występowało w starszych projektach z wykorzystaniem Node.JS:

- Korzystanie z funkcji z callbackami utrudnia kontrolę nad tym, co się dzieje po wykonaniu zaczętych przez nie procesów. Dla zaimplementowanej wcześniej funkcji poniższy kod nie zadziała poprawnie, gdyż ukryje on znacznik ładowania natychmiast po jego wyświetleniu.
Aby temu zaradzić, musielibyśmy z showNews zrobić funkcję callbackową, po czym umieścić ukrycie znacznika ładowania w jej callbacku.

To też dlatego callbackom w przypadku bardziej skomplikowanych przypadków, daleko do perfekcji. Sprawdźmy więc jeszcze inny typ podejścia do rozwiązywania takich problemów, jakim jest RxJava i inne strumienie reaktywne.
RxJava i strumienie reaktywne
Alternatywnym podejściem, popularnym w Javie (w Androidzie, jak i backendzie) jest wykorzystywanie reactive streams (albo Reactive Extensions), takich jak RxJava czy też Project Reactor. Podczas wykorzystania tego podejścia, wszystkie strumienie danych, mogą być rozpoczęte, przetworzone oraz obserwowane. Strumienie te wspierają, przeskakiwanie pomiędzy wątkami (thread-switching) oraz współbieżne przetwarzanie, dlatego też często wykorzystuje się je do równoległego przetwarzania danych.
Tak możemy rozwiązać nasz problem z wykorzystaniem RxJava:
The
disposablesin the above example are needed to cancel this stream if (for example) the user exits the screen.
To rozwiązanie bez wątpienia można uznać za lepsze od callbacków, bo nie grożą nam wycieki pamięci, nie ma problemów z anulowaniem wykonywania operacji oraz w prawidłowy sposób wykorzystujemy wątki. Jednym problemem jest to, że takie rozwiązanie jest naprawdę skomplikowane. Jeżeli porównamy kod z początku artykułu z kodem wykorzystującym RxJava można zauważyć, że niewiele mają ze sobą wspólnego.
Wszystkich funkcji, takich jak subscribeOn, observeOn, map, lub subscribe musimy się nauczyć. Cancelling needs to be explicit. Funkcje muszą zwrócić obiekty opakowane wewnątrz klas Observable lub Single. W praktyce oznacza to, że z wprowadzeniem RxJavy kod będzie wymagał sporych zmian.
Wracając do drugiego problemu, w którym przed wyświetleniem danych chcieliśmy pobrać je z trzech endpointów, to i również do tego możemy wykorzystać RxJavę, ale będzie to skomplikowane.
Powyższy kod jest współbieżny, nie prowadzi on również do wycieków pamięci, ale za to wymagał wykorzystania funkcji RxJava takich jak zip oraz flatMap, pack a value into Pair, and destructure it. Taki rodzaj implementacji jest prawidłowy, ale skomplikowany. Sprawdźmy więc, co w tej kwestii oferują nam korutyny.
Wykorzystanie Kotlin Coroutines
Podstawową funkcjonalność, jaką wprowadzają korutyny w kotlinie, jest możliwość zawieszenia i wznawiania wykonywania operacji zawartych w korutynach. Dzięki temu w głównym wątku możemy wykonać jakiś kod na przykład pobierający dane z API, który zawiesi korutyne. Zawieszona korutyna nie blokuje wątku, będzie on miał możliwość wykonywania innych operacji (np. innych korutyn), dlatego możemy ich używać do zmian widoków. Gdy pobieranie danych zostanie zakończone, korutyna czeka na główny wątek (jest to rzadka sytuacja, ale można się zdarzyć, gdy inne korutyny znajdują się w analogicznej sytuacji lub wątek jest po prostu zajęty wykonywaniem jakiś innych operacji), gdy uzyska do niego dostęp, wraca do kontynuowania pracy od miejsca, przy którym została zastrzymana.
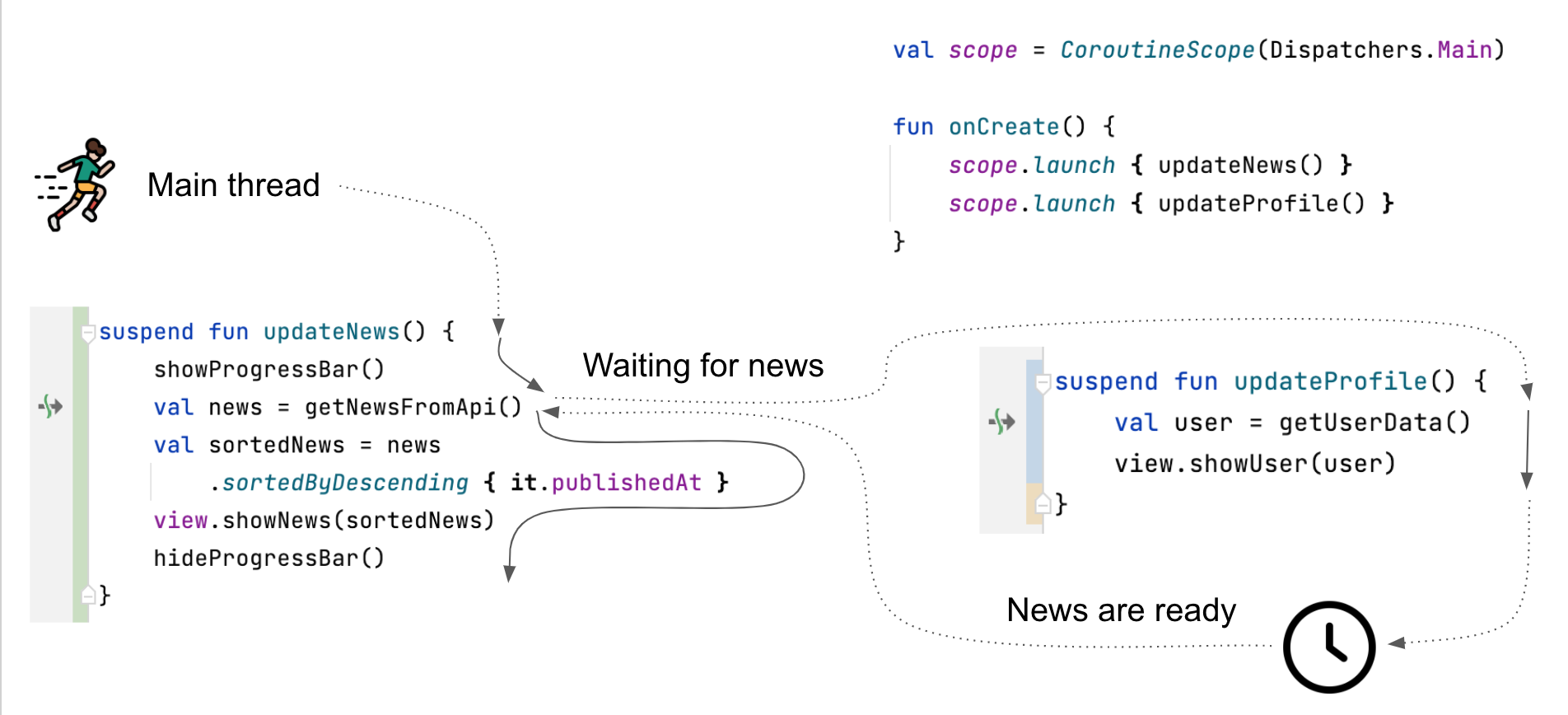
updateNews oraz updateProfile wykonujące się na głównym wątku lecz w oddzielnym korutynach. Operacje te mogą zostać wykonane współbieżnie ponieważ zawieszą one jedynie korutyne bez blokowania wątku. Wykonywanie updateNews zatrzyma się na funkcji getNesFromApi, aż do momentu otrzymania odpowiedzi od serwera, podczas tego czasu zawieszenia główny wątek zajmie się wykonywaniem funkcji updateProfile. W powyższym przykładzie założone zostało, że getUserData pobiera dane z pamięci podręcznej więc nie spowoduje to zawieszenia. Wykonanie takich operacji z pewnością nie zajmie tyle czasu co zwrócenie danych przez serwer, więc główny wątek do czasu otrzymania odpowiedzi pozostaje nieużywany lub będzie wykorzystywany przez inne funkcje. Po otrzymaniu danych, zawieszona korutyna wznawia swoją pracę na głównym wątku zaraz po wywołaniu getNewsFromApi, czyli za miejscem gdzie skończyła.
Z definicji korutyny to komponenty, które mogą być wstrzymywane i wznawiane. Pojęcia takie jak asynyc/await oraz generatory, wykorzystywane w JavaScrpit, Rust oraz Python również korzystają z korutyn, ale ich możliwości są ograniczone.
Tak więc, nasz pierwszy problem możemy rozwiązać z korutynami w następujący sposób:
W powyższym kodzie wykorzystany został
viewModelScope, który jest aktualnie dość często wykorzystywany przy tworzeniu aplikacji na platformę Android. Oczywiście istnieje możliwość wybrania innego obiekty reprezentującego zasięg, co zostanie omówione później.
Ten kod jest bardzo podobny do kodu z początku artykułu, jednakże w tym rozwiązaniu, dzięki mechanizmowi zawieszenia korutyn, kod nie zablokuje głównego wątku, gdy będziemy chcieli pobrać jakieś dane lub wykonać jakaś wymagająca operację. Podczas gdy korutyna jest wstrzymana, główny wątek, zamiast na nią czekać może zająć się tym w czasie dowolnymi rzeczami, na przykład odtwarzaniem animacji ładowania. Jak tylko korutyna otrzyma odpowiedź, wraca do pracy na głównym wątku od momentu, na którym skończyła.
A co z drugim problemem, w którym chcieliśmy pobrać dane aż z trzech enpointów? Możemy to zrobić w ten sam sposób:
Jako tako działać to będzie, ale nie jest nie to optymalne rozwiązanie. Wywołania API wykonają się sekwencyjnie (jedna po drugiej), jeżeli każde z nich będzie potrzebowało sekundy na zwrócenie odpowiedzi, to cała operacja zajmie nam sekund trzy, zamiast dwóch, w porównaniu do sytuacji, w której zostałoby to wykonane współbieżnie. Tutaj na pomoc, przychodzą nam funkcje z Kotlin Coroutines Library takie jak async, których można użyć do natychmiastowego uruchomienia innej korutyny z pewnym żądaniem. Przy pomocy funkcji await możemy również poczekać na wynik, który zostanie zwrócony po zakończeniu korutyny.
Ten kod wciąż jest prosty i czytelny. Wykorzystuje wzorzec async/await popularny w JavaScript czy C# ale oprócz tego jest wydajny§ oraz nie grozi wyciekami pamięci.
Dzięki korutynom możemy w łatwy sposób wdrożyć wiele różnych funkcjonalności, i jednocześnie wykorzystywać mocne strony kotlina. Dla przykładu nie blokują one nam korzystania pętli for lub funkcji do przetwarzania kolekcji. Poniżej zostało przedstawione, jak kolejne strony mogą zostać pobrane sekwencyjnie lub równolegle.
Korutyny w backendzie
Jedną z najistotniejszych zalet korutyn na backendzie jest prostota ich wykorzystywania. W przeciwieństwe do RxJava praktycznie nie wpływają na strukturę kodu. W większości przypadków migracja z wątków na korutyny wymaga jedynie dodanie modyfikatora suspend. Kiedy to zrobimy, możemy łatwy sposób wprowadzić współbieżność wykonywania operacji, problemem nie będzie również testowanie ich zachowania czy też anulowanie. Będziemy mogli również skorzystać ze wszystkich innych zaawansowanych funkcji bibliotek Kotlina, które omówimy w tej książce.
Oprócz tych wszystkich nowych funkcjonalności istnieje jeszcze jeden istotny powód, aby skorzystać z kotlinowych korutyn. Wątki w przeciwieństwie do korutyn są kosztowne, trzeba je stworzyć, utrzymać i przydzielić im pamięć4. Jeżeli twoja aplikacja byłaby wykorzystywana przez miliony użytkowników oraz wstrzymywałaby swoją pracę na czas otrzymania odpowiedzi od bazy danych, czy jakiegokolwiek innego rodzaju usługi, prowadziłoby to do znacznego wzrostu kosztów zużycia pamięci i procesora (z powodu ciągłej potrzeby tworzenia i synchronizacji tych wątków).
Ten problem można zwizualizować za pomocą poniższych fragmentów kodu, które symulują 100 000 użytkowników pobierających jakieś dane. Pierwszy przykład uruchamia 100 000 wątków i usypia je na sekundę (w celu symulacji oczekiwania na odpowiedź z bazy danych lub innej usługi). Jeśli uruchomisz go na swoim komputerze, zobaczysz, że wydrukowanie wszystkich tych kropek zajmie trochę czasu lub zostanie przerwane z wyjątkiem OutOfMemoryError. To właśnie jest koszt uruchomienia i zarządzania tyloma wątkami . Drugi fragment wykorzystuje coroutines zamiast wątków oraz zwiesza się, zamiast usypiać. Jeśli go uruchomisz, program odczeka sekundę, a następnie wydrukuje wszystkie kropki. Koszt uruchomienia tych wszystkich programów jest tak mały, że jest ledwo zauważalny.
Podsumowanie
Mam nadzieję, że przekonałem cię do tego, iż warto poszerzyć swoją wiedzę o to rozwiązanie. Korutyny to coś więcej niż tylko biblioteka, która sprawia, że programowanie współbieżne jest tak łatwe jak to tylko możliwe. Jeśli więc czujesz się przekonany, to od razu zacznijmy się uczyć. Przez resztę tego rozdziału przyjrzymy się, jak działa zawieszenie (suspend): najpierw z punktu widzenia użytkownika, a następnie co dzieje się pod maską.
Conway, Melvin E. (July 1963). "Design of a Separable Transition-diagram Compiler". Communications of the ACM. ACM. 6 (7): 396–408. doi:10.1145/366663.366704. ISSN 0001-0782. S2CID 10559786
Wydaje mi się, że pierwsze uniwersalne i gotowe do wykorzystania w przemyśle korutyny zostały wprowadzone przez Go w 2009. Warto jednak wspomnieć, że korutyny zostały zaimplementowane również w niektórych innych starszych językach, takich jak Lisp, ale nie stały się tak popularne. Uważam, że stało się tak, ponieważ ich implementacja nie została zaprojektowana do obsługi rzeczywistych/codziennych/z życia wziętych przypadków/problemów. Lisp (podobnie jak Haskell) był traktowany głównie jako plac zabaw dla naukowców, a nie jako język dla profesjonalistów.
Nie zmienia to faktu, że aby poprawnie korzystać z korutyn, powinniśmy je dobrze zrozumieć.
Najczęstszym rozmiarem stosu wątków jest 1 MB. Ze względu na optymalizację Javy niekoniecznie oznacza to, że zużyjemy 1 MB x ilość wątków pamięci, wciąż jednak tworzenie wątków jest bardzo kosztowne.

, [Kotlin Coroutines](https://kt.academy/book/coroutines), [Python od podstaw](https://kt.academy/pl/book/py) oraz [JavaScript od podstaw](https://kt.academy/pl/book/js), założyciel Kt. Academy. Programuje od dziecka, występuje na międzynarodowych konferencjach programistycznych, posiada w dorobku liczne publikacje m.in. w magazynie Programista. Pasjonat czytania i pisania książek, uczenia się i filozofii.](https://lh3.googleusercontent.com/a-/AOh14GgT-nGHTlbxHpiPyUUhgruiheIEyBVEsCDWNdW0xA=s400-c)