


Verteiler in Kotlin-Coroutinen
Dies ist ein übersetztes Kapitel aus dem Buc Kotlin Coroutines. Wenn Sie mir helfen möchten, die Übersetzung zu verbessern, finden Sie die Quellen auf GitHub.
Eine wesentliche Funktion, die die Kotlin Coroutines-Bibliothek anbietet, ist die Entscheidung, auf welchem Thread (oder Thread-Pool) eine Coroutine laufen soll (starten und fortsetzen). Diese Entscheidung wird mithilfe von Verteilern getroffen.
Im englischen Wörterbuch wird ein Verteiler als "eine Person, die dafür verantwortlich ist, Menschen oder Fahrzeuge dorthin zu schicken, wo sie benötigt werden, vor allem Notfallfahrzeuge" definiert. Bei Kotlin Coroutines bestimmt der CoroutineContext, auf welchem Thread eine bestimmte Coroutine laufen wird.
Verteiler in Kotlin Coroutines sind einem ähnlichen Konzept wie RxJava Schedulers.
Standardverteiler
Wenn Sie keinen Verteiler festlegen, wird standardmäßig Dispatchers.Default ausgewählt. Dieser ist für CPU-intensive Operationen vorgesehen. Er verfügt über einen Pool von Threads, dessen Größe der Anzahl der Kerne in der Maschine entspricht, auf der Ihr Code ausgeführt wird (aber nicht weniger als zwei). Zumindest theoretisch ist dies die optimale Anzahl von Threads, vorausgesetzt, Sie nutzen diese Threads effizient, das heißt, Sie führen CPU-intensive Berechnungen durch und verhindern Blockierungen.
Um diesen Verteiler in Aktion zu sehen, führen Sie den folgenden Code aus:
Beispiel Ergebnis auf meiner Maschine (Ich habe 12 Kerne, daher gibt es 12 Threads im Pool):
Running on thread: DefaultDispatcher-worker-1
Running on thread: DefaultDispatcher-worker-5
Running on thread: DefaultDispatcher-worker-7
Running on thread: DefaultDispatcher-worker-6
Running on thread: DefaultDispatcher-worker-11
Running on thread: DefaultDispatcher-worker-2
Running on thread: DefaultDispatcher-worker-10
Running on thread: DefaultDispatcher-worker-4
...Warnung:
runBlockingsetzt einen eigenen Dispatcher, wenn kein anderer gesetzt ist; daher wird innerhalb davon nicht automatisch derDispatcher.Defaultausgewählt. So, wenn wirrunBlockinganstelle voncoroutineScopeim obigen Beispiel verwendet hätten, würden alle Coroutinen auf "main" laufen.
Begrenzung des Standard-Dispatchers
Angenommen, Sie haben einen aufwändigen Prozess und befürchten, dass dieser alle Dispatchers.Default Threads nutzen und andere Coroutinen, die denselben Dispatcher verwenden, blockieren könnte. In solchen Fällen können wir limitedParallelism auf Dispatchers.Default anwenden, um einen Dispatcher zu erstellen, der auf denselben Threads läuft, jedoch auf eine bestimmte Anzahl gleichzeitig laufender Threads begrenzt ist.
Dieser Mechanismus wird verwendet, nicht um Dispatchers.Default zu begrenzen, aber es lohnt sich, sich daran zu erinnern, weil wir bald limitedParallelism für Dispatchers.IO präsentieren werden, was wesentlich bedeutender und gebräuchlicher ist.
limitedParallelismwurde in der Version1.6von kotlinx-coroutines eingeführt.
Hauptdispatcher
Android und viele andere Anwendungsframeworks verfügen über ein Konzept eines Haupt- oder UI-Threads, der in der Regel der wichtigste Thread ist. Auf Android ist er der einzige, der zur Interaktion mit der Benutzeroberfläche verwendet werden kann. Daher muss er sehr oft, aber auch mit großer Sorgfalt, verwendet werden. Wenn der Hauptthread blockiert wird, friert die gesamte Anwendung ein. Um eine Coroutine auf dem Hauptthread auszuführen, nutzen wir Dispatchers.Main.
Dispatchers.Main ist auf Android verfügbar, wenn Sie das kotlinx-coroutines-android Artefakt verwenden. Es ist ebenso auf JavaFX verfügbar, wenn Sie kotlinx-coroutines-javafx verwenden, und auf Swing, wenn Sie kotlinx-coroutines-swing verwenden. Sollten Sie keine Abhängigkeit besitzen, die den Hauptdispatcher definiert, ist dieser nicht verfügbar und kann nicht genutzt werden.

Beachten Sie, dass Frontend-Bibliotheken typischerweise nicht in Unit-Tests genutzt werden, daher wird Dispatchers.Main dort normalerweise nicht benutzt. Um es nutzen zu können, müssen Sie einen Dispatcher mittels Dispatchers.setMain(dispatcher) aus kotlinx-coroutines-test zuweisen.
Auf Android verwenden wir typischerweise den Main Dispatcher als den Standard. Wenn Sie Bibliotheken verwenden, die suspendiert werden anstatt blockiert, und Sie keine komplexen Berechnungen durchführen, können Sie in der Praxis oft nur Dispatchers.Main verwenden. Wenn Sie CPU-intensive Operationen durchführen, sollten Sie diese auf Dispatchers.Default ausführen. Diese beiden reichen für viele Anwendungen aus, aber was ist, wenn Sie den Thread blockieren müssen? Beispielsweise, wenn Sie langwierige I/O-Operationen durchführen müssen (z.B. große Dateien lesen) oder wenn Sie eine Bibliothek mit blockierenden Funktionen verwenden müssen. Sie können den Main Thread nicht blockieren, weil Ihre Anwendung sich aufhängen würde. Wenn Sie den Standard-Dispatcher blockieren, riskieren Sie, alle Threads im Thread-Pool zu blockieren, in diesem Fall könnten Sie keine Berechnungen mehr durchführen. Daher benötigen wir einen Dispatcher für solche Situationen, und das ist Dispatchers.IO.
IO Dispatcher
Dispatchers.IO ist dafür konzipiert, verwendet zu werden, wenn wir Threads durch I/O-Operationen blockieren, zum Beispiel, wenn wir Dateien lesen/schreiben, Android geteilte Einstellungen verwenden oder blockierende Funktionen aufrufen. Der untenstehende Code dauert etwa 1 Sekunde, weil Dispatchers.IO mehr als 50 aktive Threads gleichzeitig zulässt.
Wie funktioniert es? Stellen Sie sich einen unendlichen Thread-Pool vor. Zunächst ist dieser leer, aber wenn wir mehr Threads benötigen, werden diese erstellt und bleiben aktiv, bis sie eine Weile nicht genutzt wurden. Solch ein Pool existiert zwar, aber es wäre gefährlich, ihn direkt zu verwenden. Bei zu vielen aktiven Threads geht die Leistung auf eine langsame, aber unbeschränkte Weise zurück und führt letztendlich zu Speicherüberlauf-Fehlern. Aus diesem Grund erstellen wir Dispatcher, die eine begrenzte Anzahl von Threads gleichzeitig verwenden können. Dispatchers.Default ist begrenzt durch die Anzahl der Kerne Ihres Prozessors. Das Limit von Dispatchers.IO liegt bei 64 (oder der Anzahl der Kerne, wenn es mehr davon gibt).
Wie wir erwähnten, teilen sowohl Dispatchers.Default als auch Dispatchers.IO den gleichen Pool von Threads. Dies ist eine wichtige Optimierung. Threads werden wiederverwendet, und oft ist kein erneutes Dispatching notwendig. Zum Beispiel, sagen wir, Sie laufen auf Dispatchers.Default und dann erreicht die Ausführung withContext(Dispatchers.IO) { ... }. Meistens bleiben Sie im gleichen Thread4, aber was sich ändert, ist, dass dieser Thread nicht zum Limit von Dispatchers.Default gehört, sondern zum Limit von Dispatchers.IO. Die Limits dieser Dispatchers sind unabhängig, so dass sie sich nie gegenseitig verhungern lassen werden.

Um dies klarer zu sehen, stellen Sie sich vor, dass Sie sowohl Dispatchers.Default als auch Dispatchers.IO bis an ihre Grenzen auslasten. Als Ergebnis wird die Anzahl Ihrer aktiven Threads die Summe ihrer maximalen Kapazitäten sein. Wenn Sie 64 Threads in Dispatchers.IO zulassen und Sie haben 8 Kerne, dann werden Sie 72 aktive Threads im gemeinsamen Pool haben. Das bedeutet, dass wir eine effiziente Wiederverwendung von Threads haben und beide Dispatcher sind stark unabhängig.
Der typischste Fall, in dem wir Dispatchers.IO verwenden, ist, wenn wir Funktionen aufrufen müssen, die Bibliotheken blockieren. Die beste Praxis besteht darin, sie mit withContext(Dispatchers.IO) zu umgeben, um sie zu Unterbrechungsfunktionen zu machen. Solche Funktionen können ohne besondere Berücksichtigung verwendet werden: sie können wie alle anderen ordnungsgemäß implementierten Unterbrechungsfunktionen behandelt werden.
Das einzige Problem entsteht, wenn solche Funktionen eine zu große Anzahl an Threads blockieren. Dispatchers.IO ist auf 64 begrenzt. Ein Dienst, der massiv Threads blockiert, könnte dazu führen, dass alle anderen warten müssen. Um uns dabei zu helfen, setzen wir wieder limitedParallelism ein.
IO-Dispatcher mit einem benutzerdefinierten Pool von Threads
Dispatchers.IO hat ein spezielles Verhalten, das für die Funktion limitedParallelism definiert ist. Es erstellt einen neuen Dispatcher mit einem unabhängigen Pool von Threads. Darüber hinaus ist dieser Pool nicht auf 64 begrenzt, denn wir können entscheiden, wie viele Threads wir nutzen möchten.
Stellen Sie sich zum Beispiel vor, Sie starten 100 Coroutinen, von denen jede einen Thread für eine Sekunde blockiert. Wenn Sie diese Coroutinen auf Dispatchers.IO ausführen, dauert es 2 Sekunden. Wenn Sie sie auf Dispatchers.IO mit limitedParallelism ausführen, das auf 100 Threads eingestellt ist, dauert es 1 Sekunde. Die Laufzeiten beider Dispatcher können verglichen werden, da sie unabhängig voneinander arbeiten.
Konzeptionell könnten Sie es sich folgendermaßen vorstellen:
// Dispatcher with an unlimited pool of threads
private val pool = ...
Dispatchers.IO = pool.limitedParallelism(64)
Dispatchers.IO.limitedParallelism(x) =
pool.limitedParallelism(x)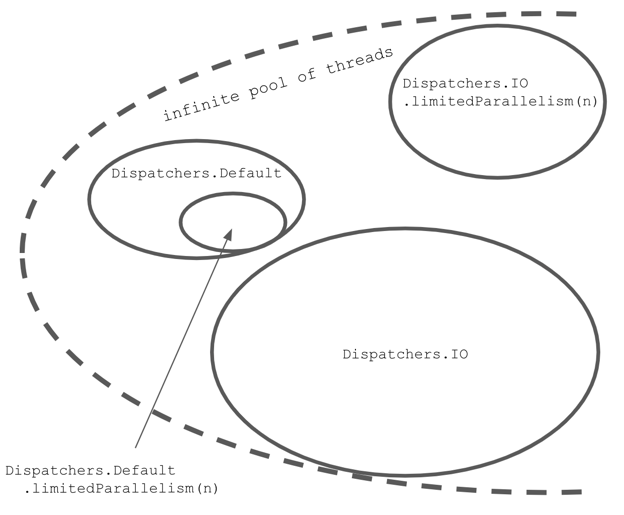
Die beste Praxis für Klassen, die Threads intensiv blockieren könnten, besteht darin, ihre eigenen Dispatcher zu definieren, die ihre eigenen unabhängigen Limits haben. Wie groß sollte dieses Limit sein? Das müssen Sie selbst entscheiden. Zu viele Threads sind eine ineffiziente Nutzung unserer Ressourcen. Andererseits ist das Warten auf einen verfügbaren Thread nicht gut für die Leistung. Das Wichtigste ist, dass dieses Limit unabhängig von Dispatcher.IO und den Limits anderer Dispatcher ist. Dank dessen wird ein Service einen anderen nicht blockieren.
Dispatcher mit einem festen Thread-Pool
Einige Entwickler möchten mehr Kontrolle über die Thread-Pools haben, die sie verwenden, und Java bietet eine leistungsstarke API dafür. Beispielsweise können wir mit der Executors Klasse einen festen bzw. gecachte Thread-Pool erstellen. Diese Pools implementieren die ExecutorService bzw. Executor Schnittstellen, die wir mit der Funktion asCoroutineDispatcher in einen Dispatcher umwandeln können.
limitedParallelismwurde in der Version 1.6 vonkotlinx-coroutineseingeführt; in früheren Versionen haben wir oft Dispatcher mit unabhängigen Thread-Pools erstellt, die dieExecutors-Klasse verwenden.
Das größte Problem mit diesem Ansatz ist, dass ein mit ExecutorService.asCoroutineDispatcher() erstellter Dispatcher mit der close-Funktion geschlossen werden muss. Entwickler vergessen dies oft, was zu Thread-Lecks führt. Ein weiteres Problem ist, dass Sie, wenn Sie einen festen Thread-Pool erstellen, diese nicht effizient nutzen. Sie halten ungenutzte Threads am Leben, ohne sie mit anderen Diensten zu teilen.
Dispatcher auf einen einzelnen Thread begrenzt
Für alle Dispatcher, die mehrere Threads verwenden, müssen wir das Problem des gemeinsam geteilten Zustands berücksichtigen. Beachten Sie, dass im Beispiel unten 10.000 Coroutinen i um 1 erhöht. Daher sollte sein Wert 10.000 sein, aber er ist eine kleinere Zahl. Dies ist das Ergebnis einer gleichzeitigen Modifikation des gemeinsam geteilten Zustands (Eigenschaft i) auf mehreren Threads.
Es gibt viele Wege, dieses Problem zu lösen (die meisten sind im Kapitel 'Das Problem mit dem Zustand' beschrieben), aber eine Möglichkeit wäre, einen Dispatcher mit nur einem einzigen Thread zu verwenden. Wenn wir nur einen einzigen Thread zur Zeit verwenden, benötigen wir keine andere Synchronisation. Klassischerweise wurde dies durch die Erstellung eines solchen Dispatchers mit Executors gemacht.

Das Problem ist, dass dieser Dispatcher einen zusätzlichen Thread aktiv hält, und er muss geschlossen werden, wenn er nicht mehr verwendet wird. Eine moderne Lösung besteht darin, Dispatchers.Default oder Dispatchers.IO (wenn wir Threads blockieren) mit einer auf 1 begrenzten Parallelität zu verwenden.
Der größte Nachteil besteht darin, dass unsere Aufrufe sequenziell abgewickelt werden, wenn wir den einzigen Thread blockieren.
Nutzung von virtuellen Threads aus Project Loom
Die JVM-Plattform hat eine neue Technologie eingeführt, genannt Project Loom. Die größte Innovation ist die Einführung von virtuellen Threads, die wesentlich leichter sind als normale Threads. Es ist kostengünstiger, virtuelle Threads zu blockieren, als normale Threads zu blockieren.
Warnung! Project Loom ist noch jung und ich empfehle nicht, es in Unternehmensanwendungen zu verwenden, bis es stabil wird.
Für uns Entwickler, die die Kotlin Coroutinen kennen, bietet Project Loom nicht viel Neues. Die Kotlin Coroutinen haben viele weitere erstaunliche Funktionen, wie mühelose Stornierung oder virtuelle Zeit zum Testen5. Project Loom kann besonders nützlich sein, wenn wir seine virtuellen Threads anstelle von Dispatcher.IO verwenden müssen, um das Blockieren von Threads zu vermeiden6.
Um Project Loom zu verwenden, müssen wir eine JVM-Version über 19 verwenden und momentan müssen wir die Vorschaufunktionen mit dem Flag --enable-preview aktivieren. Danach können wir einen Executor mit newVirtualThreadPerTaskExecutor aus Executors erstellen und ihn in einen Coroutine-Dispatcher umwandeln.
Alternativ könnte man ein Objekt erstellen, das ExecutorCoroutineDispatcher implementiert.
Um diesen Dispatcher ähnlich wie andere zu verwenden, können wir eine Erweiterungseigenschaft am Dispatchers Objekt definieren. Dies sollte auch seine Entdeckbarkeit unterstützen.
Jetzt brauchen wir nur zu testen, ob unser neuer Dispatcher wirklich eine Verbesserung ist. Wir erwarten, dass er bei blockierenden Threads weniger Speicher und Prozessorleistung benötigt als andere Dispatcher. Wir könnten die Umgebung für präzise Messungen einrichten, oder wir könnten ein Beispiel so extrem gestalten, dass jeder den Unterschied sehen kann. Für dieses Buch habe ich mich für den zweiten Ansatz entschieden. Ich habe 100.000 Coroutinen gestartet, die jeweils für 1 Sekunde blockiert waren. Du kannst sie etwas anderes tun lassen, wie etwa etwas ausdrucken oder einen Wert erhöhen, es sollte das Ergebnis nicht stark verändern. Es hat etwas mehr als zwei Sekunden gedauert, alle diese Coroutinen auf Dispatchers.Loom auszuführen.
Vergleichen wir es mal mit einer Alternative. Es wäre nicht gerecht, nur Dispatchers.IO zu verwenden, da es auf 64 Threads begrenzt ist und eine solche Funktion mehr als 26 Minuten in Anspruch nehmen würde. Wir müssen das Thread-Limit auf die Anzahl der Coroutinen erhöhen. Als ich das tat, dauerte die Ausführung des Codes nur noch über 23 Sekunden, also zehnmal weniger.
Im Moment ist Project Loom noch jung, und es ist eigentlich schwer, ihn zu nutzen, aber ich muss sagen, es ist eine spannende Alternative für Dispatchers.IO. Du wirst es jedoch wahrscheinlich in der Zukunft nicht benötigen, da das Kotlin Coroutines-Team seine Bereitschaft ausdrückt, standardmäßig virtuelle Threads zu verwenden, sobald Project Loom stabil ist. Ich hoffe, das passiert bald.
Unbeschränkter Dispatcher
Der letzte Dispatcher, über den wir sprechen müssen, ist Dispatchers.Unconfined. Dieser Dispatcher unterscheidet sich vom vorherigen, da er keine Threads ändert. Wenn er gestartet wird, läuft er auf dem Thread, auf dem er gestartet wurde. Wenn er wiederaufgenommen wird, läuft er auf dem Thread, der ihn wiederaufgenommen hat.
Dies ist manchmal nützlich für Unit-Tests. Stellen Sie sich vor, Sie müssen eine Funktion testen, die launch aufruft. Die Synchronisation der Abläufe ist vielleicht nicht einfach. Eine Lösung besteht darin, Dispatchers.Unconfined anstelle aller anderen Disponenten zu verwenden. Wenn es in allen Bereichen verwendet wird, läuft alles auf demselben Thread und wir können die Reihenfolge der Operationen leichter kontrollieren. Dieser Trick ist nicht notwendig, wenn wir runTest von kotlinx-coroutines-test verwenden. Wir werden dies später im Buch besprechen.
Unter Performance-Gesichtspunkten ist dieser Disponent der kostengünstigste, da er niemals einen Themenwechsel erfordert. Daher könnten wir ihn wählen, wenn es uns völlig egal ist, auf welchem Thread unser Code läuft. In der Praxis ist es jedoch nicht gut, ihn so leichtfertig zu verwenden. Was ist, wenn wir versehentlich einen blockierenden Aufruf verpassen und auf dem Main Thread laufen? Dies könnte dazu führen, dass die gesamte Anwendung blockiert wird.
Unmittelbare Haupt-Dispositions
Mit dem Versand einer Coroutine sind Kosten verbunden. Wenn withContext aufgerufen ist, muss die Coroutine ausgesetzt werden, eventuell in einer Warteschlange warten und dann fortgesetzt werden. Dies ist ein kleiner, aber unnötiger Aufwand, wenn wir bereits auf diesem Thread sind. Betrachten Sie die untenstehende Funktion:

Wenn diese Funktion bereits auf dem Hauptdispatcher aufgerufen worden wäre, würden wir unnötige Kosten für erneutes Dispatching haben. Darüber hinaus, wenn es eine lange Warteschlange für den Hauptthread aufgrund von withContext gibt, könnten die Benutzerdaten mit einer gewissen Verzögerung angezeigt werden (diese Coroutine müsste warten, bis die anderen Coroutinen ihre Arbeit abgeschlossen haben). Um dies zu verhindern, gibt es Dispatchers.Main.immediate, das nur dann dispatcht, wenn es nötig ist. Somit, wenn die untenstehende Funktion im Hauptthread aufgerufen wird, wird sie nicht erneut dispatched, sie wird sofort ausgeführt.
Wir bevorzugen Dispatchers.Main.immediate als das withContext Argument, immer dann, wenn diese Funktion möglicherweise bereits vom Haupt-Dispatcher aufgerufen wurde. Derzeit unterstützen die anderen Verteiler kein sofortiges Dispatching.
Fortsetzungsabfänger (Continuation Interceptor)
Das Dispatching basiert auf dem Mechanismus des Fortsetzungsabfangens, der in die Kotlin-Sprache integriert ist. Es gibt einen Coroutine-Kontext namens ContinuationInterceptor, dessen interceptContinuation Methode verwendet wird, um eine Fortsetzung zu modifizieren, wenn eine Coroutine ausgesetzt wird3. Er besitzt auch eine releaseInterceptedContinuation Methode, die aufgerufen wird, wenn eine Fortsetzung beendet wird.
Die Fähigkeit, eine Kontinuität einzukleiden, bietet viel Kontrolle. Dispatcher nutzen interceptContinuation, um eine DispatchedContinuation um eine Kontinuität zu legen, die auf einem spezifischen Pool von Threads läuft. So funktionieren Dispatcher.
Das Problem ist, dass der gleiche Kontext auch von vielen Testbibliotheken verwendet wird, beispielsweise von runTest aus kotlinx-coroutines-test. Jedes Element in einem Kontext muss einen eindeutigen Schlüssel haben. Deswegen injizieren wir manchmal Dispatcher, um sie in Unit-Tests durch Test-Dispatcher zu ersetzen. Wir werden auf dieses Thema zurückkommen in dem Kapitel, das sich mit Coroutine-Testing befasst.
Leistung von Dispatchern gegen unterschiedliche Aufgaben
Um zu zeigen, wie verschiedene Dispatcher gegen unterschiedliche Aufgaben abschneiden, habe ich einige Benchmarks erstellt. In all diesen Fällen ist die Aufgabe, 100 unabhängige Coroutinen mit derselben Aufgabe auszuführen. Verschiedene Spalten stellen verschiedene Aufgaben dar: Unterbrechung für eine Sekunde, Sperren für eine Sekunde, CPU-intensive Operation und speicherintensive Operation (wo die meiste Zeit mit Zugriff, Zuweisung und Freigabe von Speicher verbracht wird). Verschiedene Zeilen stellen die verschiedenen Dispatcher dar, die zum Ausführen dieser Coroutinen verwendet wurden. Die folgende Tabelle zeigt die durchschnittliche Ausführungszeit in Millisekunden.
| Unterbrechung | Sperren | CPU | Speicher | |
|---|---|---|---|---|
| Einzelner Thread | 1 002 | 100 003 | 39 103 | 94 358 |
| Standard (8 Threads) | 1 002 | 13 003 | 8 473 | 21 461 |
| IO (64 Threads) | 1 002 | 2 003 | 9 893 | 20 776 |
| 100 Threads | 1 002 | 1 003 | 16 379 | 21 004 |
Es gibt ein paar wichtige Beobachtungen, die Sie machen können:
- Wenn wir nur unterbrechen, spielt es wirklich keine Rolle, wie viele Threads wir verwenden.
- Wenn wir sperren, werden alle diese Coroutinen umso schneller fertig, je mehr Threads wir verwenden.
- Bei CPU-intensiven Operationen ist
Dispatchers.Defaultdie beste Option2. - Wenn wir ein speicherintensives Problem haben, könnten mehr Threads eine (aber keine signifikante) Verbesserung bieten.
So sehen die getesteten Funktionen aus1:
Zusammenfassung
Ablaufsteuerprogramme (Dispatcher) bestimmen, auf welchem Thread oder Thread-Pool eine Coroutine startet und fortgesetzt wird. Die wichtigsten Optionen sind:
Dispatchers.Default, den wir für CPU-intensive Operationen nutzen;Dispatchers.Main, mit welchem wir auf den Hauptthread auf Android, Swing, oder JavaFX zugreifen;Dispatchers.Main.immediate, der auf demselben Thread wieDispatchers.Mainläuft, jedoch nicht erneut versendet wird, wenn es nicht notwendig ist;Dispatchers.IO, den wir einsetzen, wenn wir einige blockierende Operationen ausführen müssen;Dispatchers.IOmit begrenzter Parallelität oder ein benutzerdefinierter Ablaufsteuerer (Dispatcher) mit einem Thread-Pool, den wir bei einer großen Anzahl an blockierenden Aufrufen verwenden;Dispatchers.DefaultoderDispatchers.IOmit auf 1 begrenzter Parallelität oder ein benutzerdefinierter Ablaufsteuerer (Dispatcher) mit einem einzigen Thread, der zum Schutz von gemeinsamen Zustandsänderungen eingesetzt wird;Dispatchers.Unconfined, den wir nutzen, wenn der Ausführungsort der Coroutine irrelevant ist.
Den ganzen Code finden Sie unter https://bit.ly/3vqMpYf.
Der Hauptgrund ist, dass je mehr Threads wir nutzen, desto mehr Zeit muss der Prozessor für den Wechsel zwischen diesen aufwenden, wodurch weniger Zeit für sinnvolle Operationen bleibt. Zudem sollte Dispatchers.IO nicht für CPU-intensive Operationen genutzt werden, da dieser zur Blockierung von Operationen eingesetzt wird und ein anderer Prozess alle seine Threads blockieren könnte.
Dank des Caching-Mechanismus muss das Verpacken nur einmal pro Fortsetzung erfolgen.
Dieser Mechanismus ist nicht deterministisch.
Wir werden dies im Kapitel Testen von Kotlin Coroutines besprechen.
Die Lösung wurde von dem Artikel Running Kotlin coroutines on Project Loom's virtual threads von Jan Vladimir Mostert inspiriert.
