


Warum Kotlin Coroutines verwenden?
Dies ist ein übersetztes Kapitel aus dem Buc Kotlin Coroutines. Wenn Sie mir helfen möchten, die Übersetzung zu verbessern, finden Sie die Quellen auf GitHub.
Warum müssen wir Kotlin Coroutines lernen? Wir haben bereits gut etablierte JVM-Bibliotheken wie RxJava oder Reactor. Darüber hinaus unterstützt Java selbst Multithreading, während viele Leute einfach alte Callbacks bevorzugen. Offensichtlich haben wir bereits viele Optionen für asynchrone Operationen.
Kotlin Coroutines bieten jedoch sehr viel mehr. Sie sind eine Implementierung eines Konzepts, das erstmals 19631 beschrieben wurde, aber viele Jahre auf eine angemessene industrielle Umsetzung2 gewartet hat. Kotlin Coroutines verbinden die leistungsstarken Fähigkeiten, die in halb Jahrhundert alten Arbeiten präsentiert wurden, mit einer Bibliothek, die perfekt für praktische Anwendungsfälle geeignet ist. Darüber hinaus sind Kotlin Coroutines multiplattformfähig, was bedeutet, dass sie auf allen Kotlin-Plattformen (wie JVM, JS, iOS und auch in den gemeinsamen Modulen) eingesetzt werden können. Schließlich verändern sie die Code-Struktur nicht drastisch. Wir können die meisten Fähigkeiten von Kotlin Coroutines fast mühelos nutzen (was wir von RxJava oder Callbacks nicht behaupten können). Das macht sie anfängerfreundlich3.
Lassen wir dies in der Praxis betrachten. Wir werden erforschen, wie verschiedene gängige Anwendungsfälle durch Coroutines und andere bekannte Ansätze gelöst werden. Ich werde zwei typische Anwendungsfälle vorstellen: Android und die Implementierung der Backend-Systemlogik. Beginnen wir mit der ersten.
Coroutines auf Android (und anderen Frontend-Plattformen)
Wenn Sie die Anwendungslogik auf dem Frontend implementieren, müssen Sie in der Regel:
- Daten von einer oder mehreren Quellen abrufen (API, Ansichtselement, Datenbank, Einstellungen, eine andere Anwendung);
- Diese Daten verarbeiten;
- Verwenden Sie diese Daten (zeigen Sie sie in der Ansicht an, speichern Sie sie in einer Datenbank, senden Sie sie an eine API).
Um unsere Diskussion praxisnaher zu gestalten, gehen wir zunächst davon aus, dass wir eine Android-Anwendung entwickeln. Wir beginnen mit einer Situation, in der wir Nachrichten von einer API abrufen, sortieren und auf dem Bildschirm anzeigen müssen. Dies ist eine direkte Darstellung dessen, was unsere Funktion tun soll:
Leider ist dies nicht so leicht zu bewerkstelligen. In Android hat jede Anwendung nur einen Thread, der die Benutzeroberfläche modifizieren kann. Dieser Thread ist sehr wichtig und sollte niemals blockiert werden. Aus diesem Grund kann die Funktion oben nicht auf diese Weise umgesetzt werden. Wenn er im Hauptthread gestartet würde, würde getNewsFromApi diesen blockieren und unsere Anwendung würde abstürzen. Wenn wir ihn auf einem anderen Thread starten würden, würde unsere Anwendung abstürzen, sobald wir showNews aufrufen, da dieser im Hauptthread laufen muss.
Thread-Switching
Diese Probleme könnten wir durch Thread-Switching lösen. Erst auf einen Thread, der blockiert werden kann, und dann zurück zum Hauptthread.
Solcher Threadwechsel kann noch in einigen Anwendungen gefunden werden, ist jedoch aus mehreren Gründen als problematisch bekannt:

- Hier existiert kein Mechanismus, diese Threads abzubrechen, daher treten wir oft Speicherlecks auf.
- Es ist kostspielig, so viele Threads zu erstellen.
- Häufiges Wechseln von Threads ist verwirrend und schwer zu handhaben.
- Der Code wird unnötigerweise größer und komplizierter.
Um diese Probleme deutlich zu sehen, stellen Sie sich folgende Situation vor: Sie öffnen und schließen schnell eine Ansicht. Beim Öffnen könnten Sie mehrere Threads gestartet haben, die Daten abrufen und verarbeiten. Ohne sie abzubrechen, werden sie immer noch ihre Arbeit tun und versuchen, eine Ansicht zu ändern, die nicht mehr existiert. Das bedeutet unnötige Arbeit für Ihr Gerät, mögliche Ausnahmefehler im Hintergrund und wer weiß, welche anderen unerwarteten Ergebnisse.
Angesichts dieser Probleme suchen wir nach einer besseren Lösung.
Callbacks
Callbacks sind ein weiteres Muster, das zur Lösung unserer Probleme angewendet werden könnte. Die Idee ist, dass wir unsere Funktionen nicht blockieren, aber ihnen eine Funktion übergeben, die ausgeführt werden soll, sobald der von der Callback-Funktion gestartete Prozess beendet ist. So könnte unsere Funktion aussehen, wenn wir dieses Muster anwenden:
Bitte beachten Sie, dass diese Implementierung keine Stornierung unterstützt. Wir könnten Rückruffunktionen implementieren, die stornierbar sind, aber es ist nicht einfach. Nicht nur muss jede Rückruffunktion speziell für die Stornierung implementiert werden, sondern um sie zu stornieren, müssen wir alle Objekte separat erfassen.
Die Callback-Architektur löst dieses einfache Problem, aber sie hat viele Nachteile. Um diese zu erforschen, diskutieren wir einen komplexeren Fall, in dem wir Daten von drei Endpunkten abrufen müssen:
Dieser Code ist weit entfernt von perfekt aus mehreren Gründen:
- Das Holen von Nachrichten und Benutzerdaten könnte parallelisiert werden, aber unsere aktuelle Callback-Architektur unterstützt dies nicht (es wäre schwierig, dies mit Callbacks zu erreichen).
- Wie bereits erwähnt, würde die Unterstützung von Stornierungen viel zusätzlichen Aufwand erfordern.
- Die zunehmende Anzahl von Verschachtelungen macht diesen Code schwer zu lesen (Code mit mehreren Callbacks wird oft als sehr unleserlich angesehen). Eine solche Situation wird "callback hell" genannt, die man besonders in einigen älteren Node.JS-Projekten finden kann:

- Wenn wir Callbacks verwenden, ist es schwer zu kontrollieren, was nach was passiert. Die folgende Art und Weise, einen Fortschrittsindikator anzuzeigen, wird nicht funktionieren:
Der Fortschrittsbalken wird gleich nach dem Beginnen des Prozesses zum Anzeigen von Nachrichten ausgeblendet, praktisch unmittelbar nach seiner Darstellung. Damit dies funktioniert, müssten wir showNews auch zu einer Callback-Funktion machen.
Deshalb ist die Callback-Architektur für nicht-triviale Fälle alles andere als perfekt. Werfen wir einen Blick auf einen anderen Ansatz: RxJava und andere reaktive Ströme.
RxJava und andere reaktive Ströme
Ein alternativer Ansatz, der in Java (sowohl in Android als auch im Backend) beliebt ist, ist die Verwendung von reaktiven Strömen (oder Reactive Extensions): RxJava oder sein Nachfolger Reactor. Mit diesem Ansatz finden alle Operationen im Rahmen eines Datenflusses statt, der gestartet, verarbeitet und beobachtet werden kann. Diese Ströme unterstützen Thread-Umschaltung und gleichzeitige Verarbeitung, daher werden sie oft eingesetzt, um die Verarbeitung in Anwendungen zu parallelisieren.
So könnten wir unser Problem unter Verwendung von RxJava lösen:
Die
Einweg-Objekteim obigen Beispiel sind erforderlich, um diesen Stream abzubrechen, wenn (zum Beispiel) der Benutzer den Bildschirm verlässt.
Dies ist definitiv eine bessere Lösung als Callbacks: keine Speicherlecks, Stornierung ist möglich, richtige Nutzung von Threads. Das einzige Problem ist, dass es schwierig ist. Wenn Sie es mit dem "idealen" Code vom Anfang vergleichen (auch unten gezeigt), werden Sie merken, dass sie kaum etwas gemeinsam haben.
All diese Funktionen, wie subscribeOn, observeOn, map oder subscribe, müssen erlernt werden. Das Abbrechen muss explizit erfolgen. Funktionen müssen Objekte zurückgeben, die in den Klassen Observable oder Single verpackt sind. In der Praxis, wenn wir RxJava einführen, müssen wir unseren Code umfassend neu organisieren.
Betrachten Sie das zweite Problem, für das wir drei Endpunkte anrufen müssen, bevor wir die Daten anzeigen können. Dies kann effektiv mit RxJava gelöst werden, jedoch ist es komplizierter.
Dieser Code ist wirklich nebenläufig und hat keine Speicherlecks, aber wir müssen RxJava-Funktionen wie zip und flatMap einführen, einen Wert in Pair einpacken und ihn destrukturieren. Dies ist eine korrekte Implementierung, aber sie ist ziemlich kompliziert. Schauen wir uns also abschließend an, was Coroutinen uns bieten können.
Einsatz von Kotlin Coroutines
Die Hauptfunktionalität, die Kotlin Coroutines einführen, ist die Fähigkeit, eine Coroutine an einem bestimmten Punkt zu suspendieren und sie in der Zukunft fortzusetzen. Dank dessen könnten wir unseren Code auf dem Hauptthread ausführen und ihn suspendieren, wenn wir Daten von einer API anfordern. Wenn eine Coroutine suspendiert wird, wird der Thread nicht blockiert und kann weiterhin genutzt werden, das heißt, er kann verwendet werden, um die Ansicht zu ändern oder andere Coroutines auszuführen. Sobald die Daten bereit sind, wartet die Coroutine auf den Hauptthread (dies ist eine seltene Situation, aber es könnte eine Warteschlange von Coroutines darauf warten); sobald die Coroutine den Thread bekommt, kann sie ab dem Punkt fortsetzen, an dem sie suspendiert wurde.
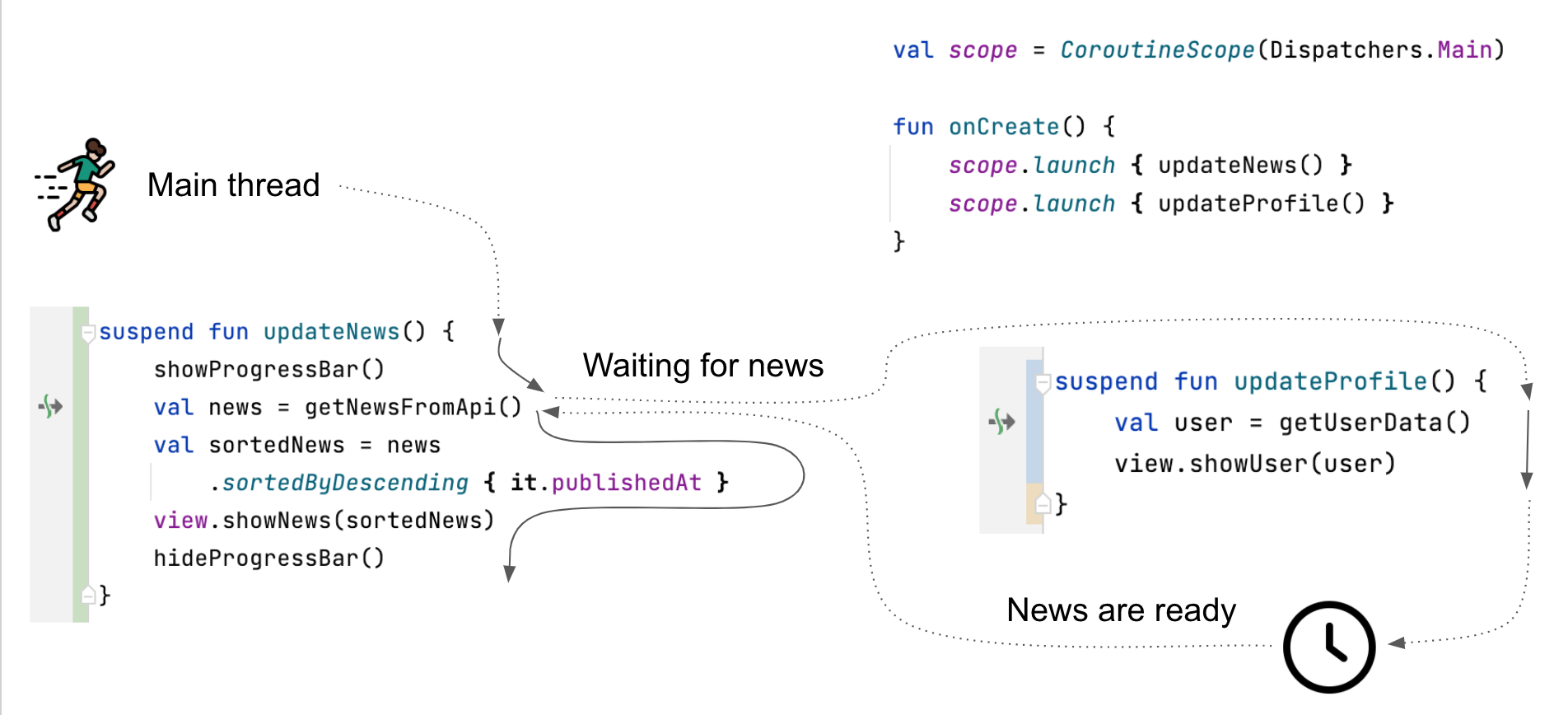
updateNews und updateProfile Funktionen, die auf dem Hauptthread in separaten Coroutines laufen. Sie können dies abwechselnd tun, weil sie ihre Coroutines suspendieren anstatt den Thread zu blockieren. Wenn die updateNews Funktion auf eine Netzwerkantwort wartet, wird der Hauptthread von updateProfile genutzt. Hier wird angenommen, dass getUserData nicht suspendiert wurde, weil die Benutzerdaten bereits gespeichert waren, daher kann sie bis zu ihrem Abschluss ausgeführt werden. Die Netzwerkantwort kam nicht rechtzeitig an, daher wird der Hauptthread zu diesem Zeitpunkt nicht genutzt (er kann von anderen Funktionen genutzt werden). Sobald die Daten erscheinen, greifen wir auf den Hauptthread zu und verwenden ihn, um die updateNews Funktion fortzusetzen, ab dem Punkt direkt nach getNewsFromApi().
Per Definition sind Coroutines Komponenten, die suspendiert und fortgesetzt werden können. Konzepte wie async/await und Generatoren, die in Sprachen wie JavaScript, Rust oder Python zu finden sind, verwenden auch Coroutines, aber ihre Fähigkeiten sind sehr begrenzt.
So könnte unser erstes Problem durch die Verwendung von Kotlin Coroutines auf folgende Weise gelöst werden:
Im obigen Code wurde
viewModelScopeverwendet, das derzeit auf Android recht verbreitet ist. Alternativ könnten wir einen benutzerdefinierten Scope verwenden. Beide Optionen werden wir später diskutieren.
Dieser Code entspricht fast genau dem, was wir von Anfang an wollten! In dieser Lösung läuft der Code auf dem Hauptthread, blockiert ihn jedoch niemals. Dank des Unterbrechungsmechanismus unterbrechen wir (anstatt zu blockieren) die Coroutine, wenn wir auf Daten warten müssen. Wenn die Coroutine unterbrochen ist, kann der Hauptthread weiterhin andere Aufgaben erledigen, wie zum Beispiel eine schöne Fortschrittsbalken-Animation zeichnen. Sobald die Daten verfügbar sind, setzt unsere Coroutine den Hauptthread fort und fährt fort, wo sie zuvor unterbrochen wurde.
Wie sieht es mit dem anderen Problem mit den drei Anrufen aus? Es könnte auf ähnliche Weise gelöst werden:
Diese Lösung sieht gut aus, aber ihre Funktionsweise ist nicht optimal. Diese Aufrufe werden sequenziell erfolgen (einer nach dem anderen), also wenn jeder von ihnen 1 Sekunde in Anspruch nimmt, dauert die gesamte Funktion 3 Sekunden anstatt 2 Sekunden, die wir erzielen könnten, wenn die API-Aufrufe parallel ausgeführt werden. Hier kommt die Kotlin Coroutines-Bibliothek ins Spiel mit Funktionen wie async, um eine andere Coroutine sofort mit einer Anfrage zu starten und auf dessen Ergebnis später zu warten (mit der await Funktion).
Dieser Code ist einfach und lesbar. Er nutzt das beliebte async/await-Muster, das auch in anderen Sprachen wie JavaScript oder C# verwendet wird. Zudem ist er effizient und führt nicht zu Speicherlecks. Die Implementierung des Codes ist einfach und gut durchgeführt.
Mit Kotlin Coroutinen ist es uns möglich, verschiedene Anwendungsfälle problemlos umzusetzen und andere Funktionen von Kotlin zu nutzen. So können wir beispielsweise For-Schleifen oder Sammlungsverarbeitungsfunktionen einsetzen. Hier unten sehen Sie, wie die nächsten Seiten entweder parallel oder nacheinander heruntergeladen werden.
Coroutines im Backend
Meiner Meinung nach ist der größte Vorteil der Verwendung von Coroutines im Backend die Einfachheit. Im Gegensatz zu RxJava verändert der Einsatz von Coroutines kaum, wie unser Code aussieht. In den meisten Fällen beinhaltet die Migration von Threads zu Coroutines nur das Hinzufügen des suspend Modifiers. Wenn wir dies tun, können wir leicht Nebenläufigkeit einführen, nebenläufiges Verhalten testen, Coroutines abbrechen und alle anderen mächtigen Funktionen verwenden, die wir in diesem Buch untersuchen werden.

Neben all diesen Funktionen gibt es noch einen weiteren wichtigen Grund, Coroutinen zu verwenden: Threads sind ressourcenintensiv. Sie müssen erstellt, gepflegt und ihr Speicher zugewiesen werden4. Wenn Ihre Anwendung von Millionen von Nutzern verwendet wird und Sie jedes Mal blockiert werden, wenn Sie auf eine Antwort von einer Datenbank oder einem anderen Dienst warten, führt dies zu erheblichen Belastungen von Speicher und Prozessornutzung (für die Erstellung, Wartung und Synchronisation dieser Threads).
Dieses Problem kann mit den folgenden Codeausschnitten visualisiert werden, die einen Backend-Dienst mit 100.000 Nutzern simulieren, die nach Daten fragen. Der erste Ausschnitt startet 100.000 Threads und lässt sie für eine Sekunde schlafen (um das Warten auf eine Antwort von einer Datenbank oder einem anderen Dienst zu simulieren). Wenn Sie es auf Ihrem Computer ausführen, werden Sie sehen, dass es eine Weile dauert, all diese Punkte auszudrucken, oder es wird durch eine OutOfMemoryError-Ausnahme unterbrochen. Das ist der Aufwand, um so viele Threads laufen zu lassen. Der zweite Ausschnitt verwendet stattdessen Coroutinen anstelle von Threads und setzt sie aus, anstatt sie schlafen zu lassen. Wenn Sie es ausführen, wird das Programm für eine Sekunde warten und dann alle Punkte ausdrucken. Der Aufwand, all diese Coroutinen zu starten, ist so gering, dass er kaum bemerkbar ist.
Schlussfolgerung
Ich hoffe, Sie fühlen sich nun überzeugt, mehr über Kotlin Coroutines lernen zu wollen. Sie sind viel mehr als nur eine Bibliothek und machen die gleichzeitige Programmierung mit modernen Werkzeugen so einfach wie möglich. Wenn wir das geklärt haben, fangen wir an zu lernen. Für den Rest dieses Kapitels werden wir untersuchen, wie das Anhalten funktioniert: zuerst aus der Sicht der Anwendung, dann hinter den Kulissen.
Conway, Melvin E. (Juli 1963). "Design of a Separable Transition-diagram Compiler". Communications of the ACM. ACM. 6 (7): 396–408. doi:10.1145/366663.366704. ISSN 0001-0782. S2CID 10559786
Ich glaube, dass die ersten industrietauglichen und universellen Coroutines 2009 von Go eingeführt wurden. Es ist jedoch erwähnenswert, dass Coroutines auch in einigen älteren Sprachen wie Lisp implementiert wurden, aber sie wurden nicht populär. Ich glaube, das liegt daran, dass ihre Implementierung nicht dafür ausgelegt war, reale Fälle zu unterstützen. Lisp (genauso wie Haskell) wurde eher als Spielwiese für Wissenschaftler behandelt als als Sprache für Profis.
Das ändert nichts an der Tatsache, dass wir Coroutines verstehen sollten, um sie gut verwenden zu können.
Meistens ist die Standardgröße des Thread-Stack 1 MB. Aufgrund von Java-Optimierungen bedeutet dies nicht unbedingt, dass 1 MB mal die Anzahl der Threads verwendet wird, aber viel zusätzlicher Speicher wird einfach deshalb verbraucht, weil wir Threads erstellen.
